 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthGuard: Generalizable Deepfake Detection via Language Guidance
Jun 04, 2025Existing deepfake detection techniques struggle to keep-up with the ever-evolving novel, unseen forgeries methods. This limitation stems from their reliance on statistical artifacts learned during training, which are often tied to specific generation processes that may not be representative of samples from new, unseen deepfake generation methods encountered at test time. We propose that incorporating language guidance can improve deepfake detection generalization by integrating human-like commonsense reasoning -- such as recognizing logical inconsistencies and perceptual anomalies -- alongside statistical cues. To achieve this, we train an expert deepfake vision encoder by combining discriminative classification with image-text contrastive learning, where the text is generated by generalist MLLMs using few-shot prompting. This allows the encoder to extract both language-describable, commonsense deepfake artifacts and statistical forgery artifacts from pixel-level distributions. To further enhance robustness, we integrate data uncertainty learning into vision-language contrastive learning, mitigating noise in image-text supervision. Our expert vision encoder seamlessly interfaces with an LLM, further enabling more generalized and interpretable deepfake detection while also boosting accuracy. The resulting framework, AuthGuard, achieves state-of-the-art deepfake detection accuracy in both in-distribution and out-of-distribution settings, achieving AUC gains of 6.15% on the DFDC dataset and 16.68% on the DF40 dataset. Additionally, AuthGuard significantly enhances deepfake reasoning, improving performance by 24.69% on the DDVQA dataset.
Ground-V: Teaching VLMs to Ground Complex Instructions in Pixels
May 20, 2025This work presents a simple yet effective workflow for automatically scaling instruction-following data to elicit pixel-level grounding capabilities of VLMs under complex instructions. In particular, we address five critical real-world challenges in text-instruction-based grounding: hallucinated references, multi-object scenarios, reasoning, multi-granularity, and part-level references. By leveraging knowledge distillation from a pre-trained teacher model, our approach generates high-quality instruction-response pairs linked to existing pixel-level annotations, minimizing the need for costly human annotation. The resulting dataset, Ground-V, captures rich object localization knowledge and nuanced pixel-level referring expressions. Experiment results show that models trained on Ground-V exhibit substantial improvements across diverse grounding tasks. Specifically, incorporating Ground-V during training directly achieves an average accuracy boost of 4.4% for LISA and a 7.9% for PSALM across six benchmarks on the gIoU metric. It also sets new state-of-the-art results on standard benchmarks such as RefCOCO/+/g. Notably, on gRefCOCO, we achieve an N-Acc of 83.3%, exceeding the previous state-of-the-art by more than 20%.
Optimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
Principles of Designing Robust Remote Face Anti-Spoofing Systems
Jun 06, 2024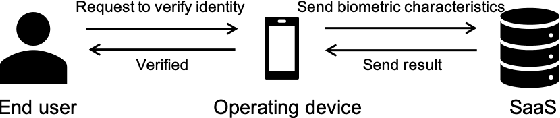

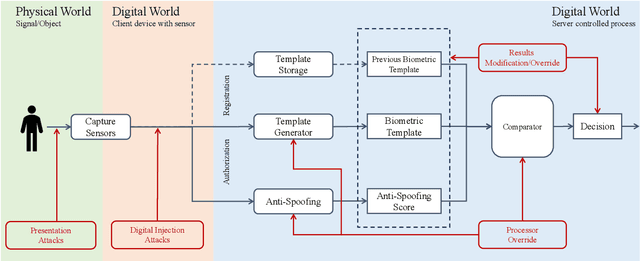

Protecting digital identities of human face from various attack vectors is paramount, and face anti-spoofing plays a crucial role in this endeavor. Current approaches primarily focus on detecting spoofing attempts within individual frames to detect presentation attacks. However, the emergence of hyper-realistic generative models capable of real-time operation has heightened the risk of digitally generated attacks. In light of these evolving threats, this paper aims to address two key aspects. First, it sheds light on the vulnerabilities of state-of-the-art face anti-spoofing methods against digital attacks. Second, it presents a comprehensive taxonomy of common threats encountered in face anti-spoofing systems. Through a series of experiments, we demonstrate the limitations of current face anti-spoofing detection techniques and their failure to generalize to novel digital attack scenarios. Notably, the existing models struggle with digital injection attacks including adversarial noise, realistic deepfake attacks, and digital replay attacks. To aid in the design and implementation of robust face anti-spoofing systems resilient to these emerging vulnerabilities, the paper proposes key design principles from model accuracy and robustness to pipeline robustness and even platform robustness. Especially, we suggest to implement the proactive face anti-spoofing system using active sensors to significant reduce the risks for unseen attack vectors and improve the user experience.
Exploring the Potential of Integrated Optical Sensing and Communication (IOSAC) Systems with Si Waveguides for Future Networks
Jun 27, 2023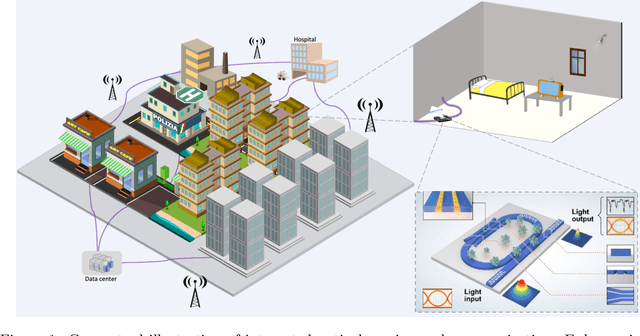
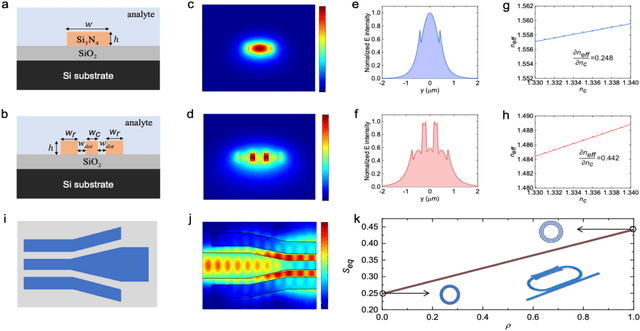
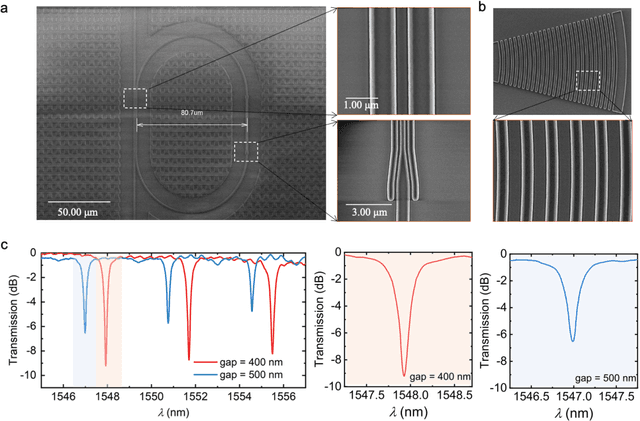
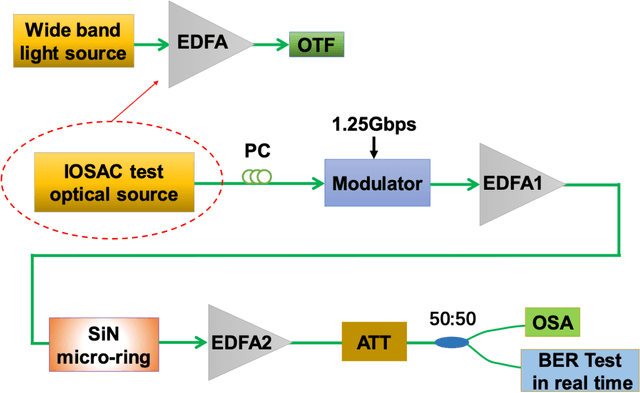
Advanced silicon photonic technologies enable integrated optical sensing and communication (IOSAC) in real time for the emerging application requirements of simultaneous sensing and communication for next-generation networks. Here, we propose and demonstrate the IOSAC system on the silicon nitride (SiN) photonics platform. The IOSAC devices based on microring resonators are capable of monitoring the variation of analytes, transmitting the information to the terminal along with the modulated optical signal in real-time, and replacing bulk optics in high-precision and high-speed applications. By directly integrating SiN ring resonators with optical communication networks, simultaneous sensing and optical communication are demonstrated by an optical signal transmission experimental system using especially filtering amplified spontaneous emission spectra. The refractive index (RI) sensing ring with a sensitivity of 172 nm/RIU, a figure of merit (FOM) of 1220, and a detection limit (DL) of 8.2*10-6 RIU is demonstrated. Simultaneously, the 1.25 Gbps optical on-off-keying (OOK) signal is transmitted at the concentration of different NaCl solutions, which indicates the bit-error-ratio (BER) decreases with the increase in concentration. The novel IOSAC technology shows the potential to realize high-performance simultaneous biosensing and communication in real time and further accelerate the development of IoT and 6G networks.
A Transformer-based Deep Learning Algorithm to Auto-record Undocumented Clinical One-Lung Ventilation Events
Feb 16, 2023As a team studying the predictors of complications after lung surgery, we have encountered high missingness of data on one-lung ventilation (OLV) start and end times due to high clinical workload and cognitive overload during surgery. Such missing data limit the precision and clinical applicability of our findings. We hypothesized that available intraoperative mechanical ventilation and physiological time-series data combined with other clinical events could be used to accurately predict missing start and end times of OLV. Such a predictive model can recover existing miss-documented records and relieves the documentation burden by deploying it in clinical settings. To this end, we develop a deep learning model to predict the occurrence and timing of OLV based on routinely collected intraoperative data. Our approach combines the variables' spatial and frequency domain features, using Transformer encoders to model the temporal evolution and convolutional neural network to abstract frequency-of-interest from wavelet spectrum images. The performance of the proposed method is evaluated on a benchmark dataset curated from Massachusetts General Hospital (MGH) and Brigham and Women's Hospital (BWH). Experiments show our approach outperforms baseline methods significantly and produces a satisfactory accuracy for clinical use.
Your "Attention" Deserves Attention: A Self-Diversified Multi-Channel Attention for Facial Action Analysis
Mar 23, 2022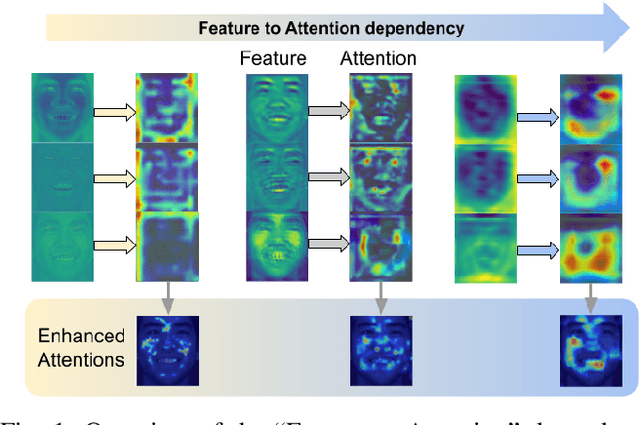
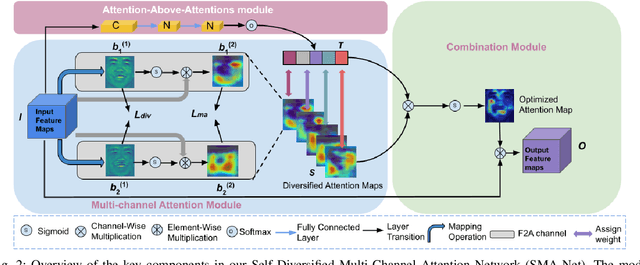
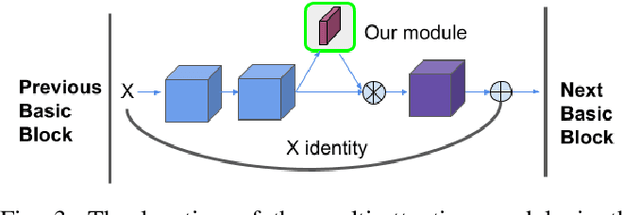
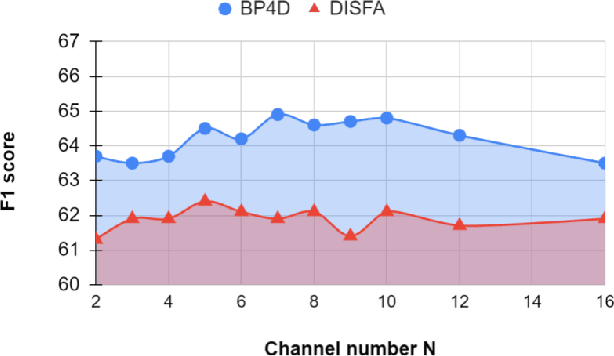
Visual attention has been extensively studied for learning fine-grained features in both facial expression recognition (FER) and Action Unit (AU) detection. A broad range of previous research has explored how to use attention modules to localize detailed facial parts (e,g. facial action units), learn discriminative features, and learn inter-class correlation. However, few related works pay attention to the robustness of the attention module itself. Through experiments, we found neural attention maps initialized with different feature maps yield diverse representations when learning to attend the identical Region of Interest (ROI). In other words, similar to general feature learning, the representational quality of attention maps also greatly affects the performance of a model, which means unconstrained attention learning has lots of randomnesses. This uncertainty lets conventional attention learning fall into sub-optimal. In this paper, we propose a compact model to enhance the representational and focusing power of neural attention maps and learn the "inter-attention" correlation for refined attention maps, which we term the "Self-Diversified Multi-Channel Attention Network (SMA-Net)". The proposed method is evaluated on two benchmark databases (BP4D and DISFA) for AU detection and four databases (CK+, MMI, BU-3DFE, and BP4D+) for facial expression recognition. It achieves superior performance compared to the state-of-the-art methods.
The First Vision For Vitals Challenge for Non-Contact Video-Based Physiological Estimation
Sep 22, 2021
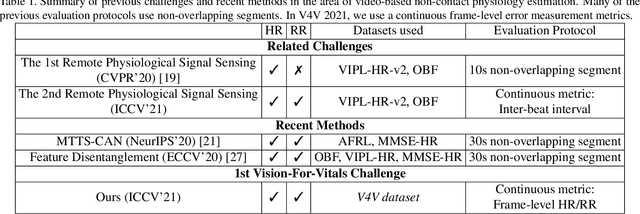
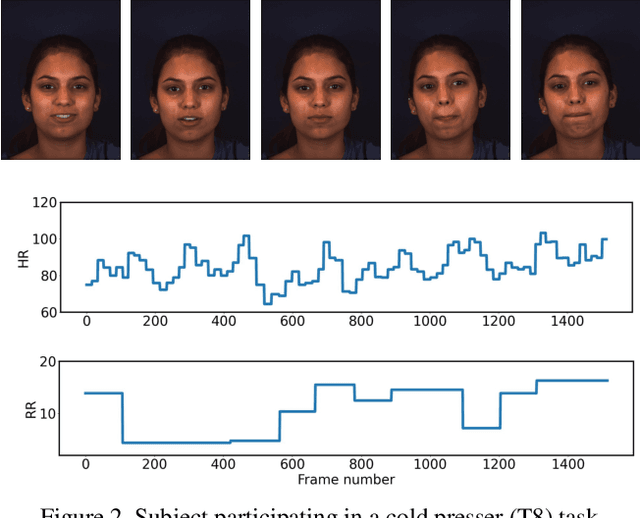
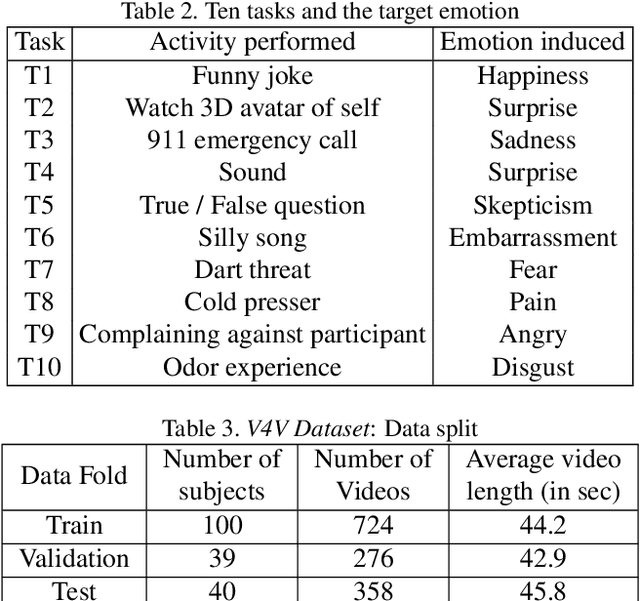
Telehealth has the potential to offset the high demand for help during public health emergencies, such as the COVID-19 pandemic. Remote Photoplethysmography (rPPG) - the problem of non-invasively estimating blood volume variations in the microvascular tissue from video - would be well suited for these situations. Over the past few years a number of research groups have made rapid advances in remote PPG methods for estimating heart rate from digital video and obtained impressive results. How these various methods compare in naturalistic conditions, where spontaneous behavior, facial expressions, and illumination changes are present, is relatively unknown. To enable comparisons among alternative methods, the 1st Vision for Vitals Challenge (V4V) presented a novel dataset containing high-resolution videos time-locked with varied physiological signals from a diverse population. In this paper, we outline the evaluation protocol, the data used, and the results. V4V is to be held in conjunction with the 2021 International Conference on Computer Vision.