 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Bias Paths with LLM-guided Causal Discovery: An Active Learning and Dynamic Scoring Approach
Jun 13, 2025



Causal discovery (CD) plays a pivotal role in understanding the mechanisms underlying complex systems. While recent algorithms can detect spurious associations and latent confounding, many struggle to recover fairness-relevant pathways in realistic, noisy settings. Large Language Models (LLMs), with their access to broad semantic knowledge, offer a promising complement to statistical CD approaches, particularly in domains where metadata provides meaningful relational cues. Ensuring fairness in machine learning requires understanding how sensitive attributes causally influence outcomes, yet CD methods often introduce spurious or biased pathways. We propose a hybrid LLM-based framework for CD that extends a breadth-first search (BFS) strategy with active learning and dynamic scoring. Variable pairs are prioritized for LLM-based querying using a composite score based on mutual information, partial correlation, and LLM confidence, improving discovery efficiency and robustness. To evaluate fairness sensitivity, we construct a semi-synthetic benchmark from the UCI Adult dataset, embedding a domain-informed causal graph with injected noise, label corruption, and latent confounding. We assess how well CD methods recover both global structure and fairness-critical paths. Our results show that LLM-guided methods, including the proposed method, demonstrate competitive or superior performance in recovering such pathways under noisy conditions. We highlight when dynamic scoring and active querying are most beneficial and discuss implications for bias auditing in real-world datasets.
GRAIL: A Benchmark for GRaph ActIve Learning in Dynamic Sensing Environments
Jun 11, 2025Graph-based Active Learning (AL) leverages the structure of graphs to efficiently prioritize label queries, reducing labeling costs and user burden in applications like health monitoring, human behavior analysis, and sensor networks. By identifying strategically positioned nodes, graph AL minimizes data collection demands while maintaining model performance, making it a valuable tool for dynamic environments. Despite its potential, existing graph AL methods are often evaluated on static graph datasets and primarily focus on prediction accuracy, neglecting user-centric considerations such as sampling diversity, query fairness, and adaptability to dynamic settings. To bridge this gap, we introduce GRAIL, a novel benchmarking framework designed to evaluate graph AL strategies in dynamic, real-world environments. GRAIL introduces novel metrics to assess sustained effectiveness, diversity, and user burden, enabling a comprehensive evaluation of AL methods under varying conditions. Extensive experiments on datasets featuring dynamic, real-life human sensor data reveal trade-offs between prediction performance and user burden, highlighting limitations in existing AL strategies. GRAIL demonstrates the importance of balancing node importance, query diversity, and network topology, providing an evaluation mechanism for graph AL solutions in dynamic environments.
Exploration of LLMs, EEG, and behavioral data to measure and support attention and sleep
Aug 01, 2024We explore the application of large language models (LLMs), pre-trained models with massive textual data for detecting and improving these altered states. We investigate the use of LLMs to estimate attention states, sleep stages, and sleep quality and generate sleep improvement suggestions and adaptive guided imagery scripts based on electroencephalogram (EEG) and physical activity data (e.g. waveforms, power spectrogram images, numerical features). Our results show that LLMs can estimate sleep quality based on human textual behavioral features and provide personalized sleep improvement suggestions and guided imagery scripts; however detecting attention, sleep stages, and sleep quality based on EEG and activity data requires further training data and domain-specific knowledge.
ECG Semantic Integrator (ESI): A Foundation ECG Model Pretrained with LLM-Enhanced Cardiological Text
May 26, 2024



The utilization of deep learning on electrocardiogram (ECG) analysis has brought the advanced accuracy and efficiency of cardiac healthcare diagnostics. By leveraging the capabilities of deep learning in semantic understanding, especially in feature extraction and representation learning, this study introduces a new multimodal contrastive pretaining framework that aims to improve the quality and robustness of learned representations of 12-lead ECG signals. Our framework comprises two key components, including Cardio Query Assistant (CQA) and ECG Semantics Integrator(ESI). CQA integrates a retrieval-augmented generation (RAG) pipeline to leverage large language models (LLMs) and external medical knowledge to generate detailed textual descriptions of ECGs. The generated text is enriched with information about demographics and waveform patterns. ESI integrates both contrastive and captioning loss to pretrain ECG encoders for enhanced representations. We validate our approach through various downstream tasks, including arrhythmia detection and ECG-based subject identification. Our experimental results demonstrate substantial improvements over strong baselines in these tasks. These baselines encompass supervised and self-supervised learning methods, as well as prior multimodal pretraining approaches.
AdaWaveNet: Adaptive Wavelet Network for Time Series Analysis
May 17, 2024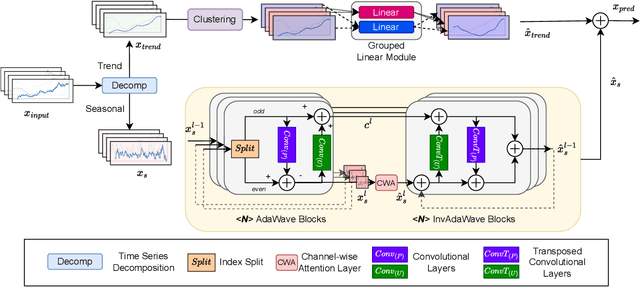
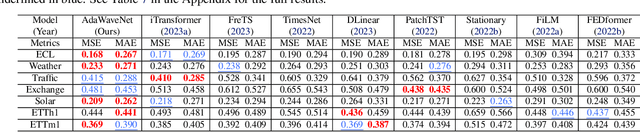
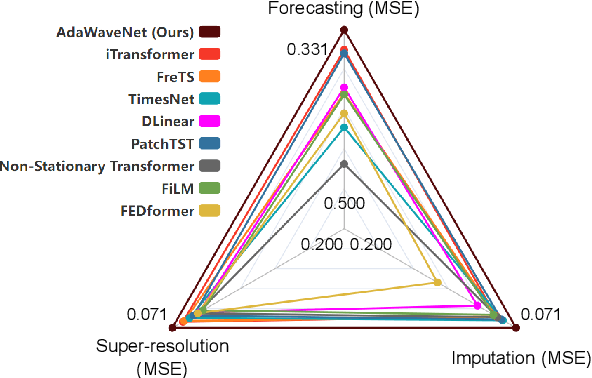
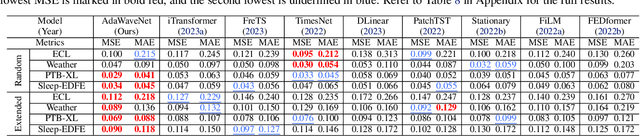
Time series data analysis is a critical component in various domains such as finance, healthcare, and meteorology. Despite the progress in deep learning for time series analysis, there remains a challenge in addressing the non-stationary nature of time series data. Traditional models, which are built on the assumption of constant statistical properties over time, often struggle to capture the temporal dynamics in realistic time series, resulting in bias and error in time series analysis. This paper introduces the Adaptive Wavelet Network (AdaWaveNet), a novel approach that employs Adaptive Wavelet Transformation for multi-scale analysis of non-stationary time series data. AdaWaveNet designed a lifting scheme-based wavelet decomposition and construction mechanism for adaptive and learnable wavelet transforms, which offers enhanced flexibility and robustness in analysis. We conduct extensive experiments on 10 datasets across 3 different tasks, including forecasting, imputation, and a newly established super-resolution task. The evaluations demonstrate the effectiveness of AdaWaveNet over existing methods in all three tasks, which illustrates its potential in various real-world applications.
Enhancing Fairness and Performance in Machine Learning Models: A Multi-Task Learning Approach with Monte-Carlo Dropout and Pareto Optimality
Apr 12, 2024



This paper considers the need for generalizable bias mitigation techniques in machine learning due to the growing concerns of fairness and discrimination in data-driven decision-making procedures across a range of industries. While many existing methods for mitigating bias in machine learning have succeeded in specific cases, they often lack generalizability and cannot be easily applied to different data types or models. Additionally, the trade-off between accuracy and fairness remains a fundamental tension in the field. To address these issues, we propose a bias mitigation method based on multi-task learning, utilizing the concept of Monte-Carlo dropout and Pareto optimality from multi-objective optimization. This method optimizes accuracy and fairness while improving the model's explainability without using sensitive information. We test this method on three datasets from different domains and show how it can deliver the most desired trade-off between model fairness and performance. This allows for tuning in specific domains where one metric may be more important than another. With the framework we introduce in this paper, we aim to enhance the fairness-performance trade-off and offer a solution to bias mitigation methods' generalizability issues in machine learning.
Balanced Mixed-Type Tabular Data Synthesis with Diffusion Models
Apr 12, 2024

Diffusion models have emerged as a robust framework for various generative tasks, such as image and audio synthesis, and have also demonstrated a remarkable ability to generate mixed-type tabular data comprising both continuous and discrete variables. However, current approaches to training diffusion models on mixed-type tabular data tend to inherit the imbalanced distributions of features present in the training dataset, which can result in biased sampling. In this research, we introduce a fair diffusion model designed to generate balanced data on sensitive attributes. We present empirical evidence demonstrating that our method effectively mitigates the class imbalance in training data while maintaining the quality of the generated samples. Furthermore, we provide evidence that our approach outperforms existing methods for synthesizing tabular data in terms of performance and fairness.
SleepNet: Attention-Enhanced Robust Sleep Prediction using Dynamic Social Networks
Jan 27, 2024Sleep behavior significantly impacts health and acts as an indicator of physical and mental well-being. Monitoring and predicting sleep behavior with ubiquitous sensors may therefore assist in both sleep management and tracking of related health conditions. While sleep behavior depends on, and is reflected in the physiology of a person, it is also impacted by external factors such as digital media usage, social network contagion, and the surrounding weather. In this work, we propose SleepNet, a system that exploits social contagion in sleep behavior through graph networks and integrates it with physiological and phone data extracted from ubiquitous mobile and wearable devices for predicting next-day sleep labels about sleep duration. Our architecture overcomes the limitations of large-scale graphs containing connections irrelevant to sleep behavior by devising an attention mechanism. The extensive experimental evaluation highlights the improvement provided by incorporating social networks in the model. Additionally, we conduct robustness analysis to demonstrate the system's performance in real-life conditions. The outcomes affirm the stability of SleepNet against perturbations in input data. Further analyses emphasize the significance of network topology in prediction performance revealing that users with higher eigenvalue centrality are more vulnerable to data perturbations.
ECG-SL: Electrocardiogram(ECG) Segment Learning, a deep learning method for ECG signal
Oct 05, 2023Electrocardiogram (ECG) is an essential signal in monitoring human heart activities. Researchers have achieved promising results in leveraging ECGs in clinical applications with deep learning models. However, the mainstream deep learning approaches usually neglect the periodic and formative attribute of the ECG heartbeat waveform. In this work, we propose a novel ECG-Segment based Learning (ECG-SL) framework to explicitly model the periodic nature of ECG signals. More specifically, ECG signals are first split into heartbeat segments, and then structural features are extracted from each of the segments. Based on the structural features, a temporal model is designed to learn the temporal information for various clinical tasks. Further, due to the fact that massive ECG signals are available but the labeled data are very limited, we also explore self-supervised learning strategy to pre-train the models, resulting significant improvement for downstream tasks. The proposed method outperforms the baseline model and shows competitive performances compared with task-specific methods in three clinical applications: cardiac condition diagnosis, sleep apnea detection, and arrhythmia classification. Further, we find that the ECG-SL tends to focus more on each heartbeat's peak and ST range than ResNet by visualizing the saliency maps.
Empirical Study of Mix-based Data Augmentation Methods in Physiological Time Series Data
Sep 18, 2023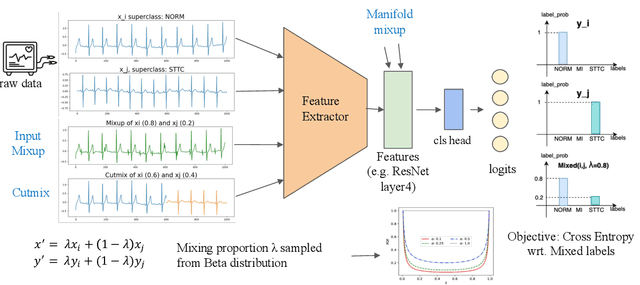
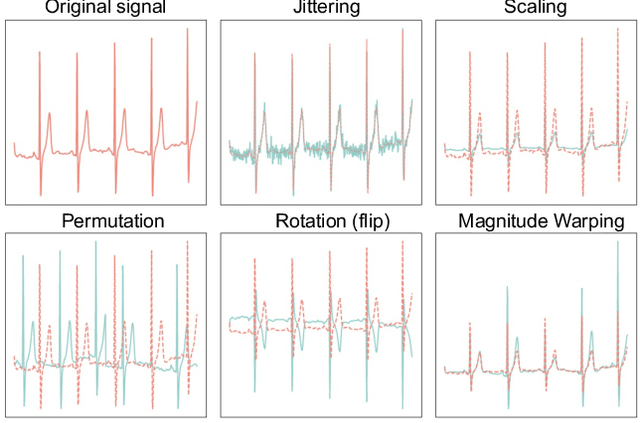
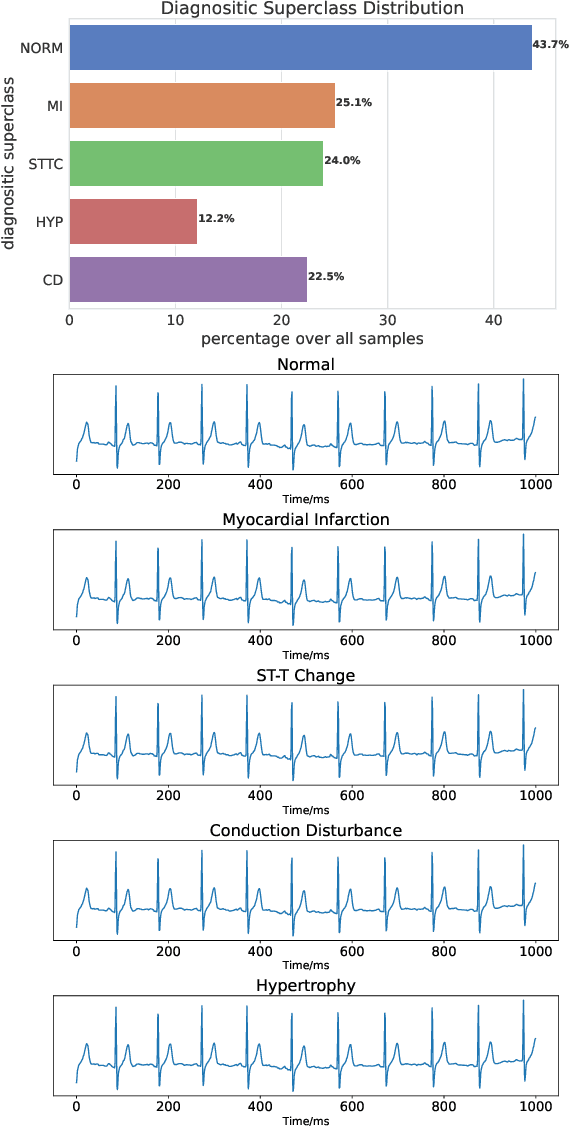
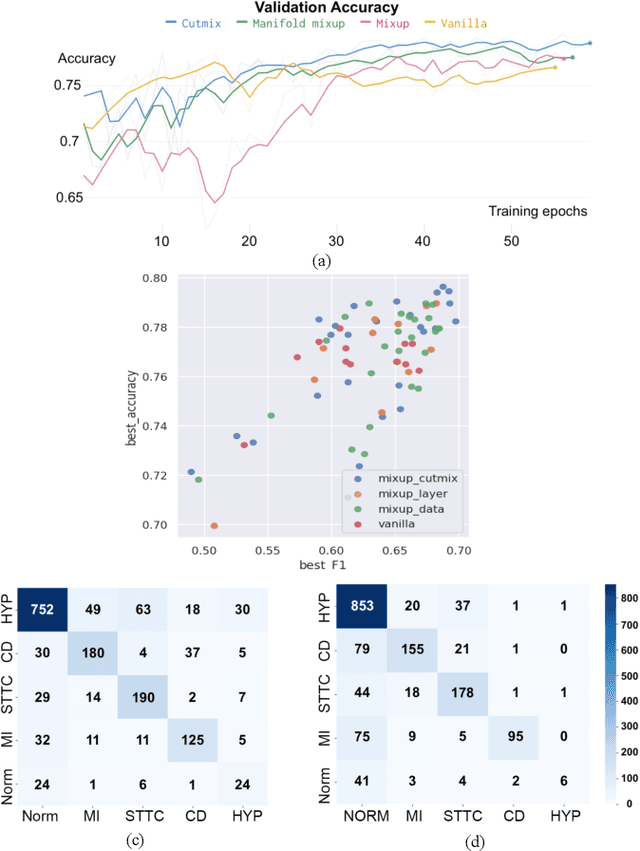
Data augmentation is a common practice to help generalization in the procedure of deep model training. In the context of physiological time series classification, previous research has primarily focused on label-invariant data augmentation methods. However, another class of augmentation techniques (\textit{i.e., Mixup}) that emerged in the computer vision field has yet to be fully explored in the time series domain. In this study, we systematically review the mix-based augmentations, including mixup, cutmix, and manifold mixup, on six physiological datasets, evaluating their performance across different sensory data and classification tasks. Our results demonstrate that the three mix-based augmentations can consistently improve the performance on the six datasets. More importantly, the improvement does not rely on expert knowledge or extensive parameter tuning. Lastly, we provide an overview of the unique properties of the mix-based augmentation methods and highlight the potential benefits of using the mix-based augmentation in physiological time series data.