 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuluth at SemEval-2025 Task 7: TF-IDF with Optimized Vector Dimensions for Multilingual Fact-Checked Claim Retrieval
May 19, 2025This paper presents the Duluth approach to the SemEval-2025 Task 7 on Multilingual and Crosslingual Fact-Checked Claim Retrieval. We implemented a TF-IDF-based retrieval system with experimentation on vector dimensions and tokenization strategies. Our best-performing configuration used word-level tokenization with a vocabulary size of 15,000 features, achieving an average success@10 score of 0.78 on the development set and 0.69 on the test set across ten languages. Our system showed stronger performance on higher-resource languages but still lagged significantly behind the top-ranked system, which achieved 0.96 average success@10. Our findings suggest that though advanced neural architectures are increasingly dominant in multilingual retrieval tasks, properly optimized traditional methods like TF-IDF remain competitive baselines, especially in limited compute resource scenarios.
SemEval-2021 Task 11: NLPContributionGraph -- Structuring Scholarly NLP Contributions for a Research Knowledge Graph
Jul 06, 2021



There is currently a gap between the natural language expression of scholarly publications and their structured semantic content modeling to enable intelligent content search. With the volume of research growing exponentially every year, a search feature operating over semantically structured content is compelling. The SemEval-2021 Shared Task NLPContributionGraph (a.k.a. 'the NCG task') tasks participants to develop automated systems that structure contributions from NLP scholarly articles in the English language. Being the first-of-its-kind in the SemEval series, the task released structured data from NLP scholarly articles at three levels of information granularity, i.e. at sentence-level, phrase-level, and phrases organized as triples toward Knowledge Graph (KG) building. The sentence-level annotations comprised the few sentences about the article's contribution. The phrase-level annotations were scientific term and predicate phrases from the contribution sentences. Finally, the triples constituted the research overview KG. For the Shared Task, participating systems were then expected to automatically classify contribution sentences, extract scientific terms and relations from the sentences, and organize them as KG triples. Overall, the task drew a strong participation demographic of seven teams and 27 participants. The best end-to-end task system classified contribution sentences at 57.27% F1, phrases at 46.41% F1, and triples at 22.28% F1. While the absolute performance to generate triples remains low, in the conclusion of this article, the difficulty of producing such data and as a consequence of modeling it is highlighted.
Duluth at SemEval-2020 Task 7: Using Surprise as a Key to Unlock Humorous Headlines
Sep 06, 2020
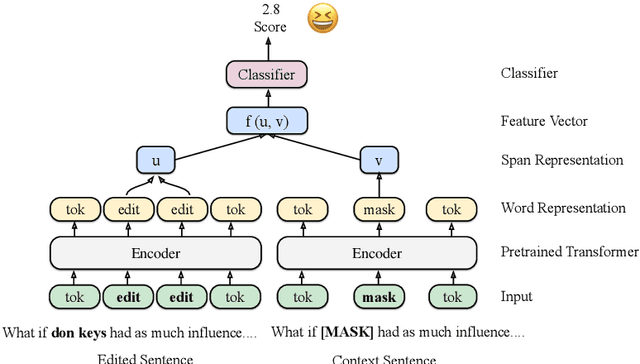
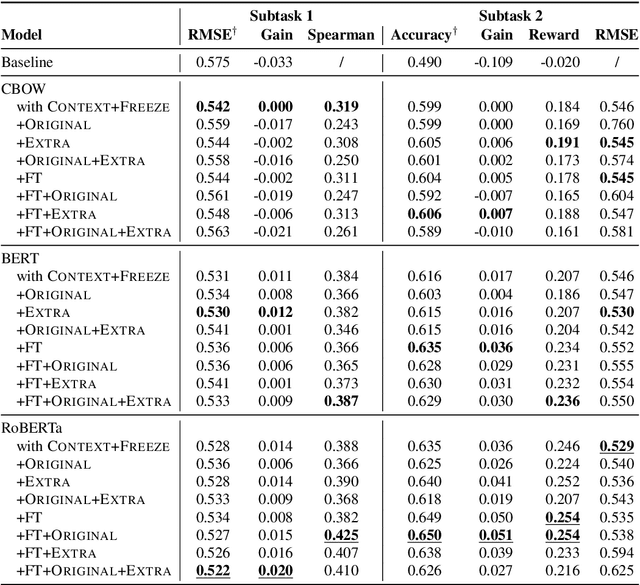
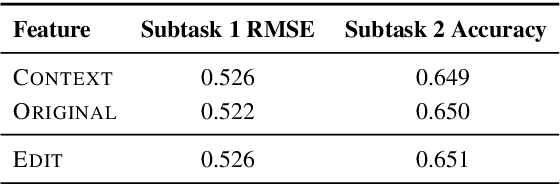
We use pretrained transformer-based language models in SemEval-2020 Task 7: Assessing the Funniness of Edited News Headlines. Inspired by the incongruity theory of humor, we use a contrastive approach to capture the surprise in the edited headlines. In the official evaluation, our system gets 0.531 RMSE in Subtask 1, 11th among 49 submissions. In Subtask 2, our system gets 0.632 accuracy, 9th among 32 submissions.
Duluth at SemEval-2019 Task 6: Lexical Approaches to Identify and Categorize Offensive Tweets
Jul 25, 2020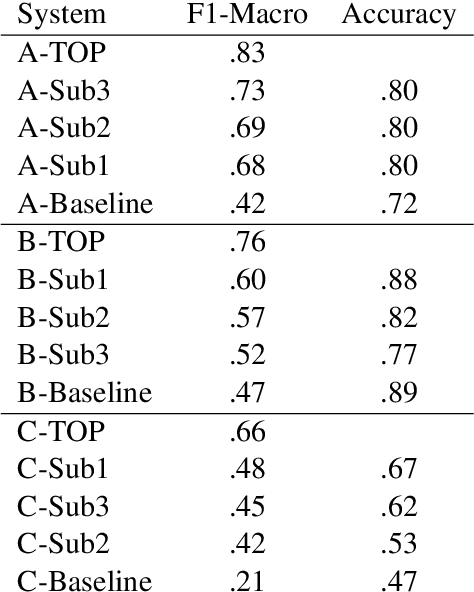
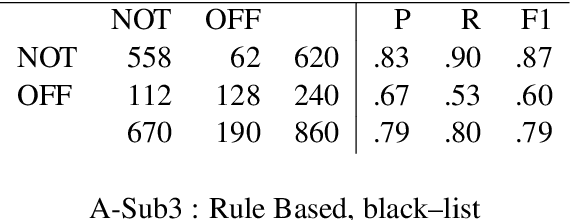

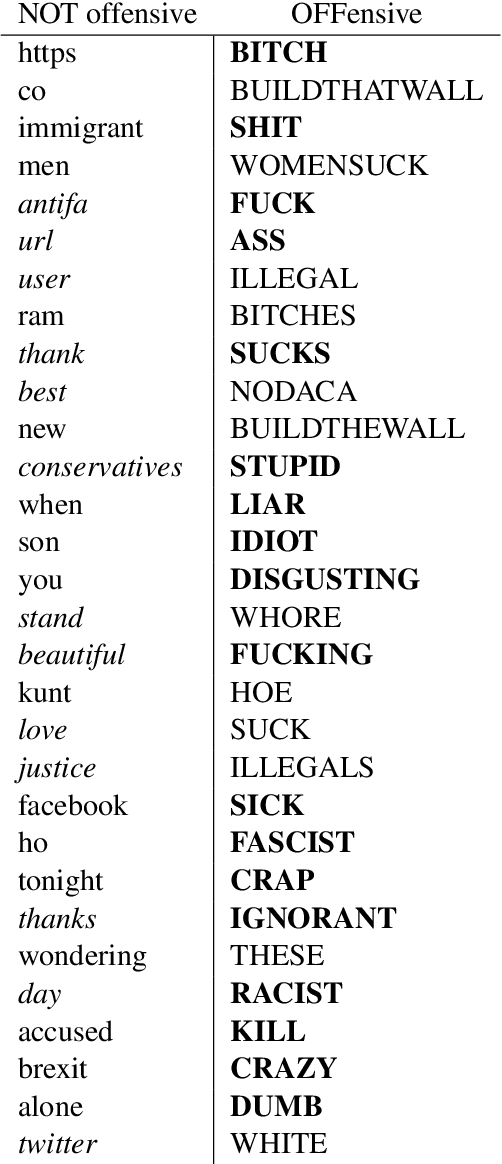
This paper describes the Duluth systems that participated in SemEval--2019 Task 6, Identifying and Categorizing Offensive Language in Social Media (OffensEval). For the most part these systems took traditional Machine Learning approaches that built classifiers from lexical features found in manually labeled training data. However, our most successful system for classifying a tweet as offensive (or not) was a rule-based black--list approach, and we also experimented with combining the training data from two different but related SemEval tasks. Our best systems in each of the three OffensEval tasks placed in the middle of the comparative evaluation, ranking 57th of 103 in task A, 39th of 75 in task B, and 44th of 65 in task C.
Duluth at SemEval-2020 Task 12: Offensive Tweet Identification in English with Logistic Regression
Jul 25, 2020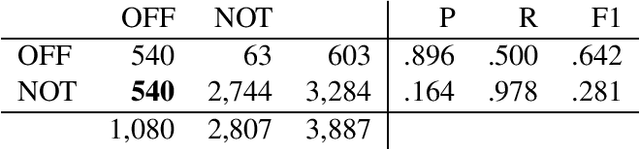
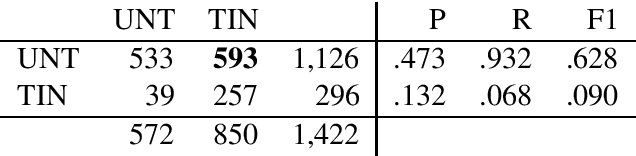
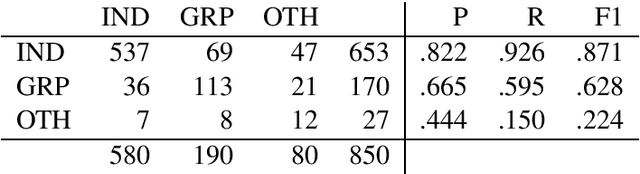

This paper describes the Duluth systems that participated in SemEval--2020 Task 12, Multilingual Offensive Language Identification in Social Media (OffensEval--2020). We participated in the three English language tasks. Our systems provide a simple Machine Learning baseline using logistic regression. We trained our models on the distantly supervised training data made available by the task organizers and used no other resources. As might be expected we did not rank highly in the comparative evaluation: 79th of 85 in Task A, 34th of 43 in Task B, and 24th of 39 in Task C. We carried out a qualitative analysis of our results and found that the class labels in the gold standard data are somewhat noisy. We hypothesize that the extremely high accuracy (> 90%) of the top ranked systems may reflect methods that learn the training data very well but may not generalize to the task of identifying offensive language in English. This analysis includes examples of tweets that despite being mildly redacted are still offensive.
UMDSub at SemEval-2018 Task 2: Multilingual Emoji Prediction Multi-channel Convolutional Neural Network on Subword Embedding
May 25, 2018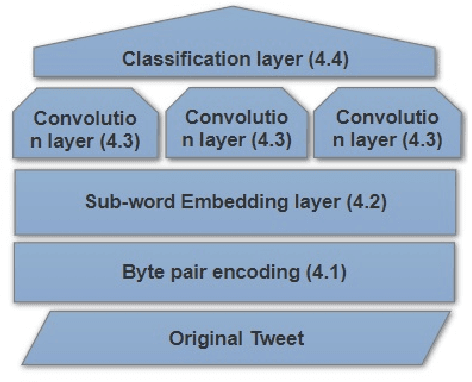
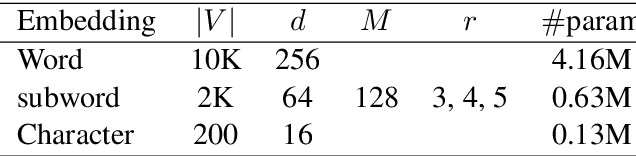
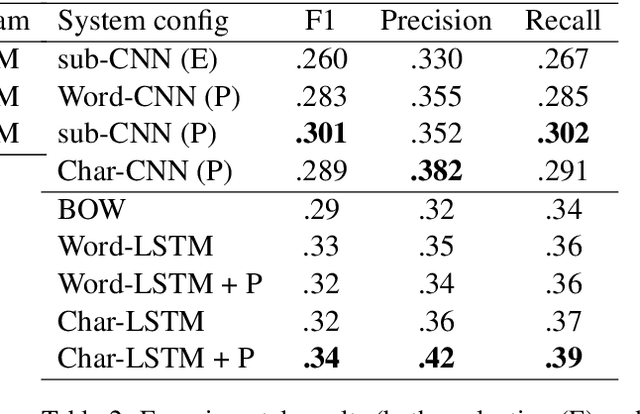
This paper describes the UMDSub system that participated in Task 2 of SemEval-2018. We developed a system that predicts an emoji given the raw text in a English tweet. The system is a Multi-channel Convolutional Neural Network based on subword embeddings for the representation of tweets. This model improves on character or word based methods by about 2\%. Our system placed 21st of 48 participating systems in the official evaluation.
UMDuluth-CS8761 at SemEval-2018 Task 9: Hypernym Discovery using Hearst Patterns, Co-occurrence frequencies and Word Embeddings
May 25, 2018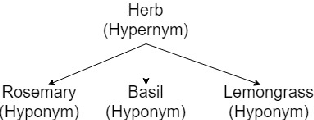
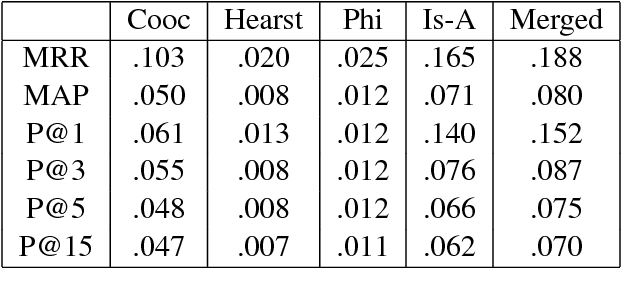


Hypernym Discovery is the task of identifying potential hypernyms for a given term. A hypernym is a more generalized word that is super-ordinate to more specific words. This paper explores several approaches that rely on co-occurrence frequencies of word pairs, Hearst Patterns based on regular expressions, and word embeddings created from the UMBC corpus. Our system Babbage participated in Subtask 1A for English and placed 6th of 19 systems when identifying concept hypernyms, and 12th of 18 systems for entity hypernyms.
Duluth UROP at SemEval-2018 Task 2: Multilingual Emoji Prediction with Ensemble Learning and Oversampling
May 25, 2018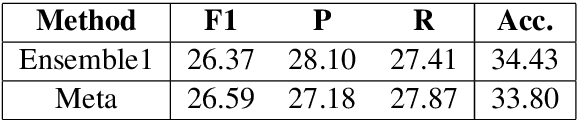

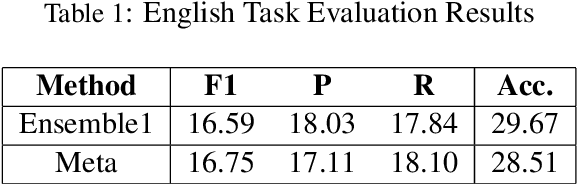

This paper describes the Duluth UROP systems that participated in SemEval--2018 Task 2, Multilingual Emoji Prediction. We relied on a variety of ensembles made up of classifiers using Naive Bayes, Logistic Regression, and Random Forests. We used unigram and bigram features and tried to offset the skewness of the data through the use of oversampling. Our task evaluation results place us 19th of 48 systems in the English evaluation, and 5th of 21 in the Spanish. After the evaluation we realized that some simple changes to preprocessing could significantly improve our results. After making these changes we attained results that would have placed us sixth in the English evaluation, and second in the Spanish.
Who's to say what's funny? A computer using Language Models and Deep Learning, That's Who!
May 29, 2017
Humor is a defining characteristic of human beings. Our goal is to develop methods that automatically detect humorous statements and rank them on a continuous scale. In this paper we report on results using a Language Model approach, and outline our plans for using methods from Deep Learning.
Improving Correlation with Human Judgments by Integrating Semantic Similarity with Second--Order Vectors
May 27, 2017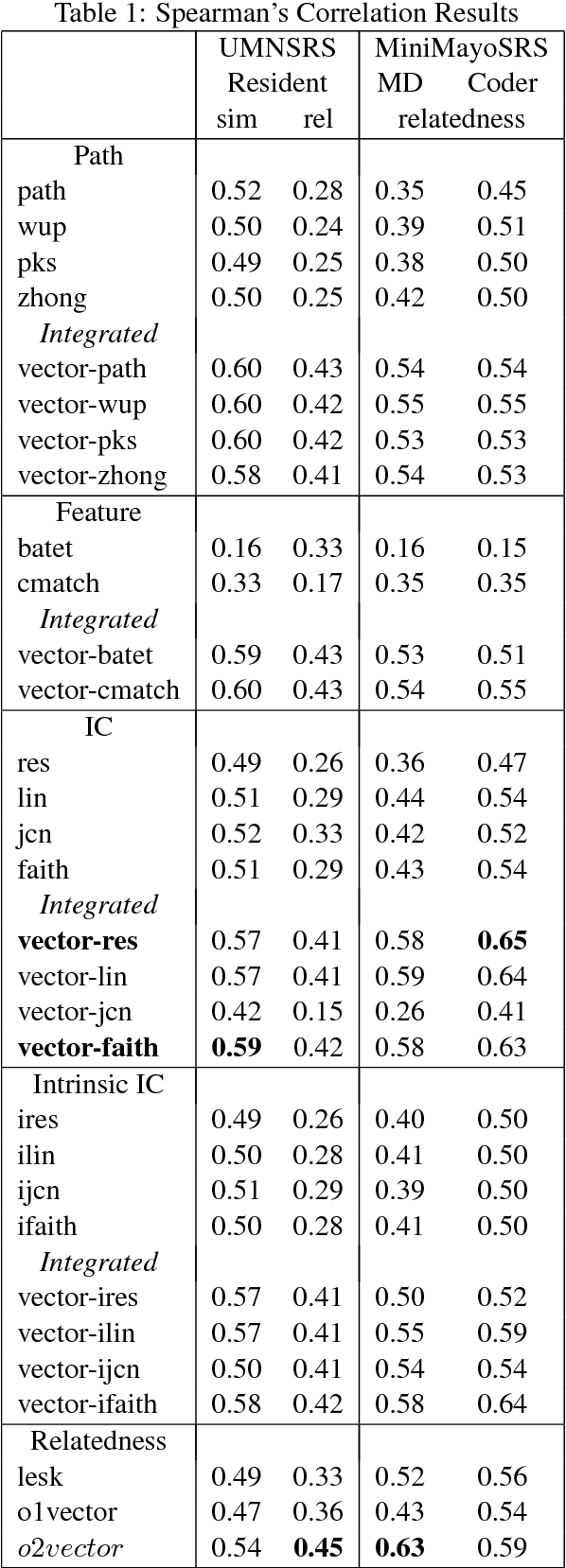
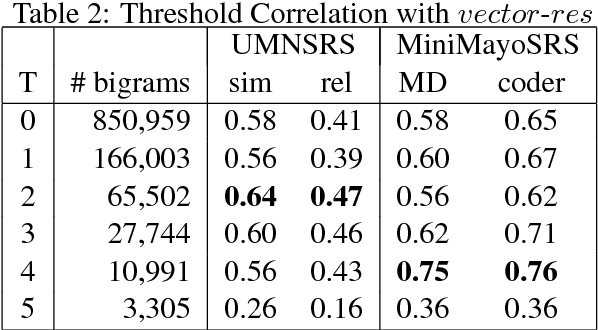


Vector space methods that measure semantic similarity and relatedness often rely on distributional information such as co--occurrence frequencies or statistical measures of association to weight the importance of particular co--occurrences. In this paper, we extend these methods by incorporating a measure of semantic similarity based on a human curated taxonomy into a second--order vector representation. This results in a measure of semantic relatedness that combines both the contextual information available in a corpus--based vector space representation with the semantic knowledge found in a biomedical ontology. Our results show that incorporating semantic similarity into a second order co--occurrence matrices improves correlation with human judgments for both similarity and relatedness, and that our method compares favorably to various different word embedding methods that have recently been evaluated on the same reference standards we have used.