 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Reducing Multitask Learning on Mental Health Prediction
Aug 07, 2022



There has been an increase in research in developing machine learning models for mental health detection or prediction in recent years due to increased mental health issues in society. Effective use of mental health prediction or detection models can help mental health practitioners re-define mental illnesses more objectively than currently done, and identify illnesses at an earlier stage when interventions may be more effective. However, there is still a lack of standard in evaluating bias in such machine learning models in the field, which leads to challenges in providing reliable predictions and in addressing disparities. This lack of standards persists due to factors such as technical difficulties, complexities of high dimensional clinical health data, etc., which are especially true for physiological signals. This along with prior evidence of relations between some physiological signals with certain demographic identities restates the importance of exploring bias in mental health prediction models that utilize physiological signals. In this work, we aim to perform a fairness analysis and implement a multi-task learning based bias mitigation method on anxiety prediction models using ECG data. Our method is based on the idea of epistemic uncertainty and its relationship with model weights and feature space representation. Our analysis showed that our anxiety prediction base model introduced some bias with regards to age, income, ethnicity, and whether a participant is born in the U.S. or not, and our bias mitigation method performed better at reducing the bias in the model, when compared to the reweighting mitigation technique. Our analysis on feature importance also helped identify relationships between heart rate variability and multiple demographic groupings.
More to Less : Enhanced Health Recognition in the Wild with Reduced Modality of Wearable Sensors
Feb 16, 2022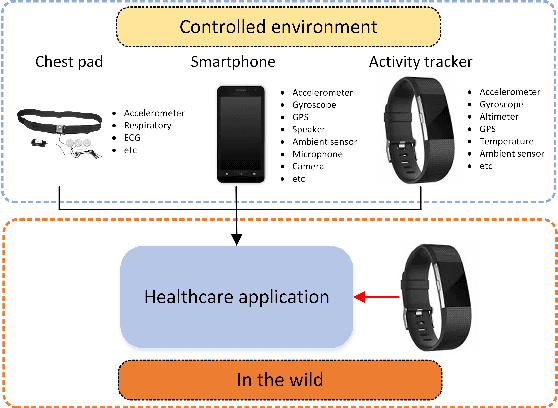
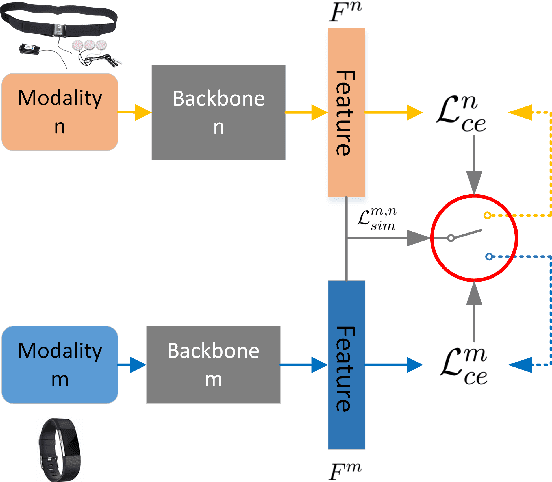
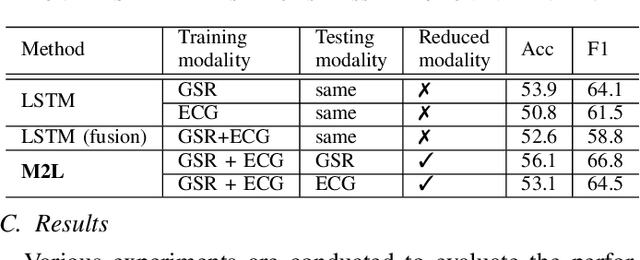
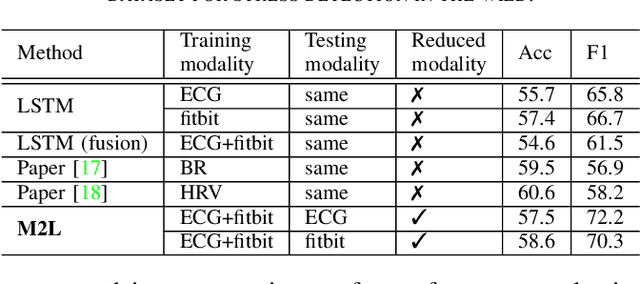
Accurately recognizing health-related conditions from wearable data is crucial for improved healthcare outcomes. To improve the recognition accuracy, various approaches have focused on how to effectively fuse information from multiple sensors. Fusing multiple sensors is a common scenario in many applications, but may not always be feasible in real-world scenarios. For example, although combining bio-signals from multiple sensors (i.e., a chest pad sensor and a wrist wearable sensor) has been proved effective for improved performance, wearing multiple devices might be impractical in the free-living context. To solve the challenges, we propose an effective more to less (M2L) learning framework to improve testing performance with reduced sensors through leveraging the complementary information of multiple modalities during training. More specifically, different sensors may carry different but complementary information, and our model is designed to enforce collaborations among different modalities, where positive knowledge transfer is encouraged and negative knowledge transfer is suppressed, so that better representation is learned for individual modalities. Our experimental results show that our framework achieves comparable performance when compared with the full modalities. Our code and results will be available at https://github.com/compwell-org/More2Less.git.
Unsupervised Personalization of an Emotion Recognition System: The Unique Properties of the Externalization of Valence in Speech
Jan 19, 2022
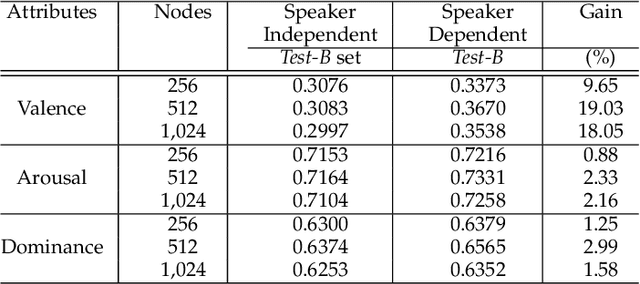
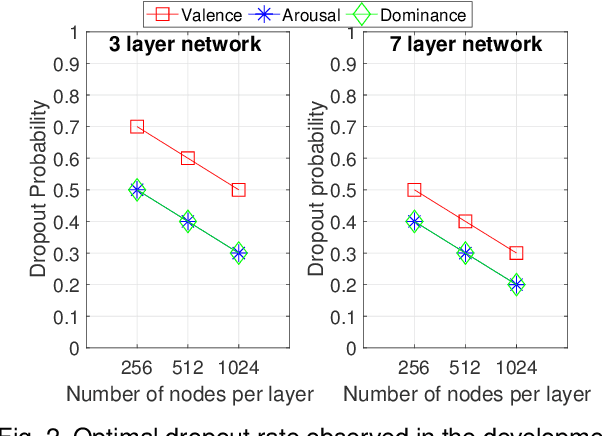

The prediction of valence from speech is an important, but challenging problem. The externalization of valence in speech has speaker-dependent cues, which contribute to performances that are often significantly lower than the prediction of other emotional attributes such as arousal and dominance. A practical approach to improve valence prediction from speech is to adapt the models to the target speakers in the test set. Adapting a speech emotion recognition (SER) system to a particular speaker is a hard problem, especially with deep neural networks (DNNs), since it requires optimizing millions of parameters. This study proposes an unsupervised approach to address this problem by searching for speakers in the train set with similar acoustic patterns as the speaker in the test set. Speech samples from the selected speakers are used to create the adaptation set. This approach leverages transfer learning using pre-trained models, which are adapted with these speech samples. We propose three alternative adaptation strategies: unique speaker, oversampling and weighting approaches. These methods differ on the use of the adaptation set in the personalization of the valence models. The results demonstrate that a valence prediction model can be efficiently personalized with these unsupervised approaches, leading to relative improvements as high as 13.52%.