 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Personalization of an Emotion Recognition System: The Unique Properties of the Externalization of Valence in Speech
Paper and Code
Jan 19, 2022
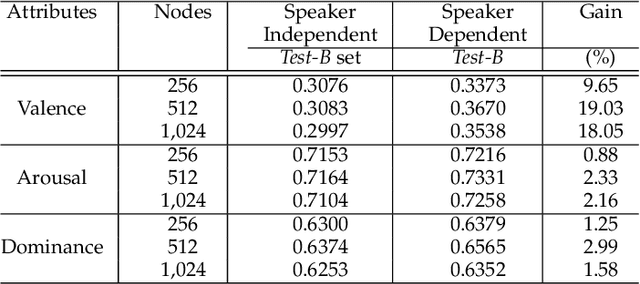
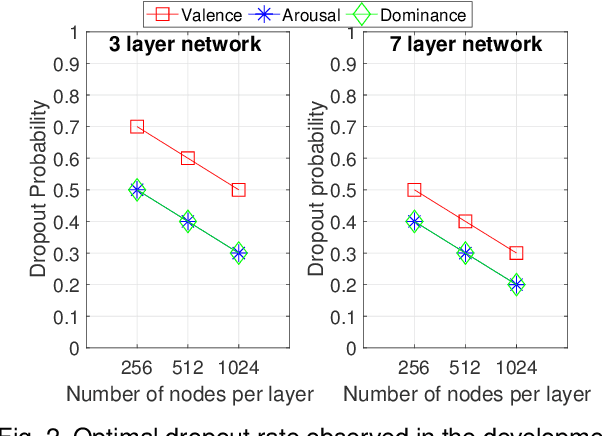

The prediction of valence from speech is an important, but challenging problem. The externalization of valence in speech has speaker-dependent cues, which contribute to performances that are often significantly lower than the prediction of other emotional attributes such as arousal and dominance. A practical approach to improve valence prediction from speech is to adapt the models to the target speakers in the test set. Adapting a speech emotion recognition (SER) system to a particular speaker is a hard problem, especially with deep neural networks (DNNs), since it requires optimizing millions of parameters. This study proposes an unsupervised approach to address this problem by searching for speakers in the train set with similar acoustic patterns as the speaker in the test set. Speech samples from the selected speakers are used to create the adaptation set. This approach leverages transfer learning using pre-trained models, which are adapted with these speech samples. We propose three alternative adaptation strategies: unique speaker, oversampling and weighting approaches. These methods differ on the use of the adaptation set in the personalization of the valence models. The results demonstrate that a valence prediction model can be efficiently personalized with these unsupervised approaches, leading to relative improvements as high as 13.52%.