 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Bias Paths with LLM-guided Causal Discovery: An Active Learning and Dynamic Scoring Approach
Jun 13, 2025Causal discovery (CD) plays a pivotal role in understanding the mechanisms underlying complex systems. While recent algorithms can detect spurious associations and latent confounding, many struggle to recover fairness-relevant pathways in realistic, noisy settings. Large Language Models (LLMs), with their access to broad semantic knowledge, offer a promising complement to statistical CD approaches, particularly in domains where metadata provides meaningful relational cues. Ensuring fairness in machine learning requires understanding how sensitive attributes causally influence outcomes, yet CD methods often introduce spurious or biased pathways. We propose a hybrid LLM-based framework for CD that extends a breadth-first search (BFS) strategy with active learning and dynamic scoring. Variable pairs are prioritized for LLM-based querying using a composite score based on mutual information, partial correlation, and LLM confidence, improving discovery efficiency and robustness. To evaluate fairness sensitivity, we construct a semi-synthetic benchmark from the UCI Adult dataset, embedding a domain-informed causal graph with injected noise, label corruption, and latent confounding. We assess how well CD methods recover both global structure and fairness-critical paths. Our results show that LLM-guided methods, including the proposed method, demonstrate competitive or superior performance in recovering such pathways under noisy conditions. We highlight when dynamic scoring and active querying are most beneficial and discuss implications for bias auditing in real-world datasets.
Balanced Mixed-Type Tabular Data Synthesis with Diffusion Models
Apr 12, 2024Diffusion models have emerged as a robust framework for various generative tasks, such as image and audio synthesis, and have also demonstrated a remarkable ability to generate mixed-type tabular data comprising both continuous and discrete variables. However, current approaches to training diffusion models on mixed-type tabular data tend to inherit the imbalanced distributions of features present in the training dataset, which can result in biased sampling. In this research, we introduce a fair diffusion model designed to generate balanced data on sensitive attributes. We present empirical evidence demonstrating that our method effectively mitigates the class imbalance in training data while maintaining the quality of the generated samples. Furthermore, we provide evidence that our approach outperforms existing methods for synthesizing tabular data in terms of performance and fairness.
Enhancing Fairness and Performance in Machine Learning Models: A Multi-Task Learning Approach with Monte-Carlo Dropout and Pareto Optimality
Apr 12, 2024



This paper considers the need for generalizable bias mitigation techniques in machine learning due to the growing concerns of fairness and discrimination in data-driven decision-making procedures across a range of industries. While many existing methods for mitigating bias in machine learning have succeeded in specific cases, they often lack generalizability and cannot be easily applied to different data types or models. Additionally, the trade-off between accuracy and fairness remains a fundamental tension in the field. To address these issues, we propose a bias mitigation method based on multi-task learning, utilizing the concept of Monte-Carlo dropout and Pareto optimality from multi-objective optimization. This method optimizes accuracy and fairness while improving the model's explainability without using sensitive information. We test this method on three datasets from different domains and show how it can deliver the most desired trade-off between model fairness and performance. This allows for tuning in specific domains where one metric may be more important than another. With the framework we introduce in this paper, we aim to enhance the fairness-performance trade-off and offer a solution to bias mitigation methods' generalizability issues in machine learning.
Bias Reducing Multitask Learning on Mental Health Prediction
Aug 07, 2022



There has been an increase in research in developing machine learning models for mental health detection or prediction in recent years due to increased mental health issues in society. Effective use of mental health prediction or detection models can help mental health practitioners re-define mental illnesses more objectively than currently done, and identify illnesses at an earlier stage when interventions may be more effective. However, there is still a lack of standard in evaluating bias in such machine learning models in the field, which leads to challenges in providing reliable predictions and in addressing disparities. This lack of standards persists due to factors such as technical difficulties, complexities of high dimensional clinical health data, etc., which are especially true for physiological signals. This along with prior evidence of relations between some physiological signals with certain demographic identities restates the importance of exploring bias in mental health prediction models that utilize physiological signals. In this work, we aim to perform a fairness analysis and implement a multi-task learning based bias mitigation method on anxiety prediction models using ECG data. Our method is based on the idea of epistemic uncertainty and its relationship with model weights and feature space representation. Our analysis showed that our anxiety prediction base model introduced some bias with regards to age, income, ethnicity, and whether a participant is born in the U.S. or not, and our bias mitigation method performed better at reducing the bias in the model, when compared to the reweighting mitigation technique. Our analysis on feature importance also helped identify relationships between heart rate variability and multiple demographic groupings.
Studying the Impact of Mood on Identifying Smartphone Users
Jun 27, 2019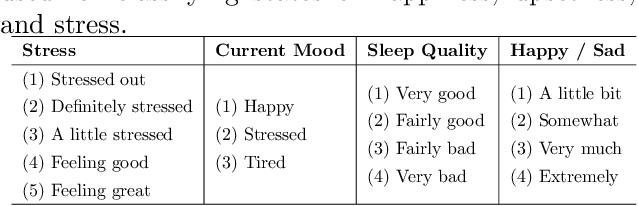
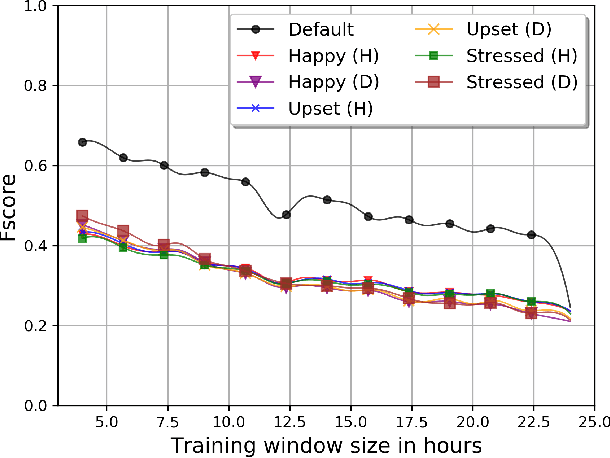

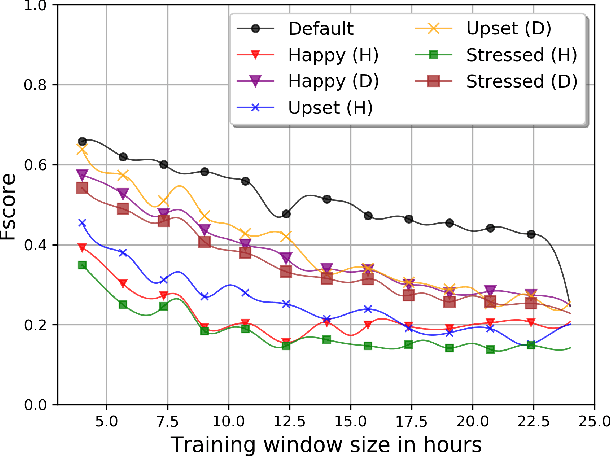
This paper explores the identification of smartphone users when certain samples collected while the subject felt happy, upset or stressed were absent or present. We employ data from 19 subjects using the StudentLife dataset, a dataset collected by researchers at Dartmouth College that was originally collected to correlate behaviors characterized by smartphone usage patterns with changes in stress and academic performance. Although many previous works on behavioral biometrics have implied that mood is a source of intra-person variation which may impact biometric performance, our results contradict this assumption. Our findings show that performance worsens when removing samples that were generated when subjects may be happy, upset, or stressed. Thus, there is no indication that mood negatively impacts performance. However, we do find that changes existing in smartphone usage patterns may correlate with mood, including changes in locking, audio, location, calling, homescreen, and e-mail habits. Thus, we show that while mood is a source of intra-person variation, it may be an inaccurate assumption that biometric systems (particularly, mobile biometrics) are likely influenced by mood.