 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025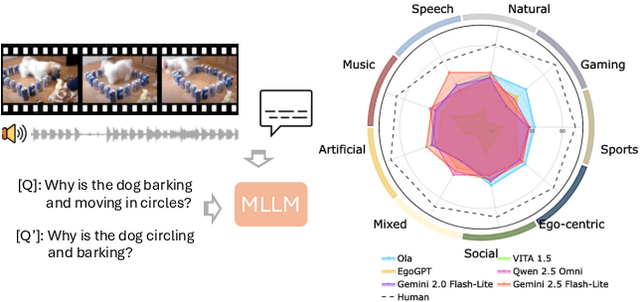
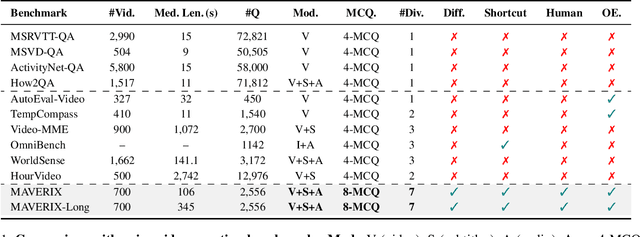
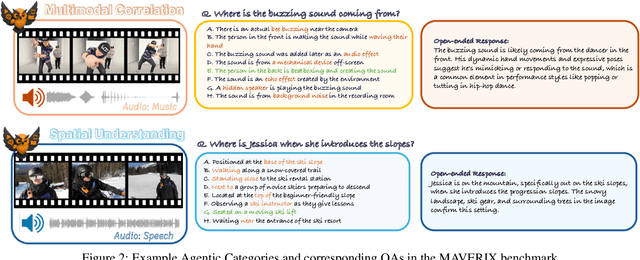
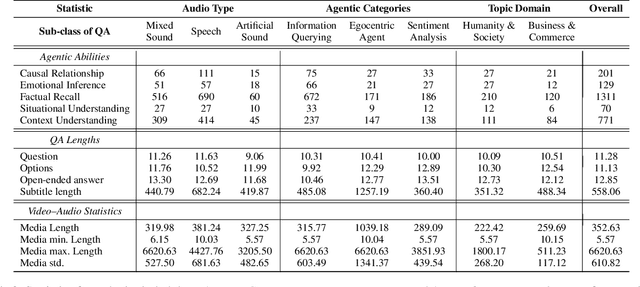
Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
AlignDiff: Learning Physically-Grounded Camera Alignment via Diffusion
Mar 27, 2025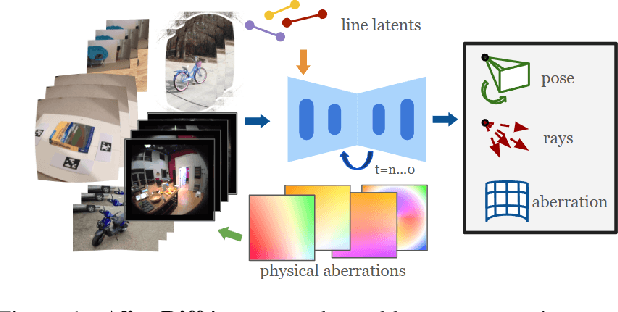
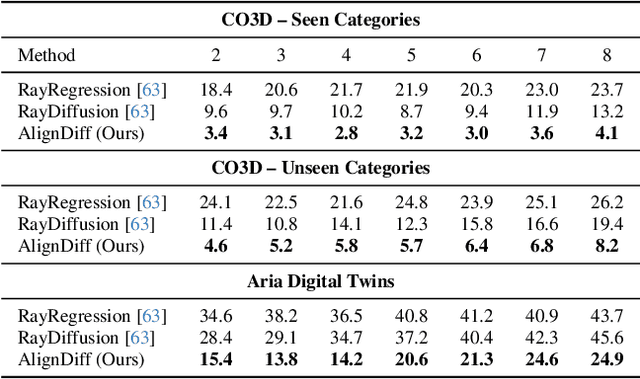
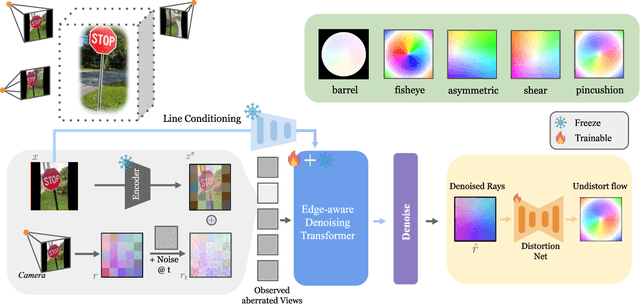
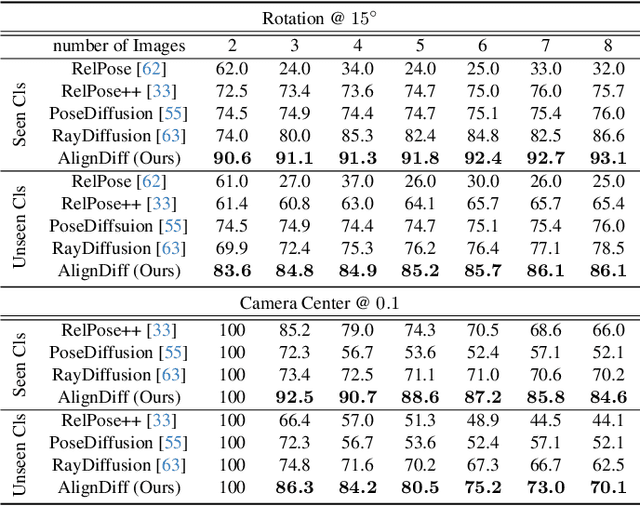
Accurate camera calibration is a fundamental task for 3D perception, especially when dealing with real-world, in-the-wild environments where complex optical distortions are common. Existing methods often rely on pre-rectified images or calibration patterns, which limits their applicability and flexibility. In this work, we introduce a novel framework that addresses these challenges by jointly modeling camera intrinsic and extrinsic parameters using a generic ray camera model. Unlike previous approaches, AlignDiff shifts focus from semantic to geometric features, enabling more accurate modeling of local distortions. We propose AlignDiff, a diffusion model conditioned on geometric priors, enabling the simultaneous estimation of camera distortions and scene geometry. To enhance distortion prediction, we incorporate edge-aware attention, focusing the model on geometric features around image edges, rather than semantic content. Furthermore, to enhance generalizability to real-world captures, we incorporate a large database of ray-traced lenses containing over three thousand samples. This database characterizes the distortion inherent in a diverse variety of lens forms. Our experiments demonstrate that the proposed method significantly reduces the angular error of estimated ray bundles by ~8.2 degrees and overall calibration accuracy, outperforming existing approaches on challenging, real-world datasets.
Through the Curved Cover: Synthesizing Cover Aberrated Scenes with Refractive Field
Nov 10, 2024
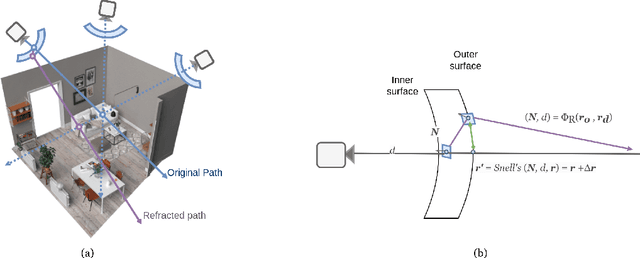


Recent extended reality headsets and field robots have adopted covers to protect the front-facing cameras from environmental hazards and falls. The surface irregularities on the cover can lead to optical aberrations like blurring and non-parametric distortions. Novel view synthesis methods like NeRF and 3D Gaussian Splatting are ill-equipped to synthesize from sequences with optical aberrations. To address this challenge, we introduce SynthCover to enable novel view synthesis through protective covers for downstream extended reality applications. SynthCover employs a Refractive Field that estimates the cover's geometry, enabling precise analytical calculation of refracted rays. Experiments on synthetic and real-world scenes demonstrate our method's ability to accurately model scenes viewed through protective covers, achieving a significant improvement in rendering quality compared to prior methods. We also show that the model can adjust well to various cover geometries with synthetic sequences captured with covers of different surface curvatures. To motivate further studies on this problem, we provide the benchmarked dataset containing real and synthetic walkable scenes captured with protective cover optical aberrations.
Gaussian Splatting LK
Jul 16, 2024Reconstructing dynamic 3D scenes from 2D images and generating diverse views over time presents a significant challenge due to the inherent complexity and temporal dynamics involved. While recent advancements in neural implicit models and dynamic Gaussian Splatting have shown promise, limitations persist, particularly in accurately capturing the underlying geometry of highly dynamic scenes. Some approaches address this by incorporating strong semantic and geometric priors through diffusion models. However, we explore a different avenue by investigating the potential of regularizing the native warp field within the dynamic Gaussian Splatting framework. Our method is grounded on the key intuition that an accurate warp field should produce continuous space-time motions. While enforcing the motion constraints on warp fields is non-trivial, we show that we can exploit knowledge innate to the forward warp field network to derive an analytical velocity field, then time integrate for scene flows to effectively constrain both the 2D motion and 3D positions of the Gaussians. This derived Lucas-Kanade style analytical regularization enables our method to achieve superior performance in reconstructing highly dynamic scenes, even under minimal camera movement, extending the boundaries of what existing dynamic Gaussian Splatting frameworks can achieve.
Component Segmentation of Engineering Drawings Using Graph Convolutional Networks
Dec 01, 2022



We present a data-driven framework to automate the vectorization and machine interpretation of 2D engineering part drawings. In industrial settings, most manufacturing engineers still rely on manual reads to identify the topological and manufacturing requirements from drawings submitted by designers. The interpretation process is laborious and time-consuming, which severely inhibits the efficiency of part quotation and manufacturing tasks. While recent advances in image-based computer vision methods have demonstrated great potential in interpreting natural images through semantic segmentation approaches, the application of such methods in parsing engineering technical drawings into semantically accurate components remains a significant challenge. The severe pixel sparsity in engineering drawings also restricts the effective featurization of image-based data-driven methods. To overcome these challenges, we propose a deep learning based framework that predicts the semantic type of each vectorized component. Taking a raster image as input, we vectorize all components through thinning, stroke tracing, and cubic bezier fitting. Then a graph of such components is generated based on the connectivity between the components. Finally, a graph convolutional neural network is trained on this graph data to identify the semantic type of each component. We test our framework in the context of semantic segmentation of text, dimension and, contour components in engineering drawings. Results show that our method yields the best performance compared to recent image, and graph-based segmentation methods.
Multi-Resolution Graph Neural Network for Large-Scale Pointcloud Segmentation
Sep 18, 2020
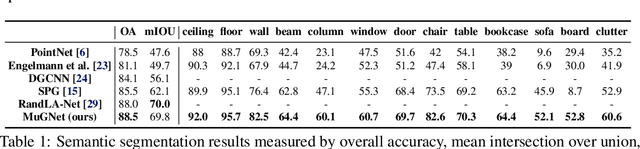
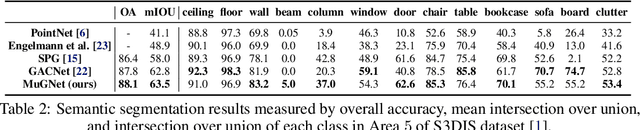
In this paper, we propose a multi-resolution deep-learning architecture to semantically segment dense large-scale pointclouds. Dense pointcloud data require a computationally expensive feature encoding process before semantic segmentation. Previous work has used different approaches to drastically downsample from the original pointcloud so common computing hardware can be utilized. While these approaches can relieve the computation burden to some extent, they are still limited in their processing capability for multiple scans. We present MuGNet, a memory-efficient, end-to-end graph neural network framework to perform semantic segmentation on large-scale pointclouds. We reduce the computation demand by utilizing a graph neural network on the preformed pointcloud graphs and retain the precision of the segmentation with a bidirectional network that fuses feature embedding at different resolutions. Our framework has been validated on benchmark datasets including Stanford Large-Scale 3D Indoor Spaces Dataset(S3DIS) and Virtual KITTI Dataset. We demonstrate that our framework can process up to 45 room scans at once on a single 11 GB GPU while still surpassing other graph-based solutions for segmentation on S3DIS with an 88.5\% (+3\%) overall accuracy and 69.8\% (+7.7\%) mIOU accuracy.