 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisRef: Visual Refocusing while Thinking Improves Test-Time Scaling in Multi-Modal Large Reasoning Models
Feb 27, 2026Advances in large reasoning models have shown strong performance on complex reasoning tasks by scaling test-time compute through extended reasoning. However, recent studies observe that in vision-dependent tasks, extended textual reasoning at inference time can degrade performance as models progressively lose attention to visual tokens and increasingly rely on textual priors alone. To address this, prior works use reinforcement learning (RL)-based fine-tuning to route visual tokens or employ refocusing mechanisms during reasoning. While effective, these methods are computationally expensive, requiring large-scale data generation and policy optimization. To leverage the benefits of test-time compute without additional RL fine-tuning, we propose VisRef, a visually grounded test-time scaling framework. Our key idea is to actively guide the reasoning process by re-injecting a coreset of visual tokens that are semantically relevant to the reasoning context while remaining diverse and globally representative of the image, enabling more grounded multi-modal reasoning. Experiments on three visual reasoning benchmarks with state-of-the-art multi-modal large reasoning models demonstrate that, under fixed test-time compute budgets, VisRef consistently outperforms existing test-time scaling approaches by up to 6.4%.
AuthGuard: Generalizable Deepfake Detection via Language Guidance
Jun 04, 2025Existing deepfake detection techniques struggle to keep-up with the ever-evolving novel, unseen forgeries methods. This limitation stems from their reliance on statistical artifacts learned during training, which are often tied to specific generation processes that may not be representative of samples from new, unseen deepfake generation methods encountered at test time. We propose that incorporating language guidance can improve deepfake detection generalization by integrating human-like commonsense reasoning -- such as recognizing logical inconsistencies and perceptual anomalies -- alongside statistical cues. To achieve this, we train an expert deepfake vision encoder by combining discriminative classification with image-text contrastive learning, where the text is generated by generalist MLLMs using few-shot prompting. This allows the encoder to extract both language-describable, commonsense deepfake artifacts and statistical forgery artifacts from pixel-level distributions. To further enhance robustness, we integrate data uncertainty learning into vision-language contrastive learning, mitigating noise in image-text supervision. Our expert vision encoder seamlessly interfaces with an LLM, further enabling more generalized and interpretable deepfake detection while also boosting accuracy. The resulting framework, AuthGuard, achieves state-of-the-art deepfake detection accuracy in both in-distribution and out-of-distribution settings, achieving AUC gains of 6.15% on the DFDC dataset and 16.68% on the DF40 dataset. Additionally, AuthGuard significantly enhances deepfake reasoning, improving performance by 24.69% on the DDVQA dataset.
Ground-V: Teaching VLMs to Ground Complex Instructions in Pixels
May 20, 2025This work presents a simple yet effective workflow for automatically scaling instruction-following data to elicit pixel-level grounding capabilities of VLMs under complex instructions. In particular, we address five critical real-world challenges in text-instruction-based grounding: hallucinated references, multi-object scenarios, reasoning, multi-granularity, and part-level references. By leveraging knowledge distillation from a pre-trained teacher model, our approach generates high-quality instruction-response pairs linked to existing pixel-level annotations, minimizing the need for costly human annotation. The resulting dataset, Ground-V, captures rich object localization knowledge and nuanced pixel-level referring expressions. Experiment results show that models trained on Ground-V exhibit substantial improvements across diverse grounding tasks. Specifically, incorporating Ground-V during training directly achieves an average accuracy boost of 4.4% for LISA and a 7.9% for PSALM across six benchmarks on the gIoU metric. It also sets new state-of-the-art results on standard benchmarks such as RefCOCO/+/g. Notably, on gRefCOCO, we achieve an N-Acc of 83.3%, exceeding the previous state-of-the-art by more than 20%.
Optimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
Open-World Dynamic Prompt and Continual Visual Representation Learning
Sep 09, 2024

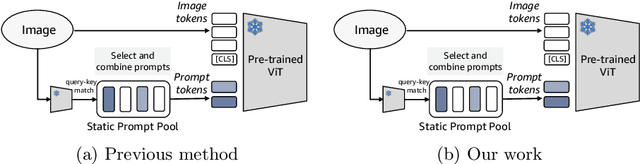

The open world is inherently dynamic, characterized by ever-evolving concepts and distributions. Continual learning (CL) in this dynamic open-world environment presents a significant challenge in effectively generalizing to unseen test-time classes. To address this challenge, we introduce a new practical CL setting tailored for open-world visual representation learning. In this setting, subsequent data streams systematically introduce novel classes that are disjoint from those seen in previous training phases, while also remaining distinct from the unseen test classes. In response, we present Dynamic Prompt and Representation Learner (DPaRL), a simple yet effective Prompt-based CL (PCL) method. Our DPaRL learns to generate dynamic prompts for inference, as opposed to relying on a static prompt pool in previous PCL methods. In addition, DPaRL jointly learns dynamic prompt generation and discriminative representation at each training stage whereas prior PCL methods only refine the prompt learning throughout the process. Our experimental results demonstrate the superiority of our approach, surpassing state-of-the-art methods on well-established open-world image retrieval benchmarks by an average of 4.7\% improvement in Recall@1 performance.
Benchmarking Neural Radiance Fields for Autonomous Robots: An Overview
May 09, 2024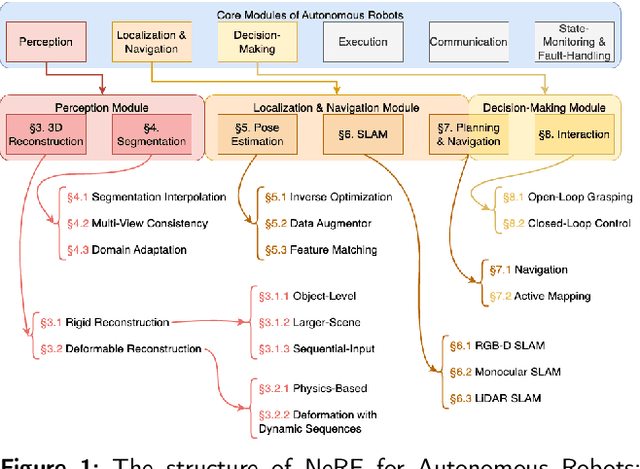
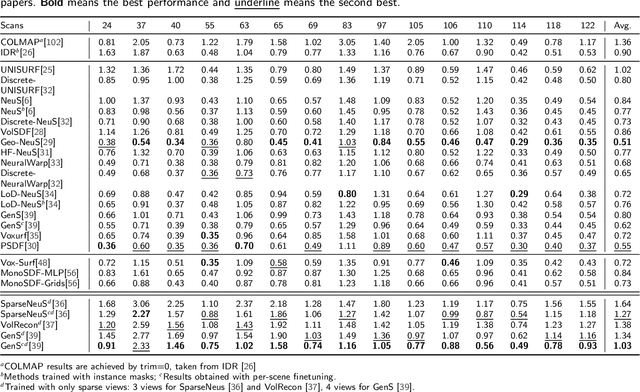
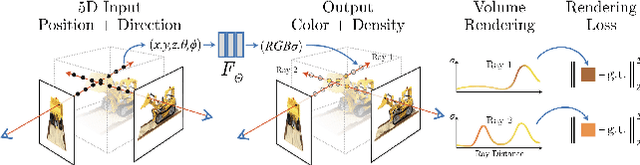
Neural Radiance Fields (NeRF) have emerged as a powerful paradigm for 3D scene representation, offering high-fidelity renderings and reconstructions from a set of sparse and unstructured sensor data. In the context of autonomous robotics, where perception and understanding of the environment are pivotal, NeRF holds immense promise for improving performance. In this paper, we present a comprehensive survey and analysis of the state-of-the-art techniques for utilizing NeRF to enhance the capabilities of autonomous robots. We especially focus on the perception, localization and navigation, and decision-making modules of autonomous robots and delve into tasks crucial for autonomous operation, including 3D reconstruction, segmentation, pose estimation, simultaneous localization and mapping (SLAM), navigation and planning, and interaction. Our survey meticulously benchmarks existing NeRF-based methods, providing insights into their strengths and limitations. Moreover, we explore promising avenues for future research and development in this domain. Notably, we discuss the integration of advanced techniques such as 3D Gaussian splatting (3DGS), large language models (LLM), and generative AIs, envisioning enhanced reconstruction efficiency, scene understanding, decision-making capabilities. This survey serves as a roadmap for researchers seeking to leverage NeRFs to empower autonomous robots, paving the way for innovative solutions that can navigate and interact seamlessly in complex environments.
Calibration-Aware Margin Loss: Pushing the Accuracy-Calibration Consistency Pareto Frontier for Deep Metric Learning
Jul 08, 2023



The ability to use the same distance threshold across different test classes / distributions is highly desired for a frictionless deployment of commercial image retrieval systems. However, state-of-the-art deep metric learning losses often result in highly varied intra-class and inter-class embedding structures, making threshold calibration a non-trivial process in practice. In this paper, we propose a novel metric named Operating-Point-Incosistency-Score (OPIS) that measures the variance in the operating characteristics across different classes in a target calibration range, and demonstrate that high accuracy of a metric learning embedding model does not guarantee calibration consistency for both seen and unseen classes. We find that, in the high-accuracy regime, there exists a Pareto frontier where accuracy improvement comes at the cost of calibration consistency. To address this, we develop a novel regularization, named Calibration-Aware Margin (CAM) loss, to encourage uniformity in the representation structures across classes during training. Extensive experiments demonstrate CAM's effectiveness in improving calibration-consistency while retaining or even enhancing accuracy, outperforming state-of-the-art deep metric learning methods.
Learning for Open-World Calibration with Graph Neural Networks
May 19, 2023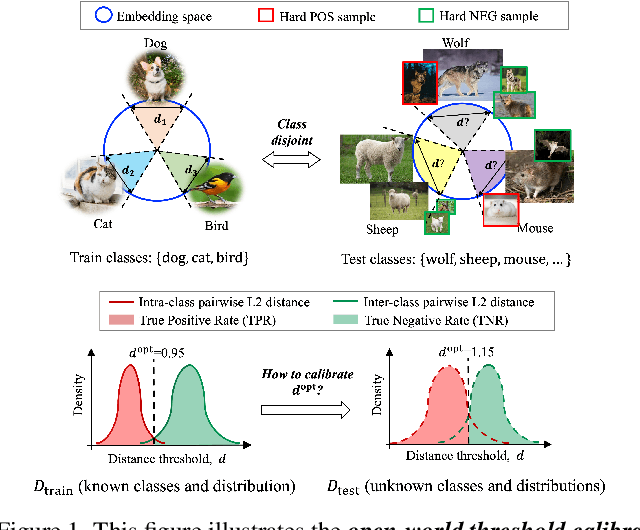
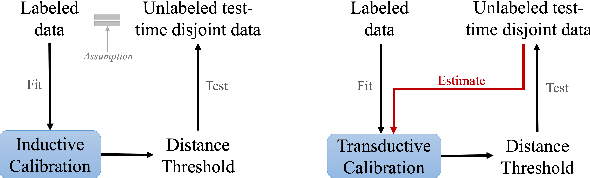

We tackle the problem of threshold calibration for open-world recognition by incorporating representation compactness measures into clustering. Unlike the open-set recognition which focuses on discovering and rejecting the unknown, open-world recognition learns robust representations that are generalizable to disjoint unknown classes at test time. Our proposed method is based on two key observations: (i) representation structures among neighbouring images in high dimensional visual embedding spaces have strong self-similarity which can be leveraged to encourage transferability to the open world, (ii) intra-class embedding structures can be modeled with the marginalized von Mises-Fisher (vMF) probability, whose correlation with the true positive rate is dataset-invariant. Motivated by these, we design a unified framework centered around a graph neural network (GNN) to jointly predict the pseudo-labels and the vMF concentrations which indicate the representation compactness. These predictions can be converted into statistical estimations for recognition accuracy, allowing more robust calibration of the distance threshold to achieve target utility for the open-world classes. Results on a variety of visual recognition benchmarks demonstrate the superiority of our method over traditional posthoc calibration methods for the open world, especially under distribution shift.
Tac-VGNN: A Voronoi Graph Neural Network for Pose-Based Tactile Servoing
Mar 05, 2023



Tactile pose estimation and tactile servoing are fundamental capabilities of robot touch. Reliable and precise pose estimation can be provided by applying deep learning models to high-resolution optical tactile sensors. Given the recent successes of Graph Neural Network (GNN) and the effectiveness of Voronoi features, we developed a Tactile Voronoi Graph Neural Network (Tac-VGNN) to achieve reliable pose-based tactile servoing relying on a biomimetic optical tactile sensor (TacTip). The GNN is well suited to modeling the distribution relationship between shear motions of the tactile markers, while the Voronoi diagram supplements this with area-based tactile features related to contact depth. The experiment results showed that the Tac-VGNN model can help enhance data interpretability during graph generation and model training efficiency significantly than CNN-based methods. It also improved pose estimation accuracy along vertical depth by 28.57% over vanilla GNN without Voronoi features and achieved better performance on the real surface following tasks with smoother robot control trajectories. For more project details, please view our website: https://sites.google.com/view/tac-vgnn/home
Fully-simulated Integration of Scamp5d Vision System and Robot Simulator
Oct 12, 2021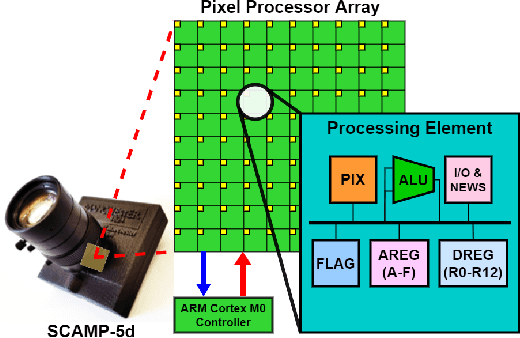

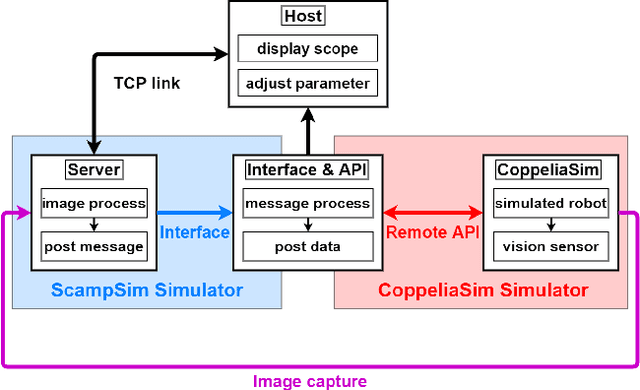
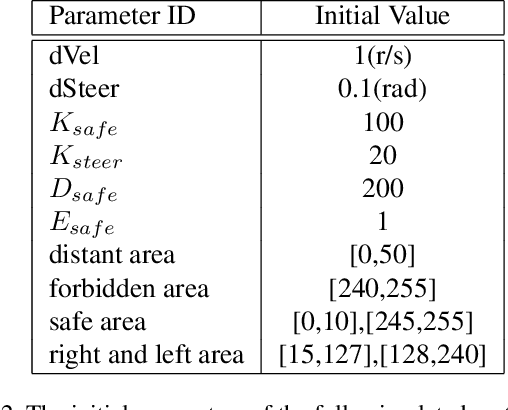
This paper proposed a fully-simulated environment by integrating an on-sensor visual computing device, SCAMP, and CoppeliaSim robot simulator via interface and remote API. Within this platform, a mobile robot obstacle avoidance and target navigation with pre-set barriers is exploited with on-sensor visual computing, where images are captured in a robot simulator and processed by an on-sensor processing server after being transferred. We made our developed platform and associated algorithms for mobile robot navigation available online.