 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Evaluation of Data Augmentations for Biobehavioral Time Series Data with Deep Learning
Paper and Code
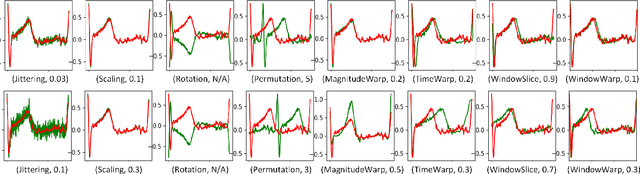
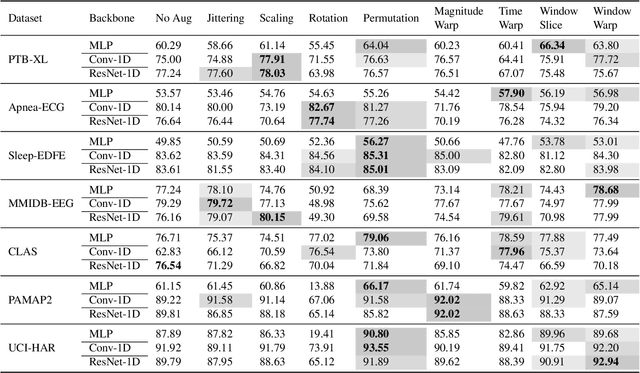


Deep learning has performed remarkably well on many tasks recently. However, the superior performance of deep models relies heavily on the availability of a large number of training data, which limits the wide adaptation of deep models on various clinical and affective computing tasks, as the labeled data are usually very limited. As an effective technique to increase the data variability and thus train deep models with better generalization, data augmentation (DA) is a critical step for the success of deep learning models on biobehavioral time series data. However, the effectiveness of various DAs for different datasets with different tasks and deep models is understudied for biobehavioral time series data. In this paper, we first systematically review eight basic DA methods for biobehavioral time series data, and evaluate the effects on seven datasets with three backbones. Next, we explore adapting more recent DA techniques (i.e., automatic augmentation, random augmentation) to biobehavioral time series data by designing a new policy architecture applicable to time series data. Last, we try to answer the question of why a DA is effective (or not) by first summarizing two desired attributes for augmentations (challenging and faithful), and then utilizing two metrics to quantitatively measure the corresponding attributes, which can guide us in the search for more effective DA for biobehavioral time series data by designing more challenging but still faithful transformations. Our code and results are available at Link.