 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabAgent: A Framework for Replacing Agentic Generative Components with Tabular-Textual Classifiers
Feb 18, 2026Agentic systems, AI architectures that autonomously execute multi-step workflows to achieve complex goals, are often built using repeated large language model (LLM) calls for closed-set decision tasks such as routing, shortlisting, gating, and verification. While convenient, this design makes deployments slow and expensive due to cumulative latency and token usage. We propose TabAgent, a framework for replacing generative decision components in closed-set selection tasks with a compact textual-tabular classifier trained on execution traces. TabAgent (i) extracts structured schema, state, and dependency features from trajectories (TabSchema), (ii) augments coverage with schema-aligned synthetic supervision (TabSynth), and (iii) scores candidates with a lightweight classifier (TabHead). On the long-horizon AppWorld benchmark, TabAgent maintains task-level success while eliminating shortlist-time LLM calls, reducing latency by approximately 95% and inference cost by 85-91%. Beyond tool shortlisting, TabAgent generalizes to other agentic decision heads, establishing a paradigm for learned discriminative replacements of generative bottlenecks in production agent architectures.
Textual Planning with Explicit Latent Transitions
Feb 04, 2026Planning with LLMs is bottlenecked by token-by-token generation and repeated full forward passes, making multi-step lookahead and rollout-based search expensive in latency and compute. We propose EmbedPlan, which replaces autoregressive next-state generation with a lightweight transition model operating in a frozen language embedding space. EmbedPlan encodes natural language state and action descriptions into vectors, predicts the next-state embedding, and retrieves the next state by nearest-neighbor similarity, enabling fast planning computation without fine-tuning the encoder. We evaluate next-state prediction across nine classical planning domains using six evaluation protocols of increasing difficulty: interpolation, plan-variant, extrapolation, multi-domain, cross-domain, and leave-one-out. Results show near-perfect interpolation performance but a sharp degradation when generalization requires transfer to unseen problems or unseen domains; plan-variant evaluation indicates generalization to alternative plans rather than memorizing seen trajectories. Overall, frozen embeddings support within-domain dynamics learning after observing a domain's transitions, while transfer across domain boundaries remains a bottleneck.
Unsupervised Translation of Emergent Communication
Feb 11, 2025Emergent Communication (EC) provides a unique window into the language systems that emerge autonomously when agents are trained to jointly achieve shared goals. However, it is difficult to interpret EC and evaluate its relationship with natural languages (NL). This study employs unsupervised neural machine translation (UNMT) techniques to decipher ECs formed during referential games with varying task complexities, influenced by the semantic diversity of the environment. Our findings demonstrate UNMT's potential to translate EC, illustrating that task complexity characterized by semantic diversity enhances EC translatability, while higher task complexity with constrained semantic variability exhibits pragmatic EC, which, although challenging to interpret, remains suitable for translation. This research marks the first attempt, to our knowledge, to translate EC without the aid of parallel data.
ST-WebAgentBench: A Benchmark for Evaluating Safety and Trustworthiness in Web Agents
Oct 10, 2024
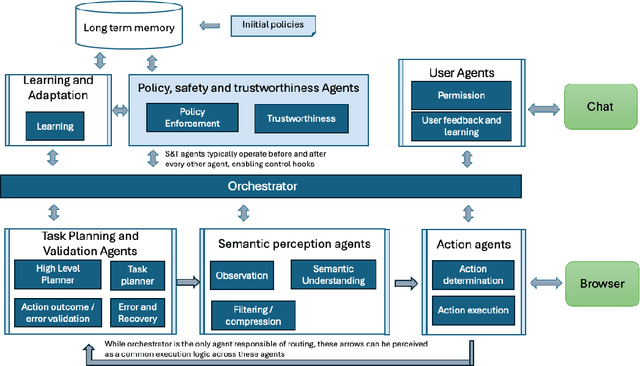


Recent advancements in LLM-based web agents have introduced novel architectures and benchmarks showcasing progress in autonomous web navigation and interaction. However, most existing benchmarks prioritize effectiveness and accuracy, overlooking crucial factors like safety and trustworthiness which are essential for deploying web agents in enterprise settings. The risks of unsafe web agent behavior, such as accidentally deleting user accounts or performing unintended actions in critical business operations, pose significant barriers to widespread adoption. In this paper, we present ST-WebAgentBench, a new online benchmark specifically designed to evaluate the safety and trustworthiness of web agents in enterprise contexts. This benchmark is grounded in a detailed framework that defines safe and trustworthy (ST) agent behavior, outlines how ST policies should be structured and introduces the Completion under Policies metric to assess agent performance. Our evaluation reveals that current SOTA agents struggle with policy adherence and cannot yet be relied upon for critical business applications. Additionally, we propose architectural principles aimed at improving policy awareness and compliance in web agents. We open-source this benchmark and invite the community to contribute, with the goal of fostering a new generation of safer, more trustworthy AI agents. All code, data, environment reproduction resources, and video demonstrations are available at https://sites.google.com/view/st-webagentbench/home.
From Grounding to Planning: Benchmarking Bottlenecks in Web Agents
Sep 03, 2024



General web-based agents are increasingly essential for interacting with complex web environments, yet their performance in real-world web applications remains poor, yielding extremely low accuracy even with state-of-the-art frontier models. We observe that these agents can be decomposed into two primary components: Planning and Grounding. Yet, most existing research treats these agents as black boxes, focusing on end-to-end evaluations which hinder meaningful improvements. We sharpen the distinction between the planning and grounding components and conduct a novel analysis by refining experiments on the Mind2Web dataset. Our work proposes a new benchmark for each of the components separately, identifying the bottlenecks and pain points that limit agent performance. Contrary to prevalent assumptions, our findings suggest that grounding is not a significant bottleneck and can be effectively addressed with current techniques. Instead, the primary challenge lies in the planning component, which is the main source of performance degradation. Through this analysis, we offer new insights and demonstrate practical suggestions for improving the capabilities of web agents, paving the way for more reliable agents.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024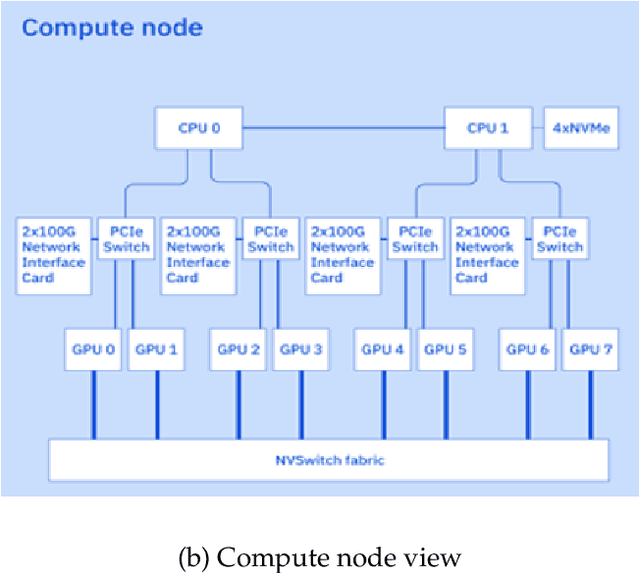
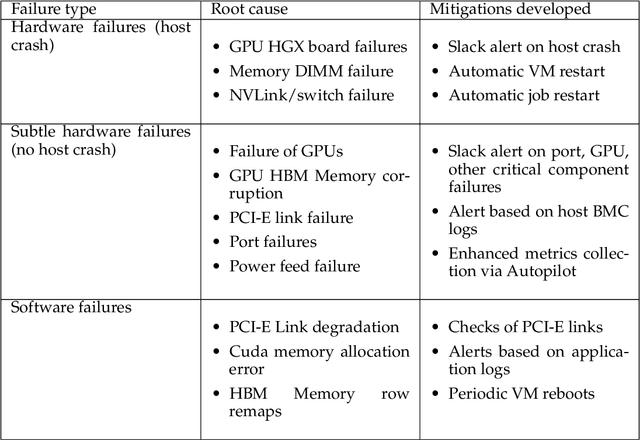
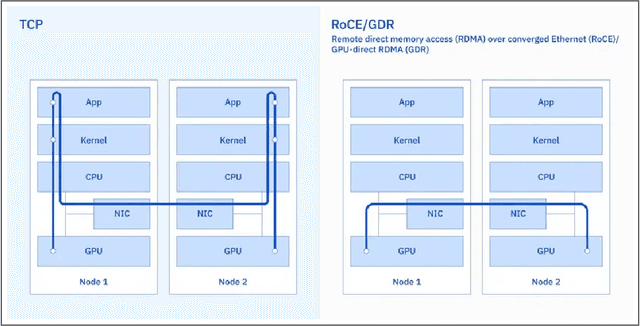
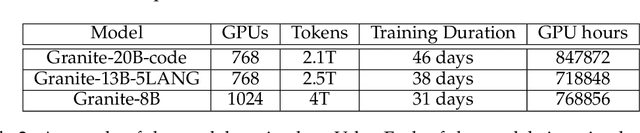
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.