 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthGuard: Generalizable Deepfake Detection via Language Guidance
Jun 04, 2025Existing deepfake detection techniques struggle to keep-up with the ever-evolving novel, unseen forgeries methods. This limitation stems from their reliance on statistical artifacts learned during training, which are often tied to specific generation processes that may not be representative of samples from new, unseen deepfake generation methods encountered at test time. We propose that incorporating language guidance can improve deepfake detection generalization by integrating human-like commonsense reasoning -- such as recognizing logical inconsistencies and perceptual anomalies -- alongside statistical cues. To achieve this, we train an expert deepfake vision encoder by combining discriminative classification with image-text contrastive learning, where the text is generated by generalist MLLMs using few-shot prompting. This allows the encoder to extract both language-describable, commonsense deepfake artifacts and statistical forgery artifacts from pixel-level distributions. To further enhance robustness, we integrate data uncertainty learning into vision-language contrastive learning, mitigating noise in image-text supervision. Our expert vision encoder seamlessly interfaces with an LLM, further enabling more generalized and interpretable deepfake detection while also boosting accuracy. The resulting framework, AuthGuard, achieves state-of-the-art deepfake detection accuracy in both in-distribution and out-of-distribution settings, achieving AUC gains of 6.15% on the DFDC dataset and 16.68% on the DF40 dataset. Additionally, AuthGuard significantly enhances deepfake reasoning, improving performance by 24.69% on the DDVQA dataset.
Ground-V: Teaching VLMs to Ground Complex Instructions in Pixels
May 20, 2025This work presents a simple yet effective workflow for automatically scaling instruction-following data to elicit pixel-level grounding capabilities of VLMs under complex instructions. In particular, we address five critical real-world challenges in text-instruction-based grounding: hallucinated references, multi-object scenarios, reasoning, multi-granularity, and part-level references. By leveraging knowledge distillation from a pre-trained teacher model, our approach generates high-quality instruction-response pairs linked to existing pixel-level annotations, minimizing the need for costly human annotation. The resulting dataset, Ground-V, captures rich object localization knowledge and nuanced pixel-level referring expressions. Experiment results show that models trained on Ground-V exhibit substantial improvements across diverse grounding tasks. Specifically, incorporating Ground-V during training directly achieves an average accuracy boost of 4.4% for LISA and a 7.9% for PSALM across six benchmarks on the gIoU metric. It also sets new state-of-the-art results on standard benchmarks such as RefCOCO/+/g. Notably, on gRefCOCO, we achieve an N-Acc of 83.3%, exceeding the previous state-of-the-art by more than 20%.
Backdoor Attack with Mode Mixture Latent Modification
Mar 12, 2024Backdoor attacks become a significant security concern for deep neural networks in recent years. An image classification model can be compromised if malicious backdoors are injected into it. This corruption will cause the model to function normally on clean images but predict a specific target label when triggers are present. Previous research can be categorized into two genres: poisoning a portion of the dataset with triggered images for users to train the model from scratch, or training a backdoored model alongside a triggered image generator. Both approaches require significant amount of attackable parameters for optimization to establish a connection between the trigger and the target label, which may raise suspicions as more people become aware of the existence of backdoor attacks. In this paper, we propose a backdoor attack paradigm that only requires minimal alterations (specifically, the output layer) to a clean model in order to inject the backdoor under the guise of fine-tuning. To achieve this, we leverage mode mixture samples, which are located between different modes in latent space, and introduce a novel method for conducting backdoor attacks. We evaluate the effectiveness of our method on four popular benchmark datasets: MNIST, CIFAR-10, GTSRB, and TinyImageNet.
Learning for Open-World Calibration with Graph Neural Networks
May 19, 2023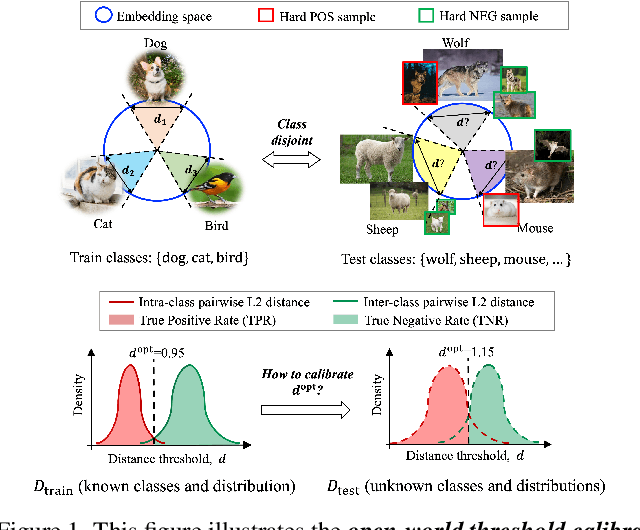
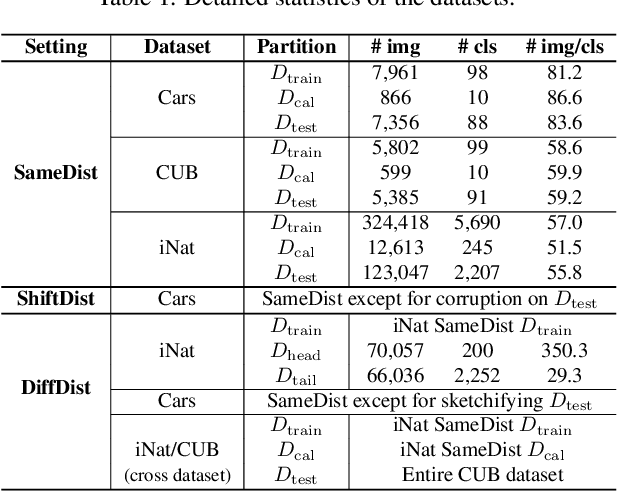
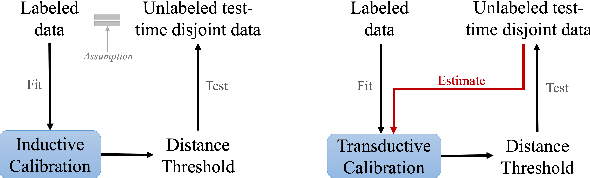

We tackle the problem of threshold calibration for open-world recognition by incorporating representation compactness measures into clustering. Unlike the open-set recognition which focuses on discovering and rejecting the unknown, open-world recognition learns robust representations that are generalizable to disjoint unknown classes at test time. Our proposed method is based on two key observations: (i) representation structures among neighbouring images in high dimensional visual embedding spaces have strong self-similarity which can be leveraged to encourage transferability to the open world, (ii) intra-class embedding structures can be modeled with the marginalized von Mises-Fisher (vMF) probability, whose correlation with the true positive rate is dataset-invariant. Motivated by these, we design a unified framework centered around a graph neural network (GNN) to jointly predict the pseudo-labels and the vMF concentrations which indicate the representation compactness. These predictions can be converted into statistical estimations for recognition accuracy, allowing more robust calibration of the distance threshold to achieve target utility for the open-world classes. Results on a variety of visual recognition benchmarks demonstrate the superiority of our method over traditional posthoc calibration methods for the open world, especially under distribution shift.
Efficient Optimal Transport Algorithm by Accelerated Gradient descent
Apr 12, 2021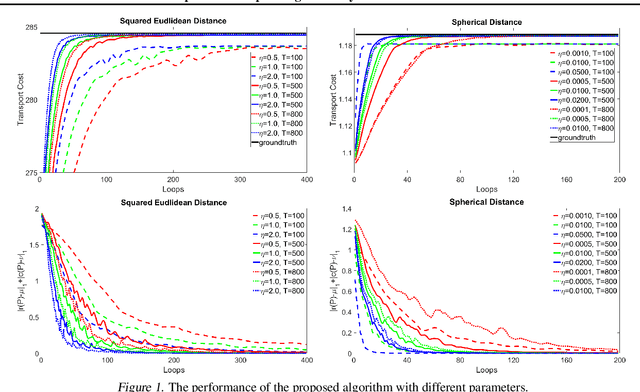
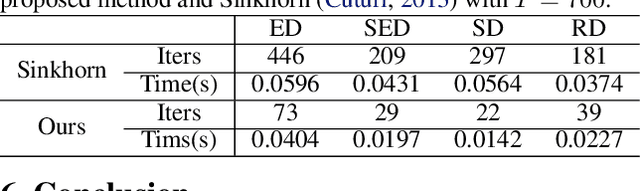
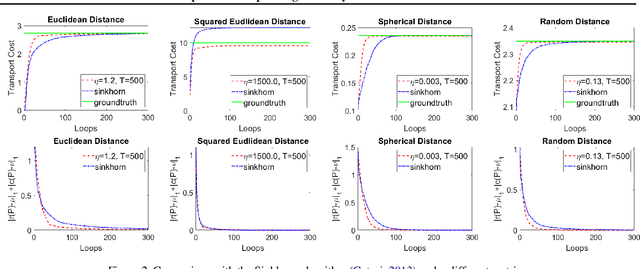
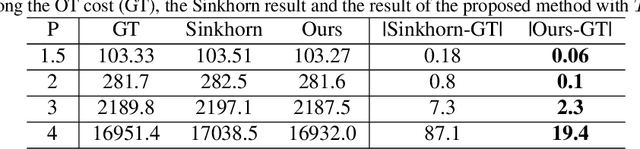
Optimal transport (OT) plays an essential role in various areas like machine learning and deep learning. However, computing discrete optimal transport plan for large scale problems with adequate accuracy and efficiency is still highly challenging. Recently, methods based on the Sinkhorn algorithm add an entropy regularizer to the prime problem and get a trade off between efficiency and accuracy. In this paper, we propose a novel algorithm to further improve the efficiency and accuracy based on Nesterov's smoothing technique. Basically, the non-smooth c-transform of the Kantorovich potential is approximated by the smooth Log-Sum-Exp function, which finally smooths the original non-smooth Kantorovich dual functional (energy). The smooth Kantorovich functional can be optimized by the fast proximal gradient algorithm (FISTA) efficiently. Theoretically, the computational complexity of the proposed method is given by $O(n^{\frac{5}{2}} \sqrt{\log n} /\epsilon)$, which is lower than that of the Sinkhorn algorithm. Empirically, compared with the Sinkhorn algorithm, our experimental results demonstrate that the proposed method achieves faster convergence and better accuracy with the same parameter.
AE-OT-GAN: Training GANs from data specific latent distribution
Jan 27, 2020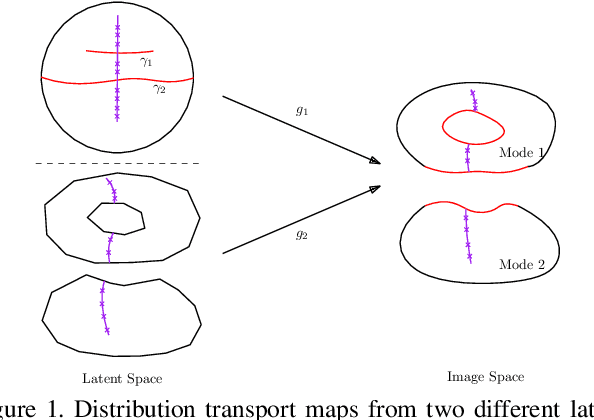
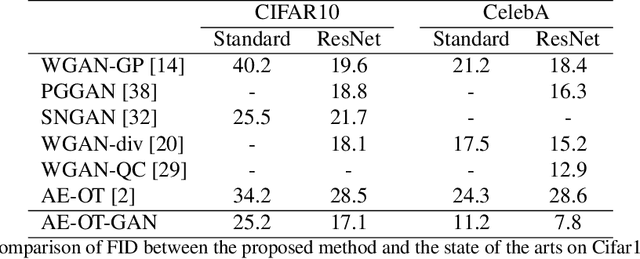
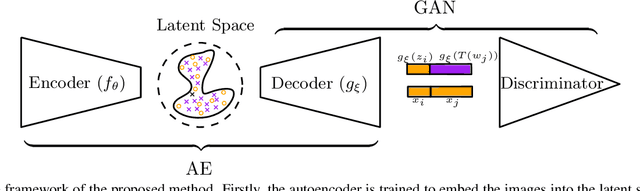
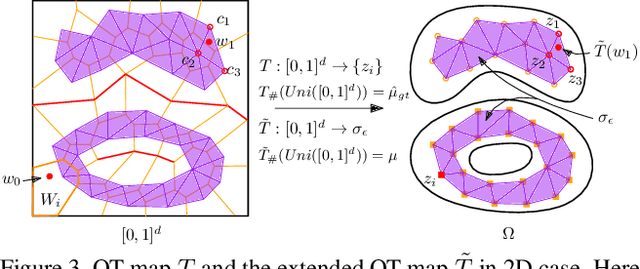
Though generative adversarial networks (GANs) areprominent models to generate realistic and crisp images,they often encounter the mode collapse problems and arehard to train, which comes from approximating the intrinsicdiscontinuous distribution transform map with continuousDNNs. The recently proposed AE-OT model addresses thisproblem by explicitly computing the discontinuous distribu-tion transform map through solving a semi-discrete optimaltransport (OT) map in the latent space of the autoencoder.However the generated images are blurry. In this paper, wepropose the AE-OT-GAN model to utilize the advantages ofthe both models: generate high quality images and at thesame time overcome the mode collapse/mixture problems.Specifically, we first faithfully embed the low dimensionalimage manifold into the latent space by training an autoen-coder (AE). Then we compute the optimal transport (OT)map that pushes forward the uniform distribution to the la-tent distribution supported on the latent manifold. Finally,our GAN model is trained to generate high quality imagesfrom the latent distribution, the distribution transform mapfrom which to the empirical data distribution will be con-tinuous. The paired data between the latent code and thereal images gives us further constriction about the generator.Experiments on simple MNIST dataset and complex datasetslike Cifar-10 and CelebA show the efficacy and efficiency ofour proposed method.
Mode Collapse and Regularity of Optimal Transportation Maps
Feb 08, 2019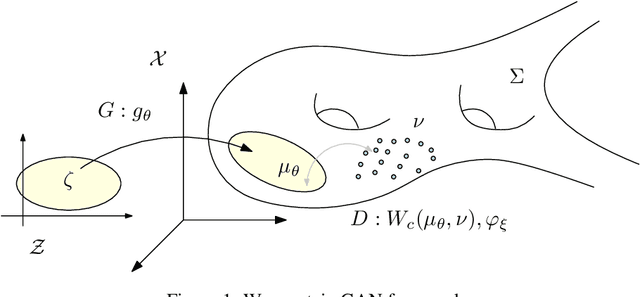
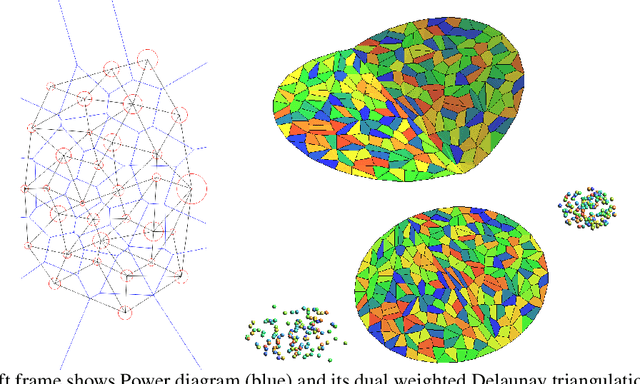
This work builds the connection between the regularity theory of optimal transportation map, Monge-Amp\`{e}re equation and GANs, which gives a theoretic understanding of the major drawbacks of GANs: convergence difficulty and mode collapse. According to the regularity theory of Monge-Amp\`{e}re equation, if the support of the target measure is disconnected or just non-convex, the optimal transportation mapping is discontinuous. General DNNs can only approximate continuous mappings. This intrinsic conflict leads to the convergence difficulty and mode collapse in GANs. We test our hypothesis that the supports of real data distribution are in general non-convex, therefore the discontinuity is unavoidable using an Autoencoder combined with discrete optimal transportation map (AE-OT framework) on the CelebA data set. The testing result is positive. Furthermore, we propose to approximate the continuous Brenier potential directly based on discrete Brenier theory to tackle mode collapse. Comparing with existing method, this method is more accurate and effective.
Fast and High Quality Highlight Removal from A Single Image
Dec 01, 2015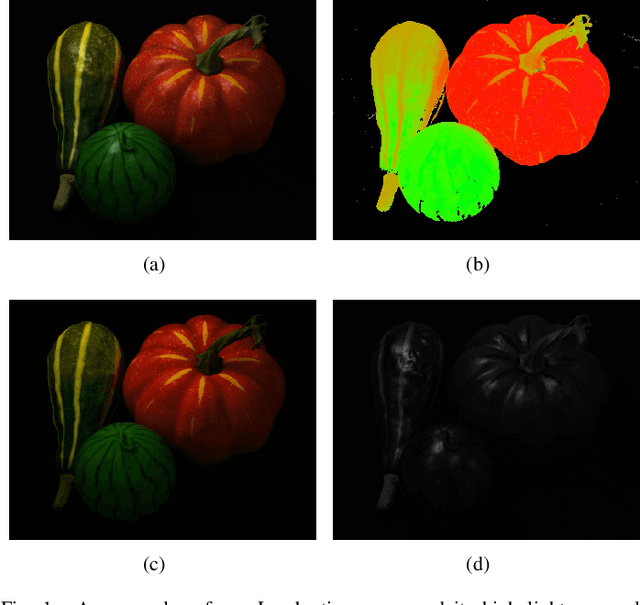

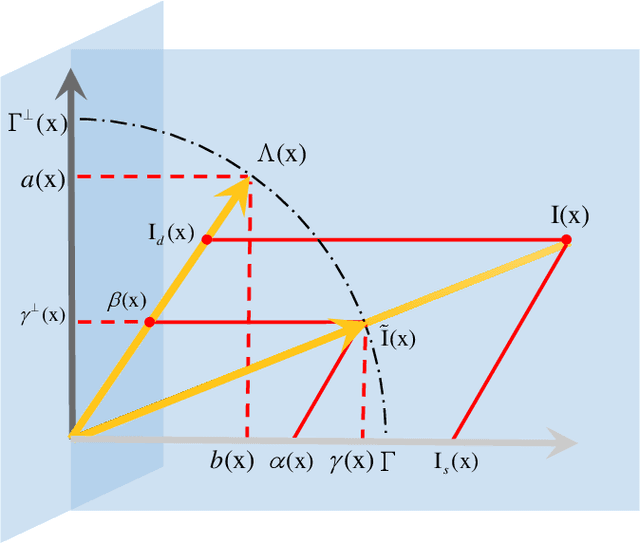

Specular reflection exists widely in photography and causes the recorded color deviating from its true value, so fast and high quality highlight removal from a single nature image is of great importance. In spite of the progress in the past decades in highlight removal, achieving wide applicability to the large diversity of nature scenes is quite challenging. To handle this problem, we propose an analytic solution to highlight removal based on an L2 chromaticity definition and corresponding dichromatic model. Specifically, this paper derives a normalized dichromatic model for the pixels with identical diffuse color: a unit circle equation of projection coefficients in two subspaces that are orthogonal to and parallel with the illumination, respectively. In the former illumination orthogonal subspace, which is specular-free, we can conduct robust clustering with an explicit criterion to determine the cluster number adaptively. In the latter illumination parallel subspace, a property called pure diffuse pixels distribution rule (PDDR) helps map each specular-influenced pixel to its diffuse component. In terms of efficiency, the proposed approach involves few complex calculation, and thus can remove highlight from high resolution images fast. Experiments show that this method is of superior performance in various challenging cases.