 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Need One Stage: Novel-View Synthesis From A Single Blind Face Image
Mar 01, 2026We propose a novel one-stage method, NVB-Face, for generating consistent Novel-View images directly from a single Blind Face image. Existing approaches to novel-view synthesis for objects or faces typically require a high-resolution RGB image as input. When dealing with degraded images, the conventional pipeline follows a two-stage process: first restoring the image to high resolution, then synthesizing novel views from the restored result. However, this approach is highly dependent on the quality of the restored image, often leading to inaccuracies and inconsistencies in the final output. To address this limitation, we extract single-view features directly from the blind face image and introduce a feature manipulator that transforms these features into 3D-aware, multi-view latent representations. Leveraging the powerful generative capacity of a diffusion model, our framework synthesizes high-quality, consistent novel-view face images. Experimental results show that our method significantly outperforms traditional two-stage approaches in both consistency and fidelity.
UAV-Enabled Asynchronous Federated Learning
Mar 11, 2024To exploit unprecedented data generation in mobile edge networks, federated learning (FL) has emerged as a promising alternative to the conventional centralized machine learning (ML). However, there are some critical challenges for FL deployment. One major challenge called straggler issue severely limits FL's coverage where the device with the weakest channel condition becomes the bottleneck of the model aggregation performance. Besides, the huge uplink communication overhead compromises the effectiveness of FL, which is particularly pronounced in large-scale systems. To address the straggler issue, we propose the integration of an unmanned aerial vehicle (UAV) as the parameter server (UAV-PS) to coordinate the FL implementation. We further employ over-the-air computation technique that leverages the superposition property of wireless channels for efficient uplink communication. Specifically, in this paper, we develop a novel UAV-enabled over-the-air asynchronous FL (UAV-AFL) framework which supports the UAV-PS in updating the model continuously to enhance the learning performance. Moreover, we conduct a convergence analysis to quantitatively capture the impact of model asynchrony, device selection and communication errors on the UAV-AFL learning performance. Based on this, a unified communication-learning problem is formulated to maximize asymptotical learning performance by optimizing the UAV-PS trajectory, device selection and over-the-air transceiver design. Simulation results demonstrate that the proposed scheme achieves substantially learning efficiency improvement compared with the state-of-the-art approaches.
Integrating Communication, Sensing and Computing in Satellite Internet of Things: Challenges and Opportunities
Dec 03, 2023



Satellite Internet of Things (IoT) is to use satellites as the access points for IoT devices to achieve the global coverage of future IoT systems, and is expected to support burgeoning IoT applications, including communication, sensing, and computing. However, the complex and dynamic satellite environments and limited network resources raise new challenges in the design of satellite IoT systems. In this article, we focus on the joint design of communication, sensing, and computing to improve the performance of satellite IoT, which is quite different from the case of terrestrial IoT systems. We describe how the integration of the three functions can enhance system capabilities, and summarize the state-of-the-art solutions. Furthermore, we discuss the main challenges of integrating communication, sensing, and computing in satellite IoT to be solved with pressing interest.
ECG-SL: Electrocardiogram(ECG) Segment Learning, a deep learning method for ECG signal
Oct 05, 2023Electrocardiogram (ECG) is an essential signal in monitoring human heart activities. Researchers have achieved promising results in leveraging ECGs in clinical applications with deep learning models. However, the mainstream deep learning approaches usually neglect the periodic and formative attribute of the ECG heartbeat waveform. In this work, we propose a novel ECG-Segment based Learning (ECG-SL) framework to explicitly model the periodic nature of ECG signals. More specifically, ECG signals are first split into heartbeat segments, and then structural features are extracted from each of the segments. Based on the structural features, a temporal model is designed to learn the temporal information for various clinical tasks. Further, due to the fact that massive ECG signals are available but the labeled data are very limited, we also explore self-supervised learning strategy to pre-train the models, resulting significant improvement for downstream tasks. The proposed method outperforms the baseline model and shows competitive performances compared with task-specific methods in three clinical applications: cardiac condition diagnosis, sleep apnea detection, and arrhythmia classification. Further, we find that the ECG-SL tends to focus more on each heartbeat's peak and ST range than ResNet by visualizing the saliency maps.
Empirical Study of Mix-based Data Augmentation Methods in Physiological Time Series Data
Sep 18, 2023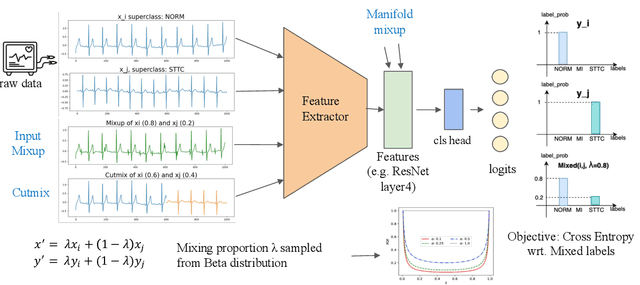
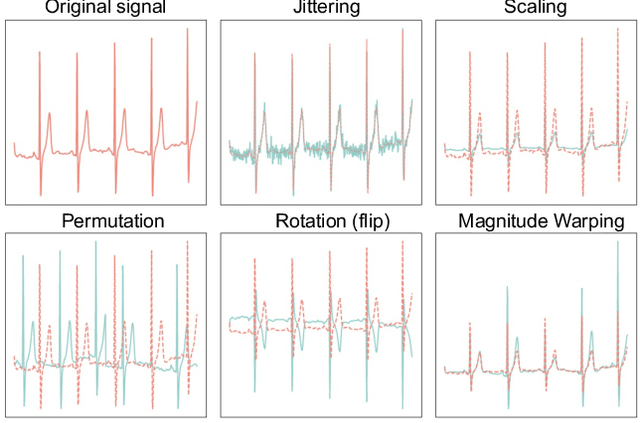
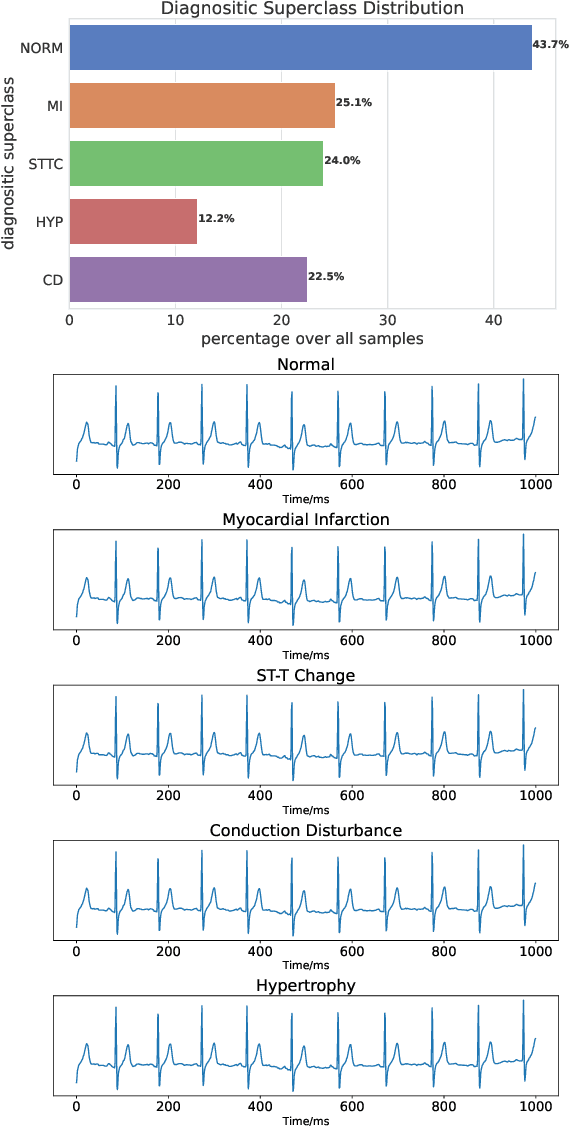
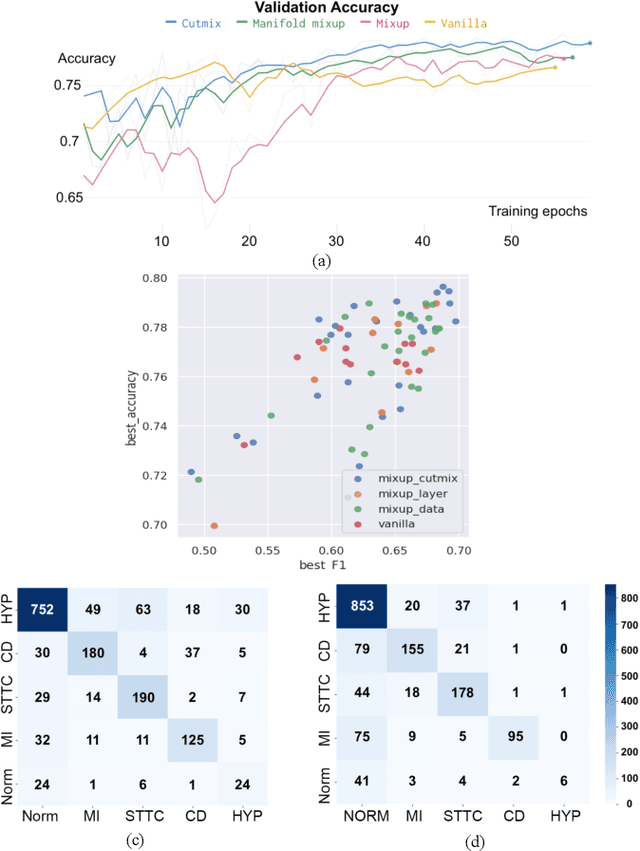
Data augmentation is a common practice to help generalization in the procedure of deep model training. In the context of physiological time series classification, previous research has primarily focused on label-invariant data augmentation methods. However, another class of augmentation techniques (\textit{i.e., Mixup}) that emerged in the computer vision field has yet to be fully explored in the time series domain. In this study, we systematically review the mix-based augmentations, including mixup, cutmix, and manifold mixup, on six physiological datasets, evaluating their performance across different sensory data and classification tasks. Our results demonstrate that the three mix-based augmentations can consistently improve the performance on the six datasets. More importantly, the improvement does not rely on expert knowledge or extensive parameter tuning. Lastly, we provide an overview of the unique properties of the mix-based augmentation methods and highlight the potential benefits of using the mix-based augmentation in physiological time series data.
Weakly-Supervised Text-driven Contrastive Learning for Facial Behavior Understanding
Mar 31, 2023Contrastive learning has shown promising potential for learning robust representations by utilizing unlabeled data. However, constructing effective positive-negative pairs for contrastive learning on facial behavior datasets remains challenging. This is because such pairs inevitably encode the subject-ID information, and the randomly constructed pairs may push similar facial images away due to the limited number of subjects in facial behavior datasets. To address this issue, we propose to utilize activity descriptions, coarse-grained information provided in some datasets, which can provide high-level semantic information about the image sequences but is often neglected in previous studies. More specifically, we introduce a two-stage Contrastive Learning with Text-Embeded framework for Facial behavior understanding (CLEF). The first stage is a weakly-supervised contrastive learning method that learns representations from positive-negative pairs constructed using coarse-grained activity information. The second stage aims to train the recognition of facial expressions or facial action units by maximizing the similarity between image and the corresponding text label names. The proposed CLEF achieves state-of-the-art performance on three in-the-lab datasets for AU recognition and three in-the-wild datasets for facial expression recognition.
PiRL: Participant-Invariant Representation Learning for Healthcare Using Maximum Mean Discrepancy and Triplet Loss
Feb 17, 2023Due to individual heterogeneity, person-specific models are usually achieving better performance than generic (one-size-fits-all) models in data-driven health applications. However, generic models are usually preferable in real-world applications, due to the difficulties of developing person-specific models, such as new-user-adaptation issues and system complexities. To improve the performance of generic models, we propose a Participant-invariant Representation Learning (PiRL) framework, which utilizes maximum mean discrepancy (MMD) loss and domain-adversarial training to encourage the model to learn participant-invariant representations. Further, to avoid trivial solutions in the learned representations, a triplet loss based constraint is used for the model to learn the label-distinguishable embeddings. The proposed framework is evaluated on two public datasets (CLAS and Apnea-ECG), and significant performance improvements are achieved compared to the baseline models.
PiRL: Participant-Invariant Representation Learning for Healthcare
Nov 21, 2022Due to individual heterogeneity, performance gaps are observed between generic (one-size-fits-all) models and person-specific models in data-driven health applications. However, in real-world applications, generic models are usually more favorable due to new-user-adaptation issues and system complexities, etc. To improve the performance of the generic model, we propose a representation learning framework that learns participant-invariant representations, named PiRL. The proposed framework utilizes maximum mean discrepancy (MMD) loss and domain-adversarial training to encourage the model to learn participant-invariant representations. Further, a triplet loss, which constrains the model for inter-class alignment of the representations, is utilized to optimize the learned representations for downstream health applications. We evaluated our frameworks on two public datasets related to physical and mental health, for detecting sleep apnea and stress, respectively. As preliminary results, we found the proposed approach shows around a 5% increase in accuracy compared to the baseline.
LEAVES: Learning Views for Time-Series Data in Contrastive Learning
Oct 13, 2022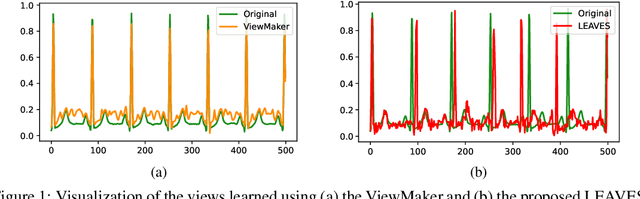

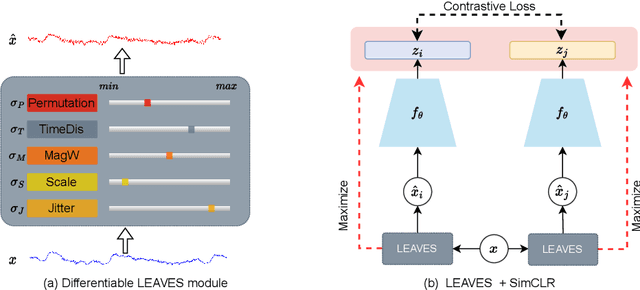

Contrastive learning, a self-supervised learning method that can learn representations from unlabeled data, has been developed promisingly. Many methods of contrastive learning depend on data augmentation techniques, which generate different views from the original signal. However, tuning policies and hyper-parameters for more effective data augmentation methods in contrastive learning is often time and resource-consuming. Researchers have designed approaches to automatically generate new views for some input signals, especially on the image data. But the view-learning method is not well developed for time-series data. In this work, we propose a simple but effective module for automating view generation for time-series data in contrastive learning, named learning views for time-series data (LEAVES). The proposed module learns the hyper-parameters for augmentations using adversarial training in contrastive learning. We validate the effectiveness of the proposed method using multiple time-series datasets. The experiments demonstrate that the proposed method is more effective in finding reasonable views and performs downstream tasks better than the baselines, including manually tuned augmentation-based contrastive learning methods and SOTA methods.
Empirical Evaluation of Data Augmentations for Biobehavioral Time Series Data with Deep Learning
Oct 13, 2022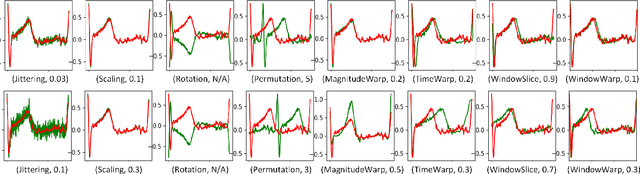
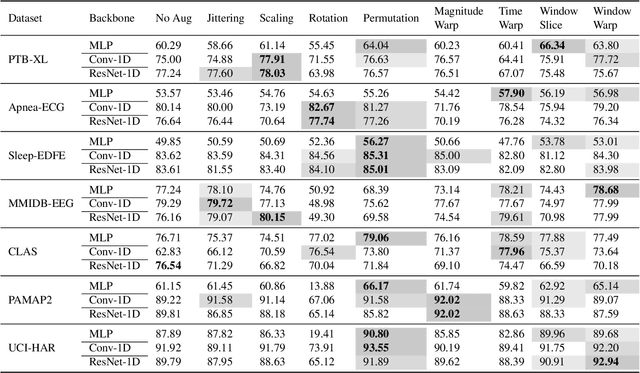


Deep learning has performed remarkably well on many tasks recently. However, the superior performance of deep models relies heavily on the availability of a large number of training data, which limits the wide adaptation of deep models on various clinical and affective computing tasks, as the labeled data are usually very limited. As an effective technique to increase the data variability and thus train deep models with better generalization, data augmentation (DA) is a critical step for the success of deep learning models on biobehavioral time series data. However, the effectiveness of various DAs for different datasets with different tasks and deep models is understudied for biobehavioral time series data. In this paper, we first systematically review eight basic DA methods for biobehavioral time series data, and evaluate the effects on seven datasets with three backbones. Next, we explore adapting more recent DA techniques (i.e., automatic augmentation, random augmentation) to biobehavioral time series data by designing a new policy architecture applicable to time series data. Last, we try to answer the question of why a DA is effective (or not) by first summarizing two desired attributes for augmentations (challenging and faithful), and then utilizing two metrics to quantitatively measure the corresponding attributes, which can guide us in the search for more effective DA for biobehavioral time series data by designing more challenging but still faithful transformations. Our code and results are available at Link.