 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diffusion Model to Shrink Proteins While Maintaining Their Function
Nov 10, 2025Many proteins useful in modern medicine or bioengineering are challenging to make in the lab, fuse with other proteins in cells, or deliver to tissues in the body, because their sequences are too long. Shortening these sequences typically involves costly, time-consuming experimental campaigns. Ideally, we could instead use modern models of massive databases of sequences from nature to learn how to propose shrunken proteins that resemble sequences found in nature. Unfortunately, these models struggle to efficiently search the combinatorial space of all deletions, and are not trained with inductive biases to learn how to delete. To address this gap, we propose SCISOR, a novel discrete diffusion model that deletes letters from sequences to generate protein samples that resemble those found in nature. To do so, SCISOR trains a de-noiser to reverse a forward noising process that adds random insertions to natural sequences. As a generative model, SCISOR fits evolutionary sequence data competitively with previous large models. In evaluation, SCISOR achieves state-of-the-art predictions of the functional effects of deletions on ProteinGym. Finally, we use the SCISOR de-noiser to shrink long protein sequences, and show that its suggested deletions result in significantly more realistic proteins and more often preserve functional motifs than previous models of evolutionary sequences.
Efficiently Generating Correlated Sample Paths from Multi-step Time Series Foundation Models
Oct 02, 2025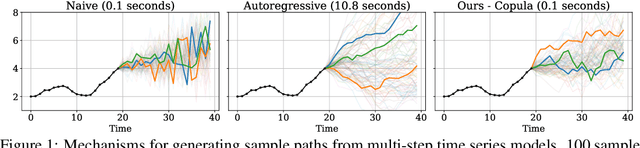
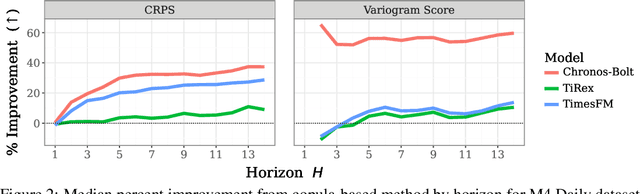
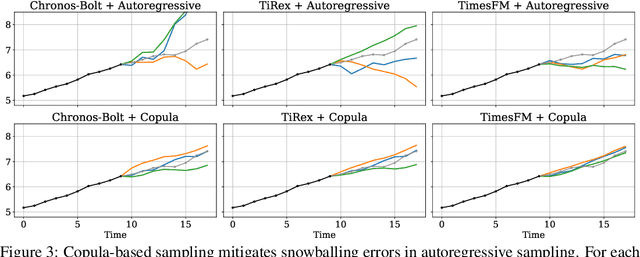
Many time series applications require access to multi-step forecast trajectories in the form of sample paths. Recently, time series foundation models have leveraged multi-step lookahead predictions to improve the quality and efficiency of multi-step forecasts. However, these models only predict independent marginal distributions for each time step, rather than a full joint predictive distribution. To generate forecast sample paths with realistic correlation structures, one typically resorts to autoregressive sampling, which can be extremely expensive. In this paper, we present a copula-based approach to efficiently generate accurate, correlated sample paths from existing multi-step time series foundation models in one forward pass. Our copula-based approach generates correlated sample paths orders of magnitude faster than autoregressive sampling, and it yields improved sample path quality by mitigating the snowballing error phenomenon.
Real Classification by Description: Extending CLIP's Limits of Part Attributes Recognition
Dec 18, 2024



In this study, we define and tackle zero shot "real" classification by description, a novel task that evaluates the ability of Vision-Language Models (VLMs) like CLIP to classify objects based solely on descriptive attributes, excluding object class names. This approach highlights the current limitations of VLMs in understanding intricate object descriptions, pushing these models beyond mere object recognition. To facilitate this exploration, we introduce a new challenge and release description data for six popular fine-grained benchmarks, which omit object names to encourage genuine zero-shot learning within the research community. Additionally, we propose a method to enhance CLIP's attribute detection capabilities through targeted training using ImageNet21k's diverse object categories, paired with rich attribute descriptions generated by large language models. Furthermore, we introduce a modified CLIP architecture that leverages multiple resolutions to improve the detection of fine-grained part attributes. Through these efforts, we broaden the understanding of part-attribute recognition in CLIP, improving its performance in fine-grained classification tasks across six popular benchmarks, as well as in the PACO dataset, a widely used benchmark for object-attribute recognition. Code is available at: https://github.com/ethanbar11/grounding_ge_public.
Boulder2Vec: Modeling Climber Performances in Professional Bouldering Competitions
Nov 04, 2024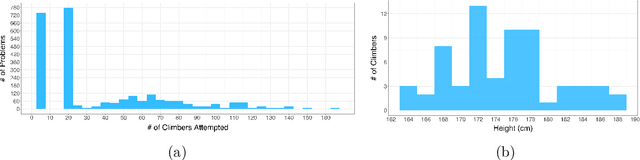
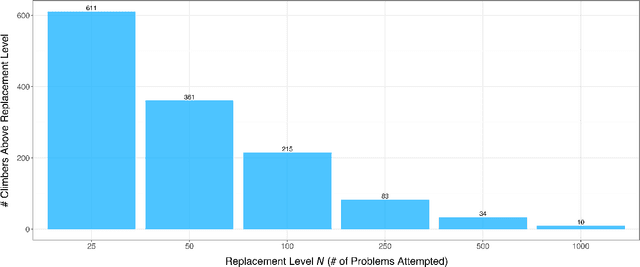
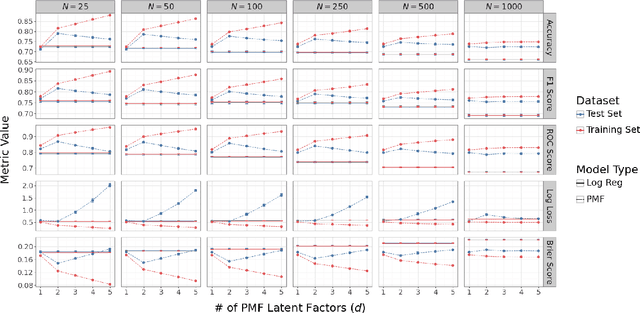

Using data from professional bouldering competitions from 2008 to 2022, we train a logistic regression to predict climber results and measure climber skill. However, this approach is limited, as a single numeric coefficient per climber cannot adequately capture the intricacies of climbers' varying strengths and weaknesses in different boulder problems. For example, some climbers might prefer more static, technical routes while other climbers may specialize in powerful, dynamic problems. To this end, we apply Probabilistic Matrix Factorization (PMF), a framework commonly used in recommender systems, to represent the unique characteristics of climbers and problems with latent, multi-dimensional vectors. In this framework, a climber's performance on a given problem is predicted by taking the dot product of the corresponding climber vector and problem vectors. PMF effectively handles sparse datasets, such as our dataset where only a subset of climbers attempt each particular problem, by extrapolating patterns from similar climbers. We contrast the empirical performance of PMF to the logistic regression approach and investigate the multivariate representations produced by PMF to gain insights into climber characteristics. Our results show that the multivariate PMF representations improve predictive performance of professional bouldering competitions by capturing both the overall strength of climbers and their specialized skill sets.
Multi-Aspect Reviewed-Item Retrieval via LLM Query Decomposition and Aspect Fusion
Aug 01, 2024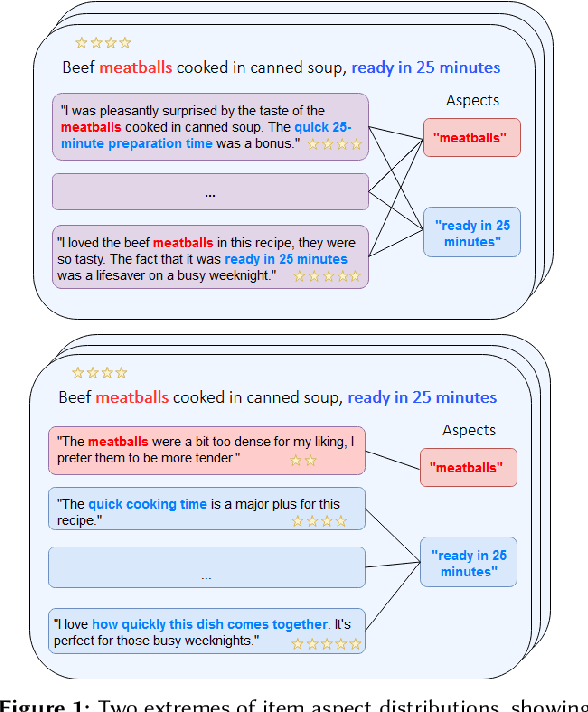
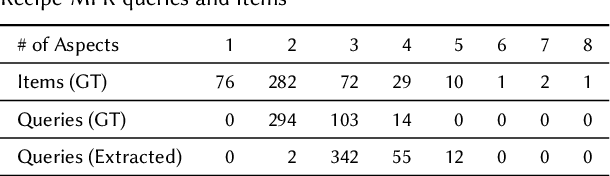
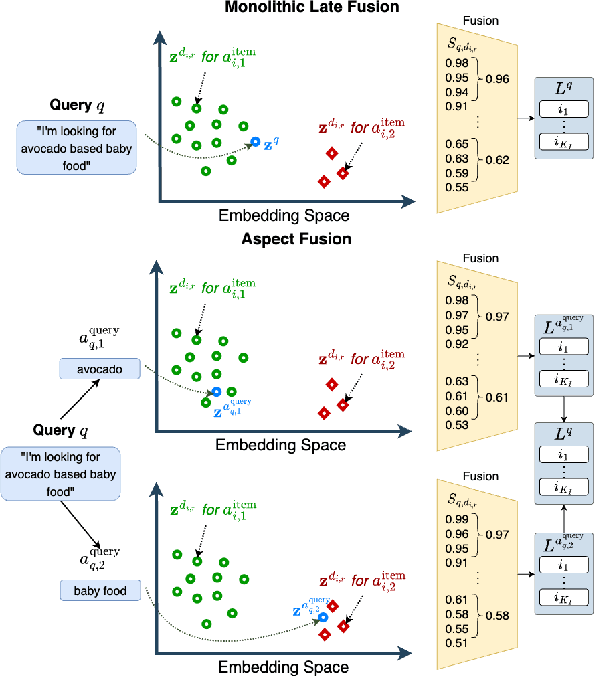
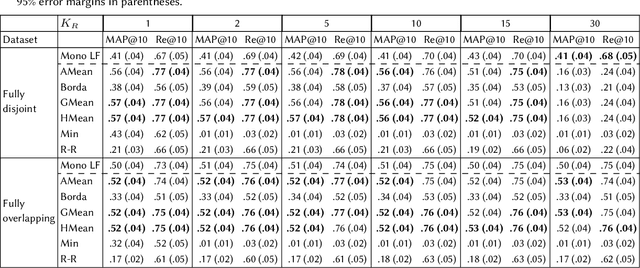
While user-generated product reviews often contain large quantities of information, their utility in addressing natural language product queries has been limited, with a key challenge being the need to aggregate information from multiple low-level sources (reviews) to a higher item level during retrieval. Existing methods for reviewed-item retrieval (RIR) typically take a late fusion (LF) approach which computes query-item scores by simply averaging the top-K query-review similarity scores for an item. However, we demonstrate that for multi-aspect queries and multi-aspect items, LF is highly sensitive to the distribution of aspects covered by reviews in terms of aspect frequency and the degree of aspect separation across reviews. To address these LF failures, we propose several novel aspect fusion (AF) strategies which include Large Language Model (LLM) query extraction and generative reranking. Our experiments show that for imbalanced review corpora, AF can improve over LF by a MAP@10 increase from 0.36 to 0.52, while achieving equivalent performance for balanced review corpora.
Intelligence Analysis of Language Models
Jul 20, 2024In this project, we test the effectiveness of Large Language Models (LLMs) on the Abstraction and Reasoning Corpus (ARC) dataset. This dataset serves as a representative benchmark for testing abstract reasoning abilities, requiring a fundamental understanding of key concepts such as object identification, basic counting, and elementary geometric principles. Tasks from this dataset are converted into a prompt-based format for evaluation. Initially, we assess the models' potential through a Zero-shot approach. Subsequently, we investigate the application of the Chain-of-Thought (CoT) technique, aiming to determine its role in improving model performance. Our results suggest that, despite the high expectations placed on contemporary LLMs, these models still struggle in non-linguistic domains, even when dealing with simpler subsets of the ARC dataset. Our study is the first to concentrate on the capabilities of open-source models in this context. The code, dataset, and prompts supporting this project's findings can be found in our GitHub repository, accessible at: https://github.com/Lianga2000/LLMsOnARC.
A Foundation Model for Soccer
Jul 18, 2024We propose a foundation model for soccer, which is able to predict subsequent actions in a soccer match from a given input sequence of actions. As a proof of concept, we train a transformer architecture on three seasons of data from a professional soccer league. We quantitatively and qualitatively compare the performance of this transformer architecture to two baseline models: a Markov model and a multi-layer perceptron. Additionally, we discuss potential applications of our model. We provide an open-source implementation of our methods at https://github.com/danielhocevar/Foundation-Model-for-Soccer.
2-D SSM: A General Spatial Layer for Visual Transformers
Jun 11, 2023



A central objective in computer vision is to design models with appropriate 2-D inductive bias. Desiderata for 2D inductive bias include two-dimensional position awareness, dynamic spatial locality, and translation and permutation invariance. To address these goals, we leverage an expressive variation of the multidimensional State Space Model (SSM). Our approach introduces efficient parameterization, accelerated computation, and a suitable normalization scheme. Empirically, we observe that incorporating our layer at the beginning of each transformer block of Vision Transformers (ViT) significantly enhances performance for multiple ViT backbones and across datasets. The new layer is effective even with a negligible amount of additional parameters and inference time. Ablation studies and visualizations demonstrate that the layer has a strong 2-D inductive bias. For example, vision transformers equipped with our layer exhibit effective performance even without positional encoding
Bike2Vec: Vector Embedding Representations of Road Cycling Riders and Races
May 17, 2023



Vector embeddings have been successfully applied in several domains to obtain effective representations of non-numeric data which can then be used in various downstream tasks. We present a novel application of vector embeddings in professional road cycling by demonstrating a method to learn representations for riders and races based on historical results. We use unsupervised learning techniques to validate that the resultant embeddings capture interesting features of riders and races. These embeddings could be used for downstream prediction tasks such as early talent identification and race outcome prediction.