 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnlineHMR: Video-based Online World-Grounded Human Mesh Recovery
Mar 18, 2026Human mesh recovery (HMR) models 3D human body from monocular videos, with recent works extending it to world-coordinate human trajectory and motion reconstruction. However, most existing methods remain offline, relying on future frames or global optimization, which limits their applicability in interactive feedback and perception-action loop scenarios such as AR/VR and telepresence. To address this, we propose OnlineHMR, a fully online framework that jointly satisfies four essential criteria of online processing, including system-level causality, faithfulness, temporal consistency, and efficiency. Built upon a two-branch architecture, OnlineHMR enables streaming inference via a causal key-value cache design and a curated sliding-window learning strategy. Meanwhile, a human-centric incremental SLAM provides online world-grounded alignment under physically plausible trajectory correction. Experimental results show that our method achieves performance comparable to existing chunk-based approaches on the standard EMDB benchmark and highly dynamic custom videos, while uniquely supporting online processing. Page and code are available at https://tsukasane.github.io/Video-OnlineHMR/.
Pri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Mar 02, 2026Humans learn not only how their bodies move, but also how the surrounding world responds to their actions. In contrast, while recent Vision-Language-Action (VLA) models exhibit impressive semantic understanding, they often fail to capture the spatiotemporal dynamics governing physical interaction. In this paper, we introduce Pri4R, a simple yet effective approach that endows VLA models with an implicit understanding of world dynamics by leveraging privileged 4D information during training. Specifically, Pri4R augments VLAs with a lightweight point track head that predicts 3D point tracks. By injecting VLA features into this head to jointly predict future 3D trajectories, the model learns to incorporate evolving scene geometry within its shared representation space, enabling more physically aware context for precise control. Due to its architectural simplicity, Pri4R is compatible with dominant VLA design patterns with minimal changes. During inference, we run the model using the original VLA architecture unchanged; Pri4R adds no extra inputs, outputs, or computational overhead. Across simulation and real-world evaluations, Pri4R significantly improves performance on challenging manipulation tasks, including a +10% gain on LIBERO-Long and a +40% gain on RoboCasa. We further show that 3D point track prediction is an effective supervision target for learning action-world dynamics, and validate our design choices through extensive ablations.
AlignDiff: Learning Physically-Grounded Camera Alignment via Diffusion
Mar 27, 2025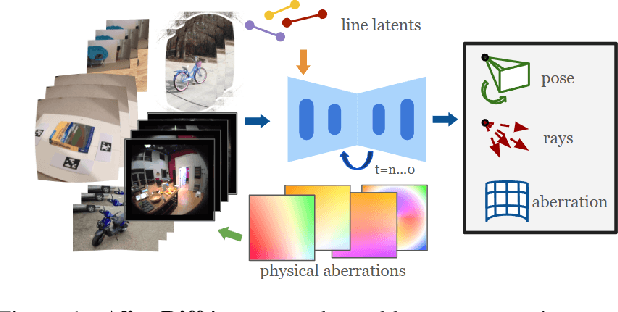
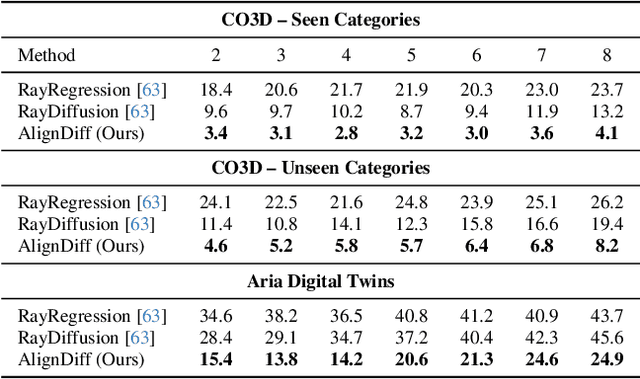
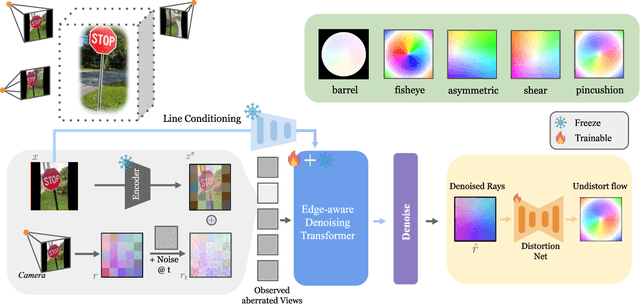
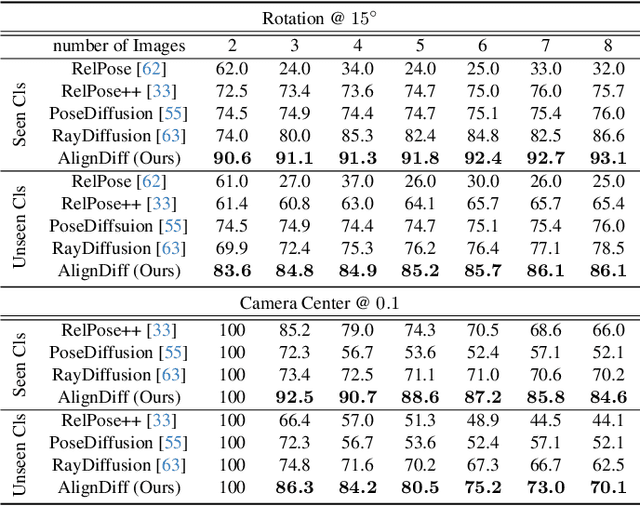
Accurate camera calibration is a fundamental task for 3D perception, especially when dealing with real-world, in-the-wild environments where complex optical distortions are common. Existing methods often rely on pre-rectified images or calibration patterns, which limits their applicability and flexibility. In this work, we introduce a novel framework that addresses these challenges by jointly modeling camera intrinsic and extrinsic parameters using a generic ray camera model. Unlike previous approaches, AlignDiff shifts focus from semantic to geometric features, enabling more accurate modeling of local distortions. We propose AlignDiff, a diffusion model conditioned on geometric priors, enabling the simultaneous estimation of camera distortions and scene geometry. To enhance distortion prediction, we incorporate edge-aware attention, focusing the model on geometric features around image edges, rather than semantic content. Furthermore, to enhance generalizability to real-world captures, we incorporate a large database of ray-traced lenses containing over three thousand samples. This database characterizes the distortion inherent in a diverse variety of lens forms. Our experiments demonstrate that the proposed method significantly reduces the angular error of estimated ray bundles by ~8.2 degrees and overall calibration accuracy, outperforming existing approaches on challenging, real-world datasets.
Through the Curved Cover: Synthesizing Cover Aberrated Scenes with Refractive Field
Nov 10, 2024
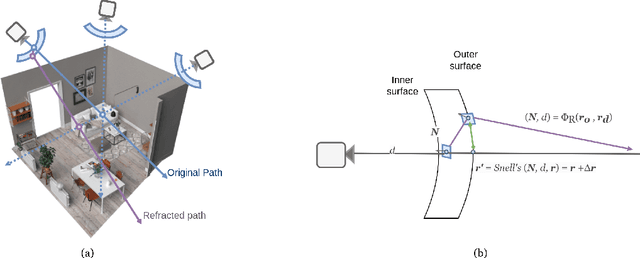


Recent extended reality headsets and field robots have adopted covers to protect the front-facing cameras from environmental hazards and falls. The surface irregularities on the cover can lead to optical aberrations like blurring and non-parametric distortions. Novel view synthesis methods like NeRF and 3D Gaussian Splatting are ill-equipped to synthesize from sequences with optical aberrations. To address this challenge, we introduce SynthCover to enable novel view synthesis through protective covers for downstream extended reality applications. SynthCover employs a Refractive Field that estimates the cover's geometry, enabling precise analytical calculation of refracted rays. Experiments on synthetic and real-world scenes demonstrate our method's ability to accurately model scenes viewed through protective covers, achieving a significant improvement in rendering quality compared to prior methods. We also show that the model can adjust well to various cover geometries with synthetic sequences captured with covers of different surface curvatures. To motivate further studies on this problem, we provide the benchmarked dataset containing real and synthetic walkable scenes captured with protective cover optical aberrations.
Gaussian Splatting LK
Jul 16, 2024Reconstructing dynamic 3D scenes from 2D images and generating diverse views over time presents a significant challenge due to the inherent complexity and temporal dynamics involved. While recent advancements in neural implicit models and dynamic Gaussian Splatting have shown promise, limitations persist, particularly in accurately capturing the underlying geometry of highly dynamic scenes. Some approaches address this by incorporating strong semantic and geometric priors through diffusion models. However, we explore a different avenue by investigating the potential of regularizing the native warp field within the dynamic Gaussian Splatting framework. Our method is grounded on the key intuition that an accurate warp field should produce continuous space-time motions. While enforcing the motion constraints on warp fields is non-trivial, we show that we can exploit knowledge innate to the forward warp field network to derive an analytical velocity field, then time integrate for scene flows to effectively constrain both the 2D motion and 3D positions of the Gaussians. This derived Lucas-Kanade style analytical regularization enables our method to achieve superior performance in reconstructing highly dynamic scenes, even under minimal camera movement, extending the boundaries of what existing dynamic Gaussian Splatting frameworks can achieve.
3D-LFM: Lifting Foundation Model
Dec 19, 2023



The lifting of 3D structure and camera from 2D landmarks is at the cornerstone of the entire discipline of computer vision. Traditional methods have been confined to specific rigid objects, such as those in Perspective-n-Point (PnP) problems, but deep learning has expanded our capability to reconstruct a wide range of object classes (e.g. C3PDO and PAUL) with resilience to noise, occlusions, and perspective distortions. All these techniques, however, have been limited by the fundamental need to establish correspondences across the 3D training data -- significantly limiting their utility to applications where one has an abundance of "in-correspondence" 3D data. Our approach harnesses the inherent permutation equivariance of transformers to manage varying number of points per 3D data instance, withstands occlusions, and generalizes to unseen categories. We demonstrate state of the art performance across 2D-3D lifting task benchmarks. Since our approach can be trained across such a broad class of structures we refer to it simply as a 3D Lifting Foundation Model (3D-LFM) -- the first of its kind.
TEMPO: Efficient Multi-View Pose Estimation, Tracking, and Forecasting
Sep 14, 2023



Existing volumetric methods for predicting 3D human pose estimation are accurate, but computationally expensive and optimized for single time-step prediction. We present TEMPO, an efficient multi-view pose estimation model that learns a robust spatiotemporal representation, improving pose accuracy while also tracking and forecasting human pose. We significantly reduce computation compared to the state-of-the-art by recurrently computing per-person 2D pose features, fusing both spatial and temporal information into a single representation. In doing so, our model is able to use spatiotemporal context to predict more accurate human poses without sacrificing efficiency. We further use this representation to track human poses over time as well as predict future poses. Finally, we demonstrate that our model is able to generalize across datasets without scene-specific fine-tuning. TEMPO achieves 10$\%$ better MPJPE with a 33$\times$ improvement in FPS compared to TesseTrack on the challenging CMU Panoptic Studio dataset.
Unsupervised Style-based Explicit 3D Face Reconstruction from Single Image
Apr 24, 2023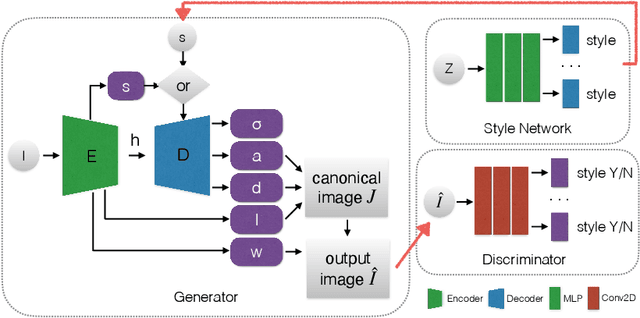
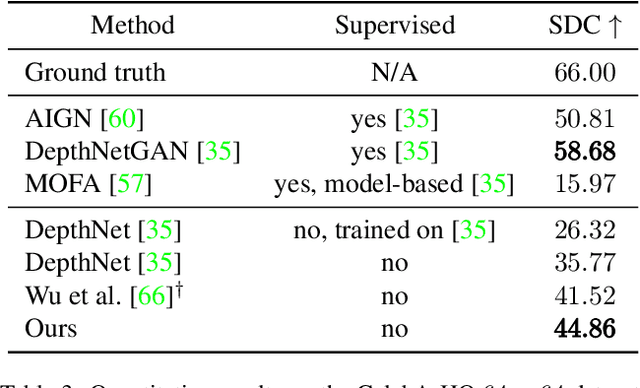
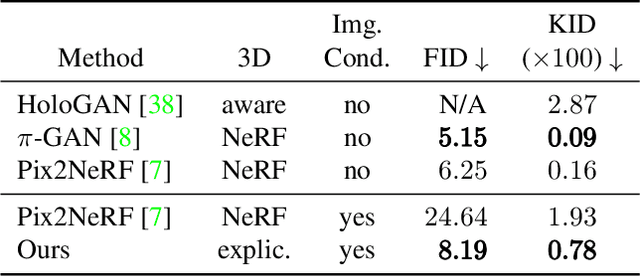

Inferring 3D object structures from a single image is an ill-posed task due to depth ambiguity and occlusion. Typical resolutions in the literature include leveraging 2D or 3D ground truth for supervised learning, as well as imposing hand-crafted symmetry priors or using an implicit representation to hallucinate novel viewpoints for unsupervised methods. In this work, we propose a general adversarial learning framework for solving Unsupervised 2D to Explicit 3D Style Transfer (UE3DST). Specifically, we merge two architectures: the unsupervised explicit 3D reconstruction network of Wu et al.\ and the Generative Adversarial Network (GAN) named StarGAN-v2. We experiment across three facial datasets (Basel Face Model, 3DFAW and CelebA-HQ) and show that our solution is able to outperform well established solutions such as DepthNet in 3D reconstruction and Pix2NeRF in conditional style transfer, while we also justify the individual contributions of our model components via ablation. In contrast to the aforementioned baselines, our scheme produces features for explicit 3D rendering, which can be manipulated and utilized in downstream tasks.
Flow supervision for Deformable NeRF
Mar 28, 2023
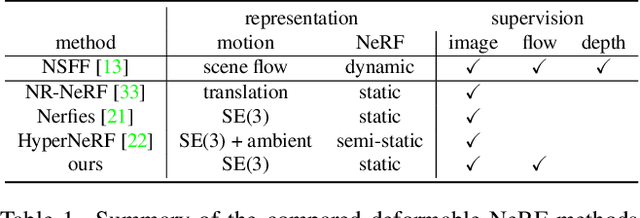
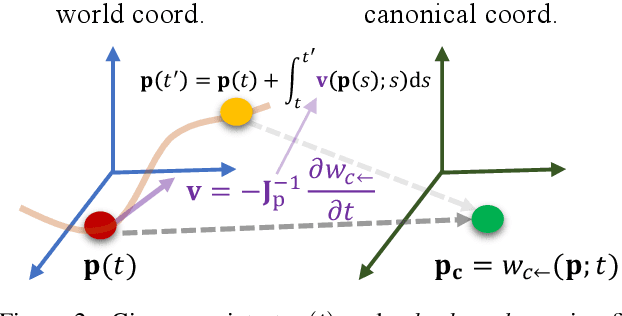
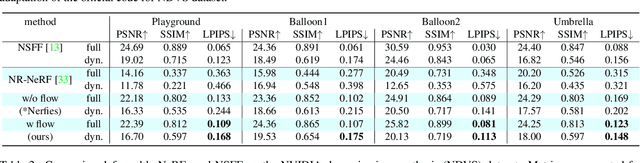
In this paper we present a new method for deformable NeRF that can directly use optical flow as supervision. We overcome the major challenge with respect to the computationally inefficiency of enforcing the flow constraints to the backward deformation field, used by deformable NeRFs. Specifically, we show that inverting the backward deformation function is actually not needed for computing scene flows between frames. This insight dramatically simplifies the problem, as one is no longer constrained to deformation functions that can be analytically inverted. Instead, thanks to the weak assumptions required by our derivation based on the inverse function theorem, our approach can be extended to a broad class of commonly used backward deformation field. We present results on monocular novel view synthesis with rapid object motion, and demonstrate significant improvements over baselines without flow supervision.
DyLiN: Making Light Field Networks Dynamic
Mar 24, 2023



Light Field Networks, the re-formulations of radiance fields to oriented rays, are magnitudes faster than their coordinate network counterparts, and provide higher fidelity with respect to representing 3D structures from 2D observations. They would be well suited for generic scene representation and manipulation, but suffer from one problem: they are limited to holistic and static scenes. In this paper, we propose the Dynamic Light Field Network (DyLiN) method that can handle non-rigid deformations, including topological changes. We learn a deformation field from input rays to canonical rays, and lift them into a higher dimensional space to handle discontinuities. We further introduce CoDyLiN, which augments DyLiN with controllable attribute inputs. We train both models via knowledge distillation from pretrained dynamic radiance fields. We evaluated DyLiN using both synthetic and real world datasets that include various non-rigid deformations. DyLiN qualitatively outperformed and quantitatively matched state-of-the-art methods in terms of visual fidelity, while being 25 - 71x computationally faster. We also tested CoDyLiN on attribute annotated data and it surpassed its teacher model. Project page: https://dylin2023.github.io .