 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask2Vec: Task Embedding for Meta-Learning
Feb 10, 2019
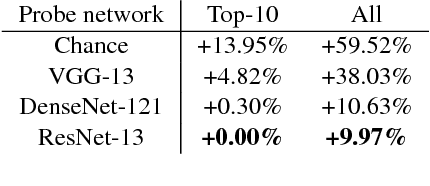
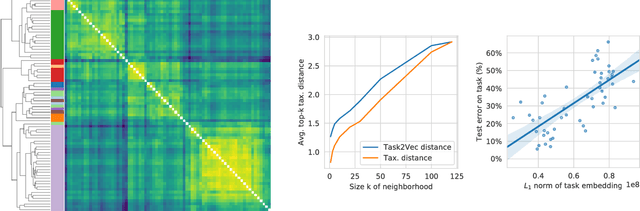

We introduce a method to provide vectorial representations of visual classification tasks which can be used to reason about the nature of those tasks and their relations. Given a dataset with ground-truth labels and a loss function defined over those labels, we process images through a "probe network" and compute an embedding based on estimates of the Fisher information matrix associated with the probe network parameters. This provides a fixed-dimensional embedding of the task that is independent of details such as the number of classes and does not require any understanding of the class label semantics. We demonstrate that this embedding is capable of predicting task similarities that match our intuition about semantic and taxonomic relations between different visual tasks (e.g., tasks based on classifying different types of plants are similar) We also demonstrate the practical value of this framework for the meta-task of selecting a pre-trained feature extractor for a new task. We present a simple meta-learning framework for learning a metric on embeddings that is capable of predicting which feature extractors will perform well. Selecting a feature extractor with task embedding obtains a performance close to the best available feature extractor, while costing substantially less than exhaustively training and evaluating on all available feature extractors.
A Self-Supervised Bootstrap Method for Single-Image 3D Face Reconstruction
Dec 17, 2018

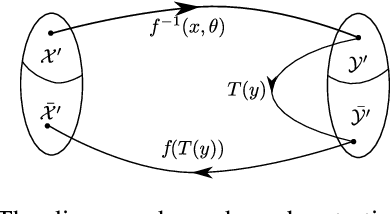
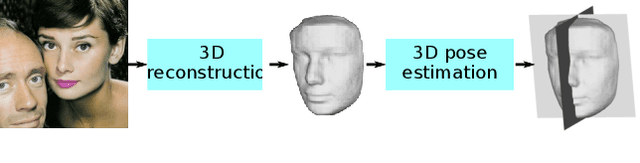
State-of-the-art methods for 3D reconstruction of faces from a single image require 2D-3D pairs of ground-truth data for supervision. Such data is costly to acquire, and most datasets available in the literature are restricted to pairs for which the input 2D images depict faces in a near fronto-parallel pose. Therefore, many data-driven methods for single-image 3D facial reconstruction perform poorly on profile and near-profile faces. We propose a method to improve the performance of single-image 3D facial reconstruction networks by utilizing the network to synthesize its own training data for fine-tuning, comprising: (i) single-image 3D reconstruction of faces in near-frontal images without ground-truth 3D shape; (ii) application of a rigid-body transformation to the reconstructed face model; (iii) rendering of the face model from new viewpoints; and (iv) use of the rendered image and corresponding 3D reconstruction as additional data for supervised fine-tuning. The new 2D-3D pairs thus produced have the same high-quality observed for near fronto-parallel reconstructions, thereby nudging the network towards more uniform performance as a function of the viewing angle of input faces. Application of the proposed technique to the fine-tuning of a state-of-the-art single-image 3D-reconstruction network for faces demonstrates the usefulness of the method, with particularly significant gains for profile or near-profile views.