 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Expressivity of Selective State-Space Layers: A Multivariate Polynomial Approach
Feb 04, 2025



Recent advances in efficient sequence modeling have introduced selective state-space layers, a key component of the Mamba architecture, which have demonstrated remarkable success in a wide range of NLP and vision tasks. While Mamba's empirical performance has matched or surpassed SoTA transformers on such diverse benchmarks, the theoretical foundations underlying its powerful representational capabilities remain less explored. In this work, we investigate the expressivity of selective state-space layers using multivariate polynomials, and prove that they surpass linear transformers in expressiveness. Consequently, our findings reveal that Mamba offers superior representational power over linear attention-based models for long sequences, while not sacrificing their generalization. Our theoretical insights are validated by a comprehensive set of empirical experiments on various datasets.
From Grounding to Planning: Benchmarking Bottlenecks in Web Agents
Sep 03, 2024



General web-based agents are increasingly essential for interacting with complex web environments, yet their performance in real-world web applications remains poor, yielding extremely low accuracy even with state-of-the-art frontier models. We observe that these agents can be decomposed into two primary components: Planning and Grounding. Yet, most existing research treats these agents as black boxes, focusing on end-to-end evaluations which hinder meaningful improvements. We sharpen the distinction between the planning and grounding components and conduct a novel analysis by refining experiments on the Mind2Web dataset. Our work proposes a new benchmark for each of the components separately, identifying the bottlenecks and pain points that limit agent performance. Contrary to prevalent assumptions, our findings suggest that grounding is not a significant bottleneck and can be effectively addressed with current techniques. Instead, the primary challenge lies in the planning component, which is the main source of performance degradation. Through this analysis, we offer new insights and demonstrate practical suggestions for improving the capabilities of web agents, paving the way for more reliable agents.
Intelligence Analysis of Language Models
Jul 20, 2024In this project, we test the effectiveness of Large Language Models (LLMs) on the Abstraction and Reasoning Corpus (ARC) dataset. This dataset serves as a representative benchmark for testing abstract reasoning abilities, requiring a fundamental understanding of key concepts such as object identification, basic counting, and elementary geometric principles. Tasks from this dataset are converted into a prompt-based format for evaluation. Initially, we assess the models' potential through a Zero-shot approach. Subsequently, we investigate the application of the Chain-of-Thought (CoT) technique, aiming to determine its role in improving model performance. Our results suggest that, despite the high expectations placed on contemporary LLMs, these models still struggle in non-linguistic domains, even when dealing with simpler subsets of the ARC dataset. Our study is the first to concentrate on the capabilities of open-source models in this context. The code, dataset, and prompts supporting this project's findings can be found in our GitHub repository, accessible at: https://github.com/Lianga2000/LLMsOnARC.
Norm-based Generalization Bounds for Compositionally Sparse Neural Networks
Jan 28, 2023



In this paper, we investigate the Rademacher complexity of deep sparse neural networks, where each neuron receives a small number of inputs. We prove generalization bounds for multilayered sparse ReLU neural networks, including convolutional neural networks. These bounds differ from previous ones, as they consider the norms of the convolutional filters instead of the norms of the associated Toeplitz matrices, independently of weight sharing between neurons. As we show theoretically, these bounds may be orders of magnitude better than standard norm-based generalization bounds and empirically, they are almost non-vacuous in estimating generalization in various simple classification problems. Taken together, these results suggest that compositional sparsity of the underlying target function is critical to the success of deep neural networks.
On the Implicit Bias Towards Minimal Depth of Deep Neural Networks
Mar 12, 2022
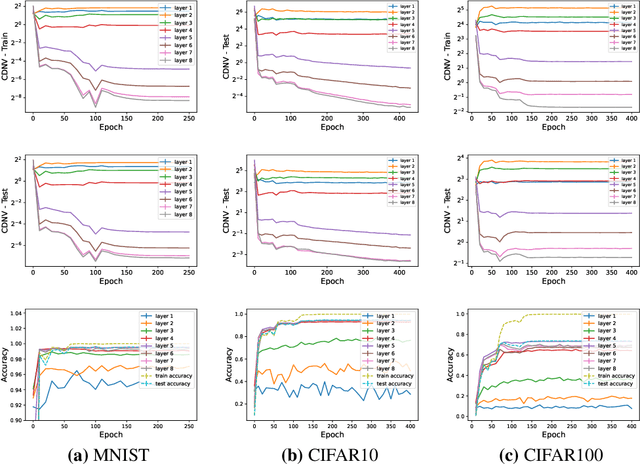
We study the implicit bias of gradient based training methods to favor low-depth solutions when training deep neural networks. Recent results in the literature suggest that penultimate layer representations learned by a classifier over multiple classes exhibit a clustering property, called neural collapse. We demonstrate empirically that the neural collapse property extends beyond the penultimate layer and tends to emerge in intermediate layers as well. In this regards, we hypothesize that gradient based methods are implicitly biased towards selecting neural networks of minimal depth for achieving this clustering property.