 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Learning with Channel-Mixing and Masked Autoencoder on Facial Action Unit Detection
Paper and Code
Sep 25, 2022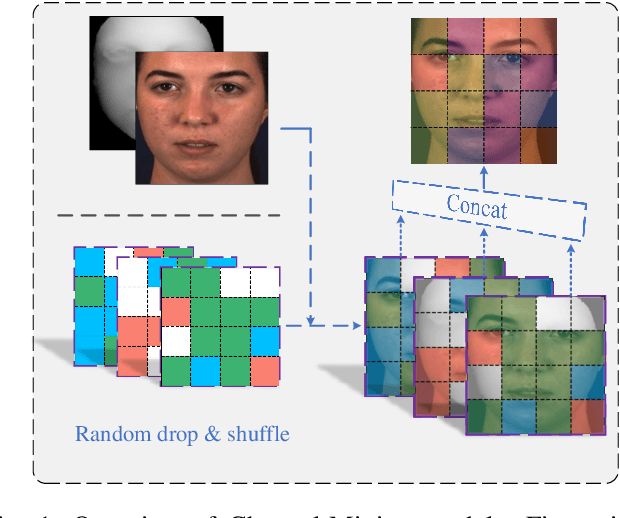
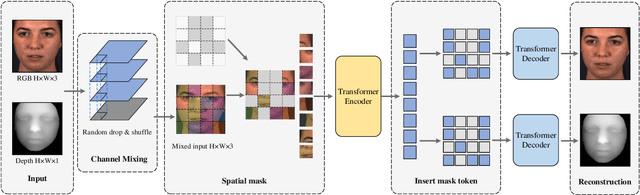
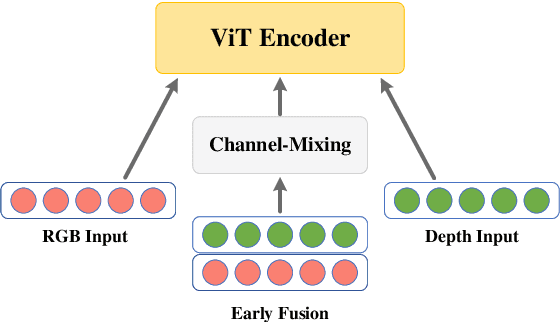

Recent studies utilizing multi-modal data aimed at building a robust model for facial Action Unit (AU) detection. However, due to the heterogeneity of multi-modal data, multi-modal representation learning becomes one of the main challenges. On one hand, it is difficult to extract the relevant features from multi-modalities by only one feature extractor, on the other hand, previous studies have not fully explored the potential of multi-modal fusion strategies. For example, early fusion usually required all modalities to be present during inference, while late fusion and middle fusion increased the network size for feature learning. In contrast to a large amount of work on late fusion, there are few works on early fusion to explore the channel information. This paper presents a novel multi-modal network called Multi-modal Channel-Mixing (MCM), as a pre-trained model to learn a robust representation in order to facilitate the multi-modal fusion. We evaluate the learned representation on a downstream task of automatic facial action units detection. Specifically, it is a single stream encoder network that uses a channel-mixing module in early fusion, requiring only one modality in the downstream detection task. We also utilize the masked ViT encoder to learn features from the fusion image and reconstruct back two modalities with two ViT decoders. We have conducted extensive experiments on two public datasets, known as BP4D and DISFA, to evaluate the effectiveness and robustness of the proposed multimodal framework. The results show our approach is comparable or superior to the state-of-the-art baseline methods.