 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Sinks and Outlier Features: A 'Catch, Tag, and Release' Mechanism for Embeddings
Feb 02, 2025



Two prominent features of large language models (LLMs) is the presence of large-norm (outlier) features and the tendency for tokens to attend very strongly to a select few tokens. Despite often having no semantic relevance, these select tokens, called attention sinks, along with the large outlier features, have proven important for model performance, compression, and streaming. Consequently, investigating the roles of these phenomena within models and exploring how they might manifest in the model parameters has become an area of active interest. Through an empirical investigation, we demonstrate that attention sinks utilize outlier features to: catch a sequence of tokens, tag the captured tokens by applying a common perturbation, and then release the tokens back into the residual stream, where the tagged tokens are eventually retrieved. We prove that simple tasks, like averaging, necessitate the 'catch, tag, release' mechanism hence explaining why it would arise organically in modern LLMs. Our experiments also show that the creation of attention sinks can be completely captured in the model parameters using low-rank matrices, which has important implications for model compression and substantiates the success of recent approaches that incorporate a low-rank term to offset performance degradation.
Enhancing Knowledge Distillation for LLMs with Response-Priming Prompting
Dec 18, 2024Large language models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing (NLP) tasks. However, these models are often difficult to deploy due to significant computational requirements and resource constraints. Knowledge distillation (KD) is an effective technique for transferring the performance of larger LLMs to smaller models. Traditional KD methods primarily focus on the direct output of the teacher model, with little emphasis on the role of prompting during knowledge transfer. In this paper, we propose a set of novel response-priming prompting strategies applied in the knowledge distillation pipeline to enhance the performance of student models. Our approach fine-tunes a smaller Llama 3.1 8B Instruct model by distilling knowledge from a quantized Llama 3.1 405B Instruct teacher model. We apply LoRA optimization and evaluate on the GSM8K benchmark. Experimental results demonstrate that integrating reasoning-eliciting prompting into the proposed KD pipeline significantly improves student model performance, offering an efficient way to deploy powerful models in resource-constrained environments. We find that Ground Truth prompting results in a 55\% performance increase on GSM8K for a distilled Llama 3.1 8B Instruct compared to the same model distilled without prompting. A thorough investigation into the self-attention layers of the student models indicates that the more successful prompted models tend to exhibit certain positive behaviors inside their attention heads which can be tied to their increased accuracy. Our implementation can be found at https://github.com/alonso130r/knowledge-distillation.
Multi-Aspect Reviewed-Item Retrieval via LLM Query Decomposition and Aspect Fusion
Aug 01, 2024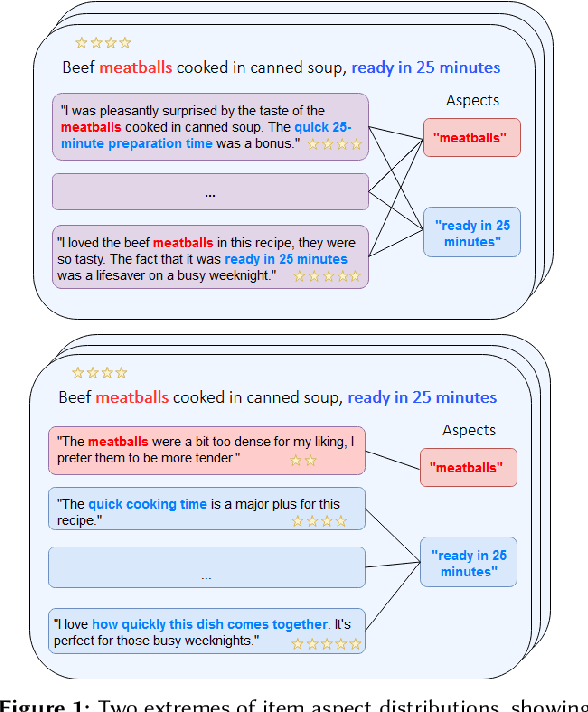
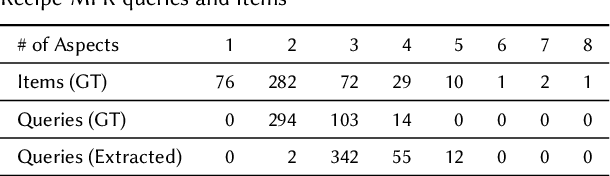
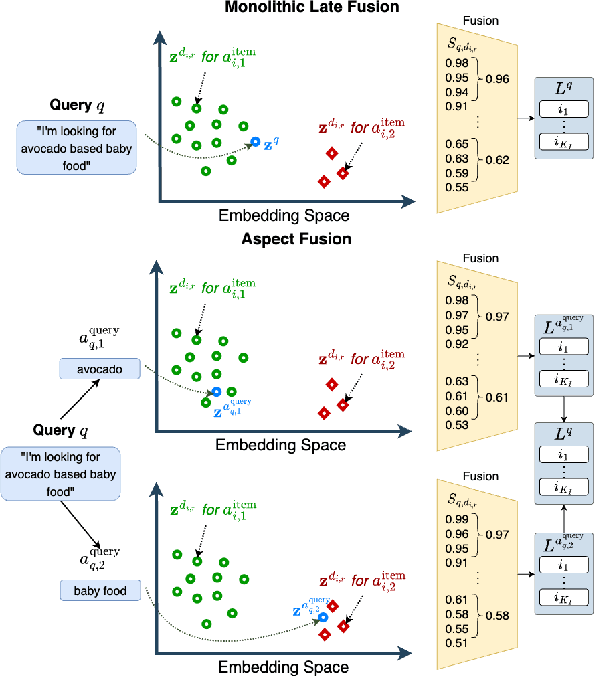
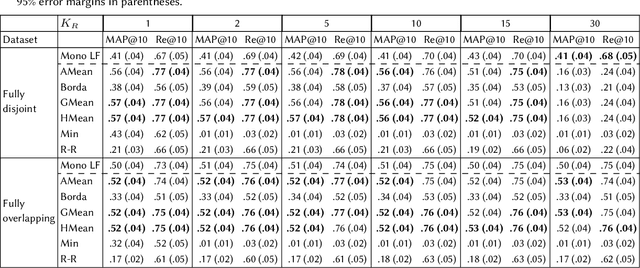
While user-generated product reviews often contain large quantities of information, their utility in addressing natural language product queries has been limited, with a key challenge being the need to aggregate information from multiple low-level sources (reviews) to a higher item level during retrieval. Existing methods for reviewed-item retrieval (RIR) typically take a late fusion (LF) approach which computes query-item scores by simply averaging the top-K query-review similarity scores for an item. However, we demonstrate that for multi-aspect queries and multi-aspect items, LF is highly sensitive to the distribution of aspects covered by reviews in terms of aspect frequency and the degree of aspect separation across reviews. To address these LF failures, we propose several novel aspect fusion (AF) strategies which include Large Language Model (LLM) query extraction and generative reranking. Our experiments show that for imbalanced review corpora, AF can improve over LF by a MAP@10 increase from 0.36 to 0.52, while achieving equivalent performance for balanced review corpora.
AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
Jul 02, 2024



Realistic scene reconstruction and view synthesis are essential for advancing autonomous driving systems by simulating safety-critical scenarios. 3D Gaussian Splatting excels in real-time rendering and static scene reconstructions but struggles with modeling driving scenarios due to complex backgrounds, dynamic objects, and sparse views. We propose AutoSplat, a framework employing Gaussian splatting to achieve highly realistic reconstructions of autonomous driving scenes. By imposing geometric constraints on Gaussians representing the road and sky regions, our method enables multi-view consistent simulation of challenging scenarios including lane changes. Leveraging 3D templates, we introduce a reflected Gaussian consistency constraint to supervise both the visible and unseen side of foreground objects. Moreover, to model the dynamic appearance of foreground objects, we estimate residual spherical harmonics for each foreground Gaussian. Extensive experiments on Pandaset and KITTI demonstrate that AutoSplat outperforms state-of-the-art methods in scene reconstruction and novel view synthesis across diverse driving scenarios. Visit our $\href{https://autosplat.github.io/}{\text{project page}}$.