 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Knowledge Distillation for LLMs with Response-Priming Prompting
Dec 18, 2024Large language models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing (NLP) tasks. However, these models are often difficult to deploy due to significant computational requirements and resource constraints. Knowledge distillation (KD) is an effective technique for transferring the performance of larger LLMs to smaller models. Traditional KD methods primarily focus on the direct output of the teacher model, with little emphasis on the role of prompting during knowledge transfer. In this paper, we propose a set of novel response-priming prompting strategies applied in the knowledge distillation pipeline to enhance the performance of student models. Our approach fine-tunes a smaller Llama 3.1 8B Instruct model by distilling knowledge from a quantized Llama 3.1 405B Instruct teacher model. We apply LoRA optimization and evaluate on the GSM8K benchmark. Experimental results demonstrate that integrating reasoning-eliciting prompting into the proposed KD pipeline significantly improves student model performance, offering an efficient way to deploy powerful models in resource-constrained environments. We find that Ground Truth prompting results in a 55\% performance increase on GSM8K for a distilled Llama 3.1 8B Instruct compared to the same model distilled without prompting. A thorough investigation into the self-attention layers of the student models indicates that the more successful prompted models tend to exhibit certain positive behaviors inside their attention heads which can be tied to their increased accuracy. Our implementation can be found at https://github.com/alonso130r/knowledge-distillation.
A Debate-Driven Experiment on LLM Hallucinations and Accuracy
Oct 25, 2024


Large language models (LLMs) have achieved a degree of success in generating coherent and contextually relevant text, yet they remain prone to a significant challenge known as hallucination: producing information that is not substantiated by the input or external knowledge. Previous efforts to mitigate hallucinations have focused on techniques such as fine-tuning models on high-quality datasets, incorporating fact-checking mechanisms, and developing adversarial training methods. While these approaches have shown some promise, they often address the issue at the level of individual model outputs, leaving unexplored the effects of inter-model interactions on hallucination. This study investigates the phenomenon of hallucination in LLMs through a novel experimental framework where multiple instances of GPT-4o-Mini models engage in a debate-like interaction prompted with questions from the TruthfulQA dataset. One model is deliberately instructed to generate plausible but false answers while the other models are asked to respond truthfully. The experiment is designed to assess whether the introduction of misinformation by one model can challenge the truthful majority to better justify their reasoning, improving performance on the TruthfulQA benchmark. The findings suggest that inter-model interactions can offer valuable insights into improving the accuracy and robustness of LLM outputs, complementing existing mitigation strategies.
Medical Imaging Complexity and its Effects on GAN Performance
Oct 23, 2024


The proliferation of machine learning models in diverse clinical applications has led to a growing need for high-fidelity, medical image training data. Such data is often scarce due to cost constraints and privacy concerns. Alleviating this burden, medical image synthesis via generative adversarial networks (GANs) emerged as a powerful method for synthetically generating photo-realistic images based on existing sets of real medical images. However, the exact image set size required to efficiently train such a GAN is unclear. In this work, we experimentally establish benchmarks that measure the relationship between a sample dataset size and the fidelity of the generated images, given the dataset's distribution of image complexities. We analyze statistical metrics based on delentropy, an image complexity measure rooted in Shannon's entropy in information theory. For our pipeline, we conduct experiments with two state-of-the-art GANs, StyleGAN 3 and SPADE-GAN, trained on multiple medical imaging datasets with variable sample sizes. Across both GANs, general performance improved with increasing training set size but suffered with increasing complexity.
Time-series Crime Prediction Across the United States Based on Socioeconomic and Political Factors
Sep 01, 2024

Traditional crime prediction techniques are slow and inefficient when generating predictions as crime increases rapidly \cite{r15}. To enhance traditional crime prediction methods, a Long Short-Term Memory and Gated Recurrent Unit model was constructed using datasets involving gender ratios, high school graduation rates, political status, unemployment rates, and median income by state over multiple years. While there may be other crime prediction tools, personalizing the model with hand picked factors allows a unique gap for the project. Producing an effective model would allow policymakers to strategically allocate specific resources and legislation in geographic areas that are impacted by crime, contributing to the criminal justice field of research \cite{r2A}. The model has an average total loss value of 70.792.30, and a average percent error of 9.74 percent, however both of these values are impacted by extreme outliers and with the correct optimization may be corrected.
Enhancing Depression Diagnosis with Chain-of-Thought Prompting
Aug 27, 2024When using AI to detect signs of depressive disorder, AI models habitually draw preemptive conclusions. We theorize that using chain-of-thought (CoT) prompting to evaluate Patient Health Questionnaire-8 (PHQ-8) scores will improve the accuracy of the scores determined by AI models. In our findings, when the models reasoned with CoT, the estimated PHQ-8 scores were consistently closer on average to the accepted true scores reported by each participant compared to when not using CoT. Our goal is to expand upon AI models' understanding of the intricacies of human conversation, allowing them to more effectively assess a patient's feelings and tone, therefore being able to more accurately discern mental disorder symptoms; ultimately, we hope to augment AI models' abilities, so that they can be widely accessible and used in the medical field.
Intraoperative Glioma Segmentation with YOLO + SAM for Improved Accuracy in Tumor Resection
Aug 27, 2024


Gliomas, a common type of malignant brain tumor, present significant surgical challenges due to their similarity to healthy tissue. Preoperative Magnetic Resonance Imaging (MRI) images are often ineffective during surgery due to factors such as brain shift, which alters the position of brain structures and tumors. This makes real-time intraoperative MRI (ioMRI) crucial, as it provides updated imaging that accounts for these shifts, ensuring more accurate tumor localization and safer resections. This paper presents a deep learning pipeline combining You Only Look Once Version 8 (YOLOv8) and Segment Anything Model Vision Transformer-base (SAM ViT-b) to enhance glioma detection and segmentation during ioMRI. Our model was trained using the Brain Tumor Segmentation 2021 (BraTS 2021) dataset, which includes standard magnetic resonance imaging (MRI) images, and noise-augmented MRI images that simulate ioMRI images. Noised MRI images are harder for a deep learning pipeline to segment, but they are more representative of surgical conditions. Achieving a Dice Similarity Coefficient (DICE) score of 0.79, our model performs comparably to state-of-the-art segmentation models tested on noiseless data. This performance demonstrates the model's potential to assist surgeons in maximizing tumor resection and improving surgical outcomes.
Rethinking the Hyperparameters for Fine-tuning
Feb 19, 2020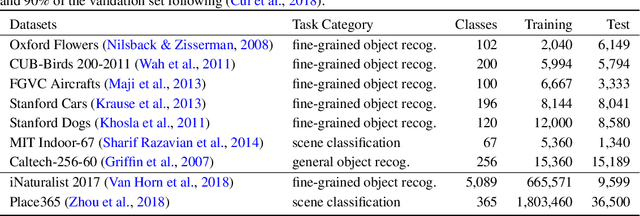
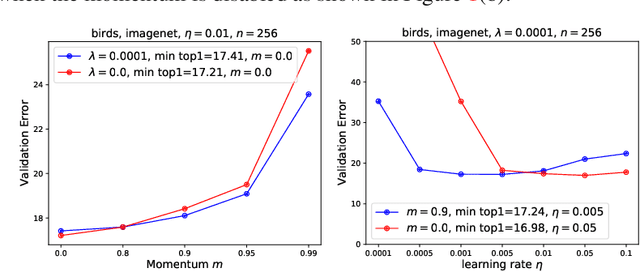
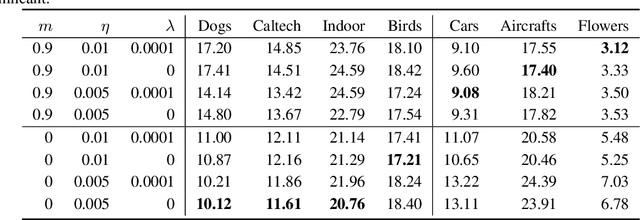
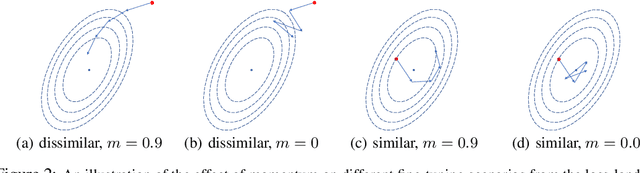
Fine-tuning from pre-trained ImageNet models has become the de-facto standard for various computer vision tasks. Current practices for fine-tuning typically involve selecting an ad-hoc choice of hyperparameters and keeping them fixed to values normally used for training from scratch. This paper re-examines several common practices of setting hyperparameters for fine-tuning. Our findings are based on extensive empirical evaluation for fine-tuning on various transfer learning benchmarks. (1) While prior works have thoroughly investigated learning rate and batch size, momentum for fine-tuning is a relatively unexplored parameter. We find that the value of momentum also affects fine-tuning performance and connect it with previous theoretical findings. (2) Optimal hyperparameters for fine-tuning, in particular, the effective learning rate, are not only dataset dependent but also sensitive to the similarity between the source domain and target domain. This is in contrast to hyperparameters for training from scratch. (3) Reference-based regularization that keeps models close to the initial model does not necessarily apply for "dissimilar" datasets. Our findings challenge common practices of fine-tuning and encourages deep learning practitioners to rethink the hyperparameters for fine-tuning.
Toward Understanding Catastrophic Forgetting in Continual Learning
Aug 02, 2019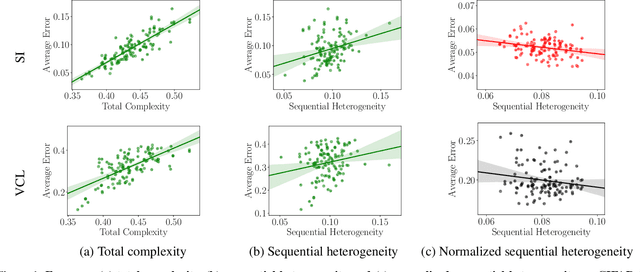
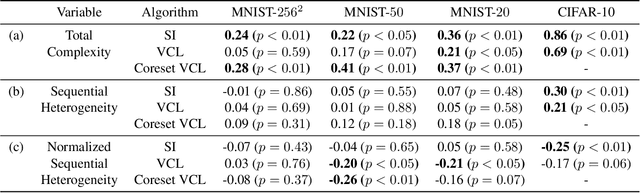

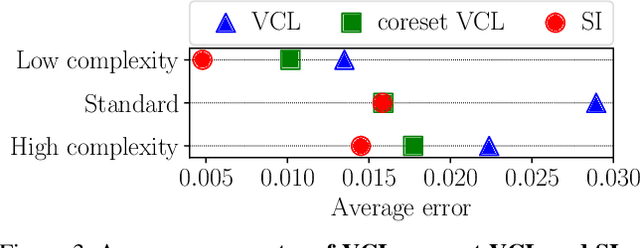
We study the relationship between catastrophic forgetting and properties of task sequences. In particular, given a sequence of tasks, we would like to understand which properties of this sequence influence the error rates of continual learning algorithms trained on the sequence. To this end, we propose a new procedure that makes use of recent developments in task space modeling as well as correlation analysis to specify and analyze the properties we are interested in. As an application, we apply our procedure to study two properties of a task sequence: (1) total complexity and (2) sequential heterogeneity. We show that error rates are strongly and positively correlated to a task sequence's total complexity for some state-of-the-art algorithms. We also show that, surprisingly, the error rates have no or even negative correlations in some cases to sequential heterogeneity. Our findings suggest directions for improving continual learning benchmarks and methods.
Task2Vec: Task Embedding for Meta-Learning
Feb 10, 2019
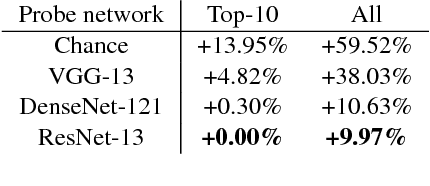
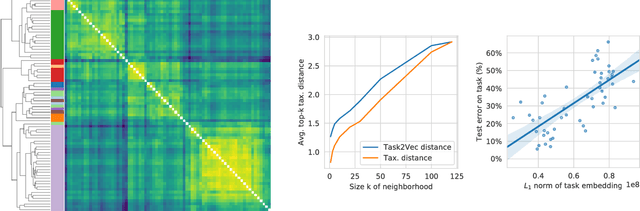

We introduce a method to provide vectorial representations of visual classification tasks which can be used to reason about the nature of those tasks and their relations. Given a dataset with ground-truth labels and a loss function defined over those labels, we process images through a "probe network" and compute an embedding based on estimates of the Fisher information matrix associated with the probe network parameters. This provides a fixed-dimensional embedding of the task that is independent of details such as the number of classes and does not require any understanding of the class label semantics. We demonstrate that this embedding is capable of predicting task similarities that match our intuition about semantic and taxonomic relations between different visual tasks (e.g., tasks based on classifying different types of plants are similar) We also demonstrate the practical value of this framework for the meta-task of selecting a pre-trained feature extractor for a new task. We present a simple meta-learning framework for learning a metric on embeddings that is capable of predicting which feature extractors will perform well. Selecting a feature extractor with task embedding obtains a performance close to the best available feature extractor, while costing substantially less than exhaustively training and evaluating on all available feature extractors.