 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Correlation with Human Judgments by Integrating Semantic Similarity with Second--Order Vectors
Paper and Code
May 27, 2017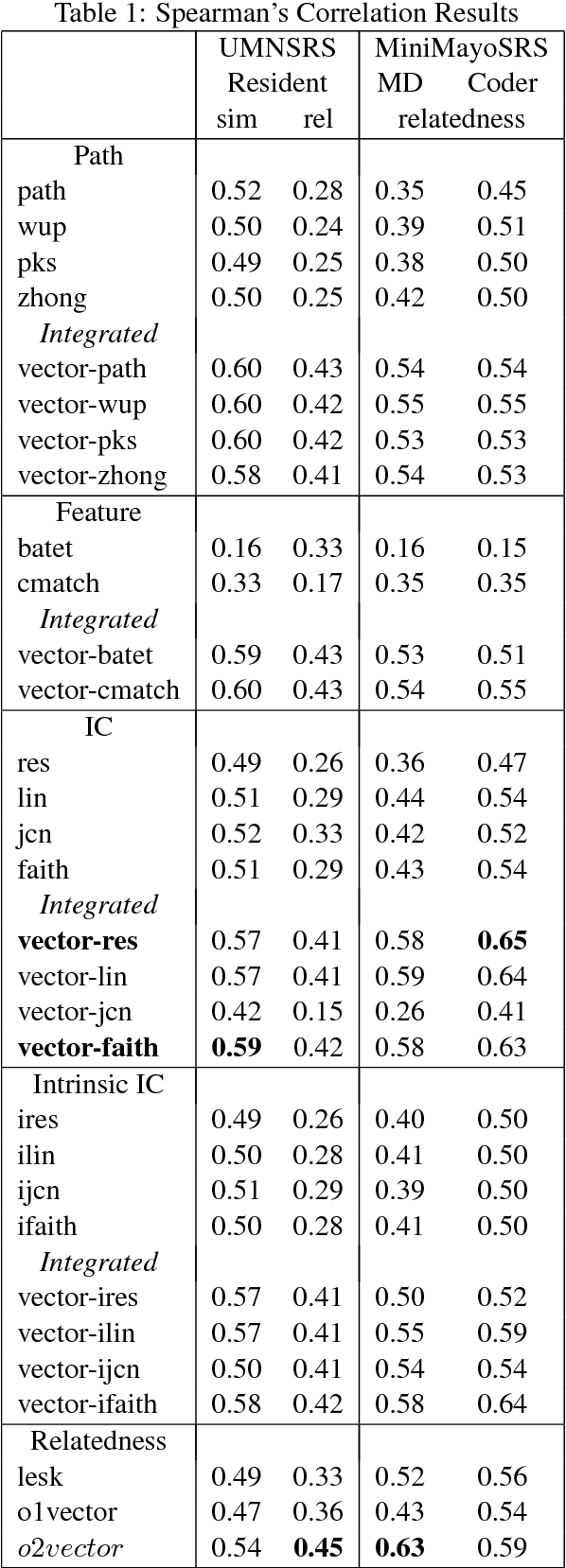
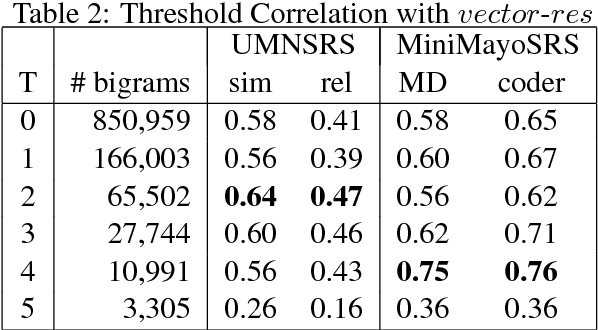


Vector space methods that measure semantic similarity and relatedness often rely on distributional information such as co--occurrence frequencies or statistical measures of association to weight the importance of particular co--occurrences. In this paper, we extend these methods by incorporating a measure of semantic similarity based on a human curated taxonomy into a second--order vector representation. This results in a measure of semantic relatedness that combines both the contextual information available in a corpus--based vector space representation with the semantic knowledge found in a biomedical ontology. Our results show that incorporating semantic similarity into a second order co--occurrence matrices improves correlation with human judgments for both similarity and relatedness, and that our method compares favorably to various different word embedding methods that have recently been evaluated on the same reference standards we have used.