 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering autonomous quantum error correction via deep reinforcement learning
Nov 16, 2025Quantum error correction is essential for fault-tolerant quantum computing. However, standard methods relying on active measurements may introduce additional errors. Autonomous quantum error correction (AQEC) circumvents this by utilizing engineered dissipation and drives in bosonic systems, but identifying practical encoding remains challenging due to stringent Knill-Laflamme conditions. In this work, we utilize curriculum learning enabled deep reinforcement learning to discover Bosonic codes under approximate AQEC framework to resist both single-photon and double-photon losses. We present an analytical solution of solving the master equation under approximation conditions, which can significantly accelerate the training process of reinforcement learning. The agent first identifies an encoded subspace surpassing the breakeven point through rapid exploration within a constrained evolutionary time-frame, then strategically fine-tunes its policy to sustain this performance advantage over extended temporal horizons. We find that the two-phase trained agent can discover the optimal set of codewords, i.e., the Fock states $\ket{4}$ and $\ket{7}$ considering the effect of both single-photon and double-photon loss. We identify that the discovered code surpasses the breakeven threshold over a longer evolution time and achieve the state-of-art performance. We also analyze the robustness of the code against the phase damping and amplitude damping noise. Our work highlights the potential of curriculum learning enabled deep reinforcement learning in discovering the optimal quantum error correct code especially in early fault-tolerant quantum systems.
RefRef: A Synthetic Dataset and Benchmark for Reconstructing Refractive and Reflective Objects
May 09, 2025Modern 3D reconstruction and novel view synthesis approaches have demonstrated strong performance on scenes with opaque Lambertian objects. However, most assume straight light paths and therefore cannot properly handle refractive and reflective materials. Moreover, datasets specialized for these effects are limited, stymieing efforts to evaluate performance and develop suitable techniques. In this work, we introduce a synthetic RefRef dataset and benchmark for reconstructing scenes with refractive and reflective objects from posed images. Our dataset has 50 such objects of varying complexity, from single-material convex shapes to multi-material non-convex shapes, each placed in three different background types, resulting in 150 scenes. We also propose an oracle method that, given the object geometry and refractive indices, calculates accurate light paths for neural rendering, and an approach based on this that avoids these assumptions. We benchmark these against several state-of-the-art methods and show that all methods lag significantly behind the oracle, highlighting the challenges of the task and dataset.
Dynamic Learning and Productivity for Data Analysts: A Bayesian Hidden Markov Model Perspective
Mar 26, 2025Data analysts are essential in organizations, transforming raw data into insights that drive decision-making and strategy. This study explores how analysts' productivity evolves on a collaborative platform, focusing on two key learning activities: writing queries and viewing peer queries. While traditional research often assumes static models, where performance improves steadily with cumulative learning, such models fail to capture the dynamic nature of real-world learning. To address this, we propose a Hidden Markov Model (HMM) that tracks how analysts transition between distinct learning states based on their participation in these activities. Using an industry dataset with 2,001 analysts and 79,797 queries, this study identifies three learning states: novice, intermediate, and advanced. Productivity increases as analysts advance to higher states, reflecting the cumulative benefits of learning. Writing queries benefits analysts across all states, with the largest gains observed for novices. Viewing peer queries supports novices but may hinder analysts in higher states due to cognitive overload or inefficiencies. Transitions between states are also uneven, with progression from intermediate to advanced being particularly challenging. This study advances understanding of into dynamic learning behavior of knowledge worker and offers practical implications for designing systems, optimizing training, enabling personalized learning, and fostering effective knowledge sharing.
EL-MLFFs: Ensemble Learning of Machine Leaning Force Fields
Mar 26, 2024



Machine learning force fields (MLFFs) have emerged as a promising approach to bridge the accuracy of quantum mechanical methods and the efficiency of classical force fields. However, the abundance of MLFF models and the challenge of accurately predicting atomic forces pose significant obstacles in their practical application. In this paper, we propose a novel ensemble learning framework, EL-MLFFs, which leverages the stacking method to integrate predictions from diverse MLFFs and enhance force prediction accuracy. By constructing a graph representation of molecular structures and employing a graph neural network (GNN) as the meta-model, EL-MLFFs effectively captures atomic interactions and refines force predictions. We evaluate our approach on two distinct datasets: methane molecules and methanol adsorbed on a Cu(100) surface. The results demonstrate that EL-MLFFs significantly improves force prediction accuracy compared to individual MLFFs, with the ensemble of all eight models yielding the best performance. Moreover, our ablation study highlights the crucial roles of the residual network and graph attention layers in the model's architecture. The EL-MLFFs framework offers a promising solution to the challenges of model selection and force prediction accuracy in MLFFs, paving the way for more reliable and efficient molecular simulations.
Component Segmentation of Engineering Drawings Using Graph Convolutional Networks
Dec 01, 2022



We present a data-driven framework to automate the vectorization and machine interpretation of 2D engineering part drawings. In industrial settings, most manufacturing engineers still rely on manual reads to identify the topological and manufacturing requirements from drawings submitted by designers. The interpretation process is laborious and time-consuming, which severely inhibits the efficiency of part quotation and manufacturing tasks. While recent advances in image-based computer vision methods have demonstrated great potential in interpreting natural images through semantic segmentation approaches, the application of such methods in parsing engineering technical drawings into semantically accurate components remains a significant challenge. The severe pixel sparsity in engineering drawings also restricts the effective featurization of image-based data-driven methods. To overcome these challenges, we propose a deep learning based framework that predicts the semantic type of each vectorized component. Taking a raster image as input, we vectorize all components through thinning, stroke tracing, and cubic bezier fitting. Then a graph of such components is generated based on the connectivity between the components. Finally, a graph convolutional neural network is trained on this graph data to identify the semantic type of each component. We test our framework in the context of semantic segmentation of text, dimension and, contour components in engineering drawings. Results show that our method yields the best performance compared to recent image, and graph-based segmentation methods.
RecipeSnap -- a lightweight image-to-recipe model
May 04, 2022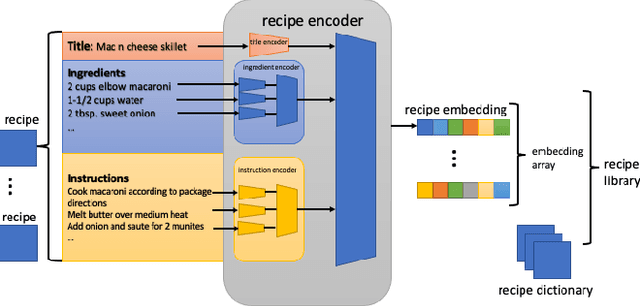
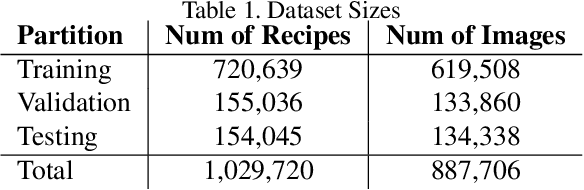
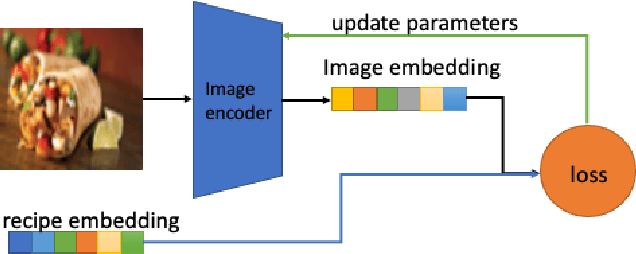
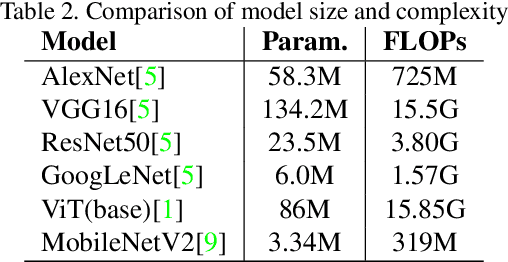
In this paper we want to address the problem of automation for recognition of photographed cooking dishes and generating the corresponding food recipes. Current image-to-recipe models are computation expensive and require powerful GPUs for model training and implementation. High computational cost prevents those existing models from being deployed on portable devices, like smart phones. To solve this issue we introduce a lightweight image-to-recipe prediction model, RecipeSnap, that reduces memory cost and computational cost by more than 90% while still achieving 2.0 MedR, which is in line with the state-of-the-art model. A pre-trained recipe encoder was used to compute recipe embeddings. Recipes from Recipe1M dataset and corresponding recipe embeddings are collected as a recipe library, which are used for image encoder training and image query later. We use MobileNet-V2 as image encoder backbone, which makes our model suitable to portable devices. This model can be further developed into an application for smart phones with a few effort. A comparison of the performance between this lightweight model to other heavy models are presented in this paper. Code, data and models are publicly accessible on github.
SerialTrack: ScalE and Rotation Invariant Augmented Lagrangian Particle Tracking
Mar 23, 2022
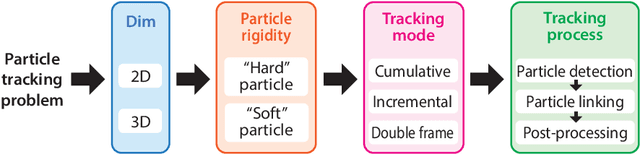
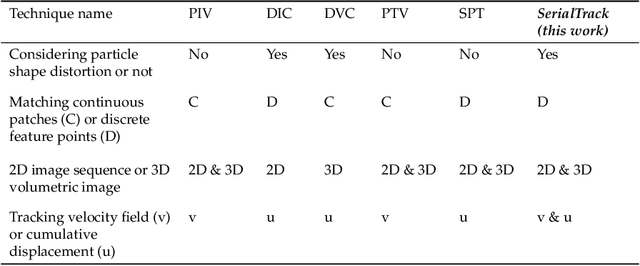
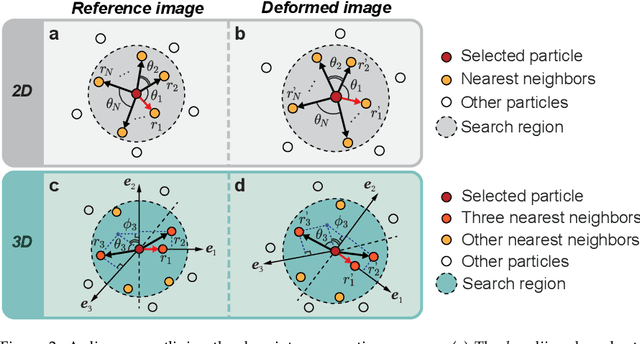
We present a new particle tracking algorithm to accurately resolve large deformation and rotational motion fields, which takes advantage of both local and global particle tracking algorithms. We call this method the ScalE and Rotation Invariant Augmented Lagrangian Particle Tracking (SerialTrack). This method builds an iterative scale and rotation invariant topology-based feature for each particle within a multi-scale tracking algorithm. The global kinematic compatibility condition is applied as a global augmented Lagrangian constraint to enhance the tracking accuracy. An open source software package implementing this numerical approach to track both 2D and 3D, incremental and cumulative deformation fields is provided.
A Model-Agnostic Causal Learning Framework for Recommendation using Search Data
Feb 10, 2022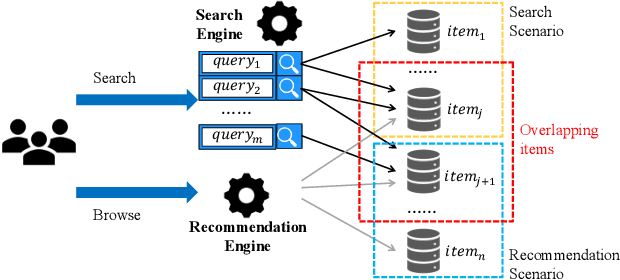
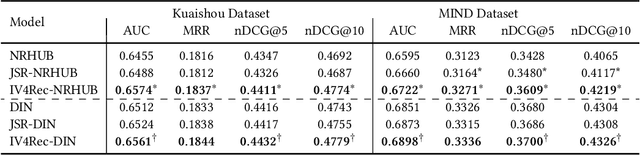
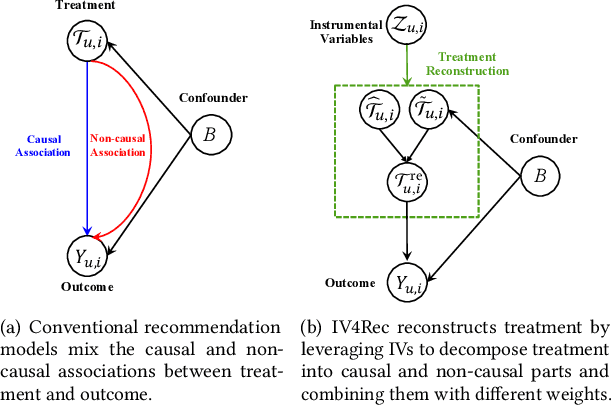

Machine-learning based recommender systems(RSs) has become an effective means to help people automatically discover their interests. Existing models often represent the rich information for recommendation, such as items, users, and contexts, as embedding vectors and leverage them to predict users' feedback. In the view of causal analysis, the associations between these embedding vectors and users' feedback are a mixture of the causal part that describes why an item is preferred by a user, and the non-causal part that merely reflects the statistical dependencies between users and items, for example, the exposure mechanism, public opinions, display position, etc. However, existing RSs mostly ignored the striking differences between the causal parts and non-causal parts when using these embedding vectors. In this paper, we propose a model-agnostic framework named IV4Rec that can effectively decompose the embedding vectors into these two parts, hence enhancing recommendation results. Specifically, we jointly consider users' behaviors in search scenarios and recommendation scenarios. Adopting the concepts in causal analysis, we embed users' search behaviors as instrumental variables (IVs), to help decompose original embedding vectors in recommendation, i.e., treatments. IV4Rec then combines the two parts through deep neural networks and uses the combined results for recommendation. IV4Rec is model-agnostic and can be applied to a number of existing RSs such as DIN and NRHUB. Experimental results on both public and proprietary industrial datasets demonstrate that IV4Rec consistently enhances RSs and outperforms a framework that jointly considers search and recommendation.
Duluth at SemEval-2020 Task 7: Using Surprise as a Key to Unlock Humorous Headlines
Sep 06, 2020
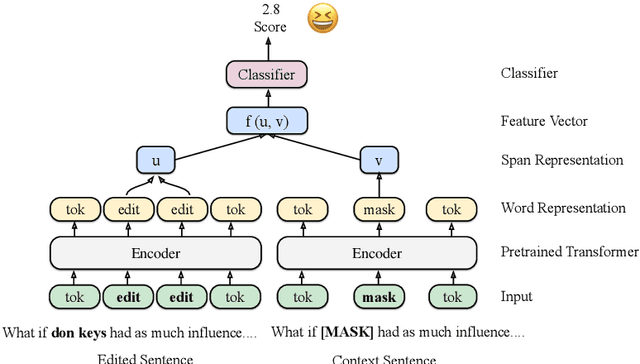
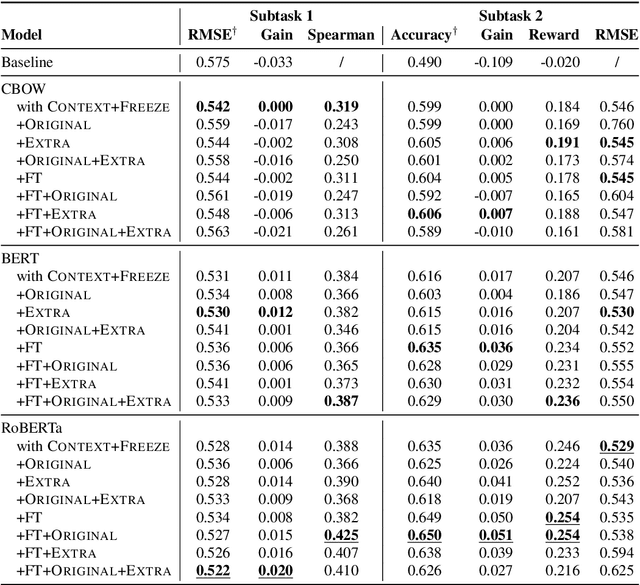
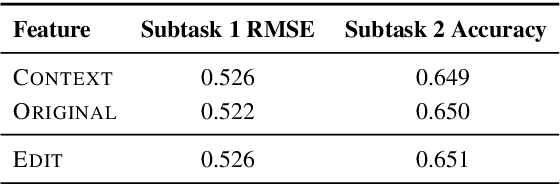
We use pretrained transformer-based language models in SemEval-2020 Task 7: Assessing the Funniness of Edited News Headlines. Inspired by the incongruity theory of humor, we use a contrastive approach to capture the surprise in the edited headlines. In the official evaluation, our system gets 0.531 RMSE in Subtask 1, 11th among 49 submissions. In Subtask 2, our system gets 0.632 accuracy, 9th among 32 submissions.
Cross-language Citation Recommendation via Hierarchical Representation Learning on Heterogeneous Graph
Dec 31, 2018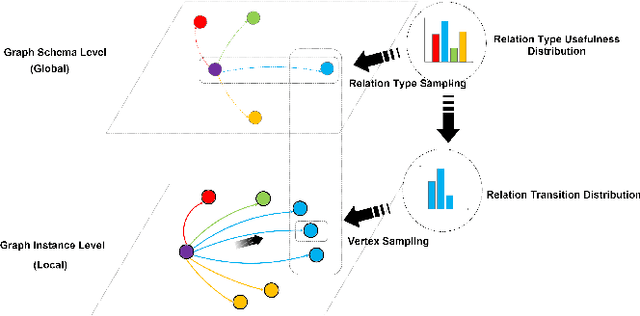

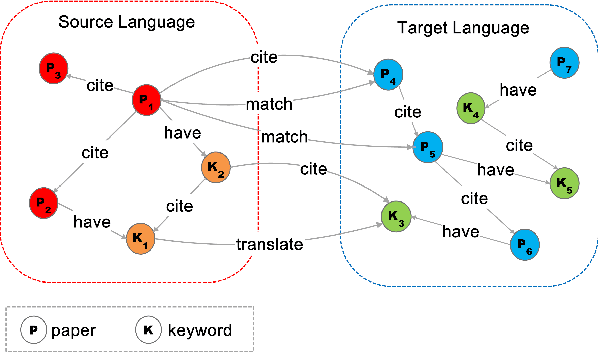
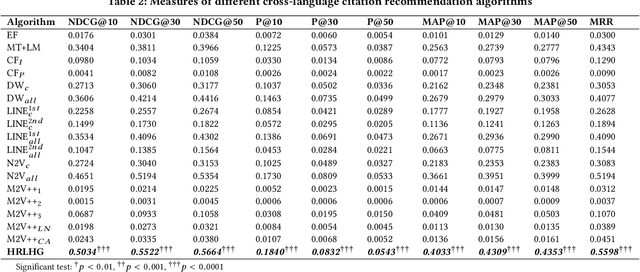
While the volume of scholarly publications has increased at a frenetic pace, accessing and consuming the useful candidate papers, in very large digital libraries, is becoming an essential and challenging task for scholars. Unfortunately, because of language barrier, some scientists (especially the junior ones or graduate students who do not master other languages) cannot efficiently locate the publications hosted in a foreign language repository. In this study, we propose a novel solution, cross-language citation recommendation via Hierarchical Representation Learning on Heterogeneous Graph (HRLHG), to address this new problem. HRLHG can learn a representation function by mapping the publications, from multilingual repositories, to a low-dimensional joint embedding space from various kinds of vertexes and relations on a heterogeneous graph. By leveraging both global (task specific) plus local (task independent) information as well as a novel supervised hierarchical random walk algorithm, the proposed method can optimize the publication representations by maximizing the likelihood of locating the important cross-language neighborhoods on the graph. Experiment results show that the proposed method can not only outperform state-of-the-art baseline models, but also improve the interpretability of the representation model for cross-language citation recommendation task.