 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuluth at SemEval-2020 Task 12: Offensive Tweet Identification in English with Logistic Regression
Paper and Code
Jul 25, 2020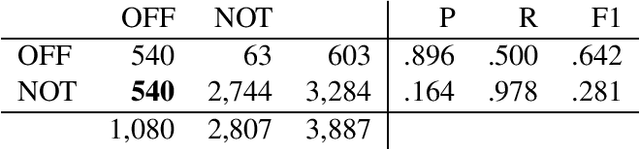
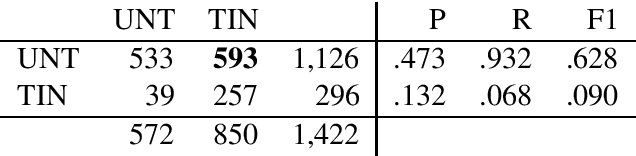
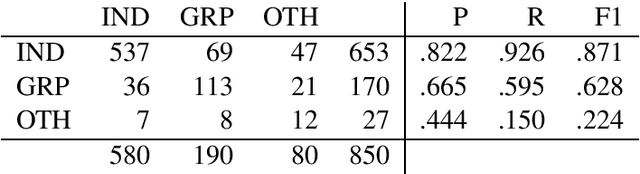

This paper describes the Duluth systems that participated in SemEval--2020 Task 12, Multilingual Offensive Language Identification in Social Media (OffensEval--2020). We participated in the three English language tasks. Our systems provide a simple Machine Learning baseline using logistic regression. We trained our models on the distantly supervised training data made available by the task organizers and used no other resources. As might be expected we did not rank highly in the comparative evaluation: 79th of 85 in Task A, 34th of 43 in Task B, and 24th of 39 in Task C. We carried out a qualitative analysis of our results and found that the class labels in the gold standard data are somewhat noisy. We hypothesize that the extremely high accuracy (> 90%) of the top ranked systems may reflect methods that learn the training data very well but may not generalize to the task of identifying offensive language in English. This analysis includes examples of tweets that despite being mildly redacted are still offensive.