 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Role of Spatial Mixing
Mar 21, 2025Until quite recently, the backbone of nearly every state-of-the-art computer vision model has been the 2D convolution. At its core, a 2D convolution simultaneously mixes information across both the spatial and channel dimensions of a representation. Many recent computer vision architectures consist of sequences of isotropic blocks that disentangle the spatial and channel-mixing components. This separation of the operations allows us to more closely juxtapose the effects of spatial and channel mixing in deep learning. In this paper, we take an initial step towards garnering a deeper understanding of the roles of these mixing operations. Through our experiments and analysis, we discover that on both classical (ResNet) and cutting-edge (ConvMixer) models, we can reach nearly the same level of classification performance by and leaving the spatial mixers at their random initializations. Furthermore, we show that models with random, fixed spatial mixing are naturally more robust to adversarial perturbations. Lastly, we show that this phenomenon extends past the classification regime, as such models can also decode pixel-shuffled images.
Gaussian Splatting LK
Jul 16, 2024Reconstructing dynamic 3D scenes from 2D images and generating diverse views over time presents a significant challenge due to the inherent complexity and temporal dynamics involved. While recent advancements in neural implicit models and dynamic Gaussian Splatting have shown promise, limitations persist, particularly in accurately capturing the underlying geometry of highly dynamic scenes. Some approaches address this by incorporating strong semantic and geometric priors through diffusion models. However, we explore a different avenue by investigating the potential of regularizing the native warp field within the dynamic Gaussian Splatting framework. Our method is grounded on the key intuition that an accurate warp field should produce continuous space-time motions. While enforcing the motion constraints on warp fields is non-trivial, we show that we can exploit knowledge innate to the forward warp field network to derive an analytical velocity field, then time integrate for scene flows to effectively constrain both the 2D motion and 3D positions of the Gaussians. This derived Lucas-Kanade style analytical regularization enables our method to achieve superior performance in reconstructing highly dynamic scenes, even under minimal camera movement, extending the boundaries of what existing dynamic Gaussian Splatting frameworks can achieve.
CoGS: Controllable Gaussian Splatting
Dec 09, 2023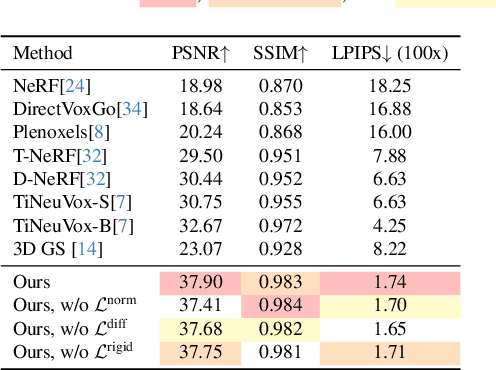
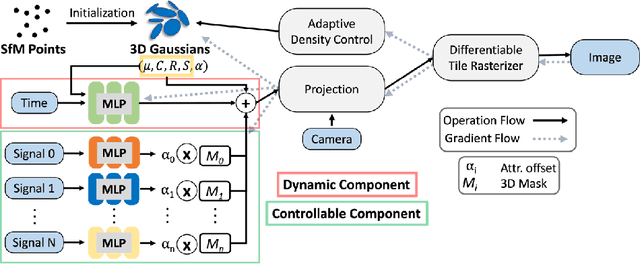
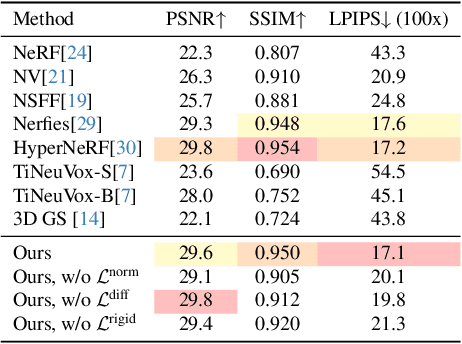
Capturing and re-animating the 3D structure of articulated objects present significant barriers. On one hand, methods requiring extensively calibrated multi-view setups are prohibitively complex and resource-intensive, limiting their practical applicability. On the other hand, while single-camera Neural Radiance Fields (NeRFs) offer a more streamlined approach, they have excessive training and rendering costs. 3D Gaussian Splatting would be a suitable alternative but for two reasons. Firstly, existing methods for 3D dynamic Gaussians require synchronized multi-view cameras, and secondly, the lack of controllability in dynamic scenarios. We present CoGS, a method for Controllable Gaussian Splatting, that enables the direct manipulation of scene elements, offering real-time control of dynamic scenes without the prerequisite of pre-computing control signals. We evaluated CoGS using both synthetic and real-world datasets that include dynamic objects that differ in degree of difficulty. In our evaluations, CoGS consistently outperformed existing dynamic and controllable neural representations in terms of visual fidelity.
DyLiN: Making Light Field Networks Dynamic
Mar 24, 2023



Light Field Networks, the re-formulations of radiance fields to oriented rays, are magnitudes faster than their coordinate network counterparts, and provide higher fidelity with respect to representing 3D structures from 2D observations. They would be well suited for generic scene representation and manipulation, but suffer from one problem: they are limited to holistic and static scenes. In this paper, we propose the Dynamic Light Field Network (DyLiN) method that can handle non-rigid deformations, including topological changes. We learn a deformation field from input rays to canonical rays, and lift them into a higher dimensional space to handle discontinuities. We further introduce CoDyLiN, which augments DyLiN with controllable attribute inputs. We train both models via knowledge distillation from pretrained dynamic radiance fields. We evaluated DyLiN using both synthetic and real world datasets that include various non-rigid deformations. DyLiN qualitatively outperformed and quantitatively matched state-of-the-art methods in terms of visual fidelity, while being 25 - 71x computationally faster. We also tested CoDyLiN on attribute annotated data and it surpassed its teacher model. Project page: https://dylin2023.github.io .