 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuluth at SemEval-2020 Task 7: Using Surprise as a Key to Unlock Humorous Headlines
Sep 06, 2020
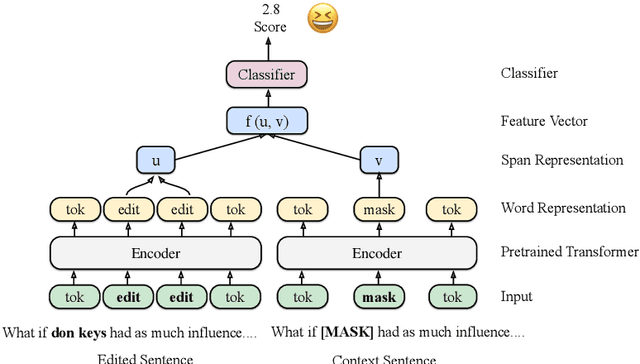
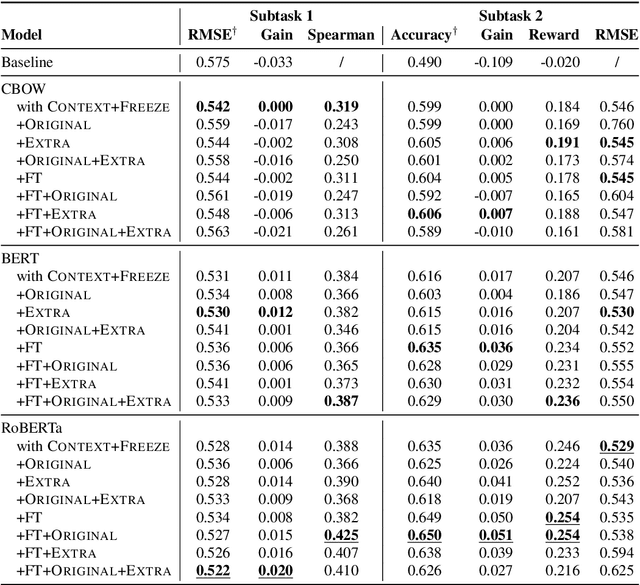
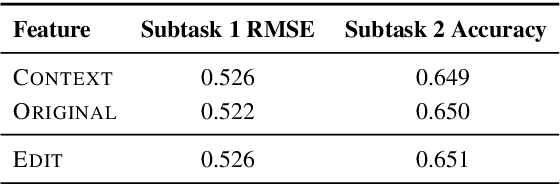
We use pretrained transformer-based language models in SemEval-2020 Task 7: Assessing the Funniness of Edited News Headlines. Inspired by the incongruity theory of humor, we use a contrastive approach to capture the surprise in the edited headlines. In the official evaluation, our system gets 0.531 RMSE in Subtask 1, 11th among 49 submissions. In Subtask 2, our system gets 0.632 accuracy, 9th among 32 submissions.
Discrete Latent Variable Representations for Low-Resource Text Classification
Jun 11, 2020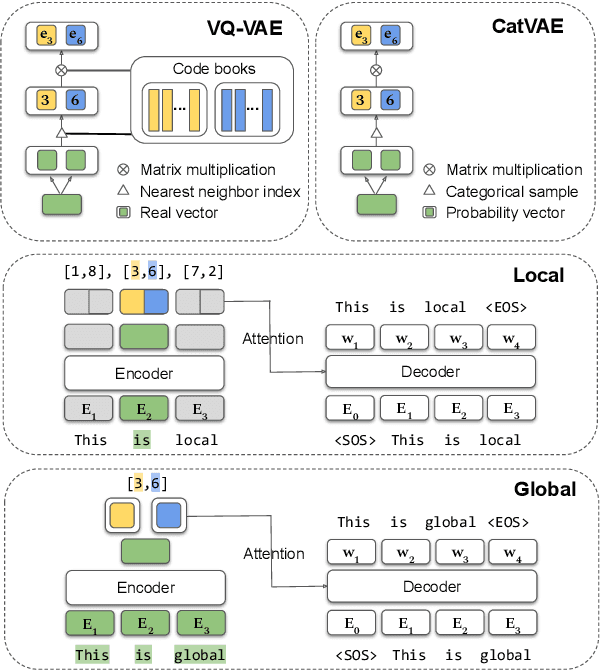
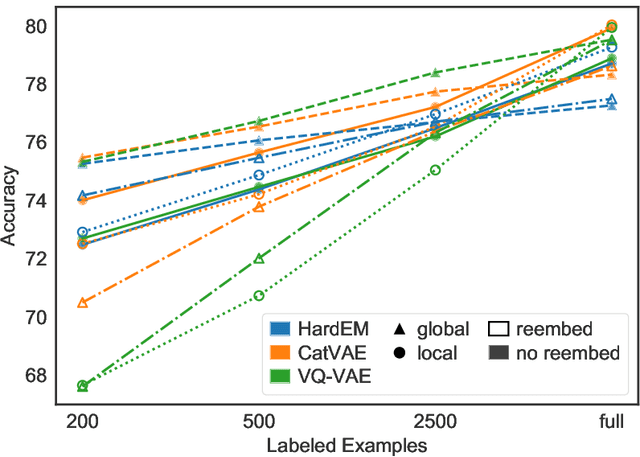
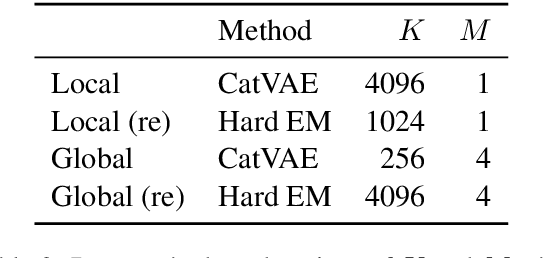
While much work on deep latent variable models of text uses continuous latent variables, discrete latent variables are interesting because they are more interpretable and typically more space efficient. We consider several approaches to learning discrete latent variable models for text in the case where exact marginalization over these variables is intractable. We compare the performance of the learned representations as features for low-resource document and sentence classification. Our best models outperform the previous best reported results with continuous representations in these low-resource settings, while learning significantly more compressed representations. Interestingly, we find that an amortized variant of Hard EM performs particularly well in the lowest-resource regimes.
Looking for ELMo's friends: Sentence-Level Pretraining Beyond Language Modeling
Dec 28, 2018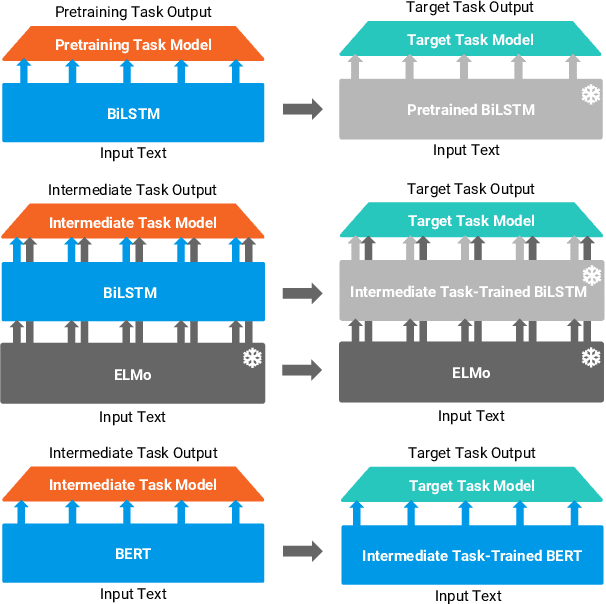
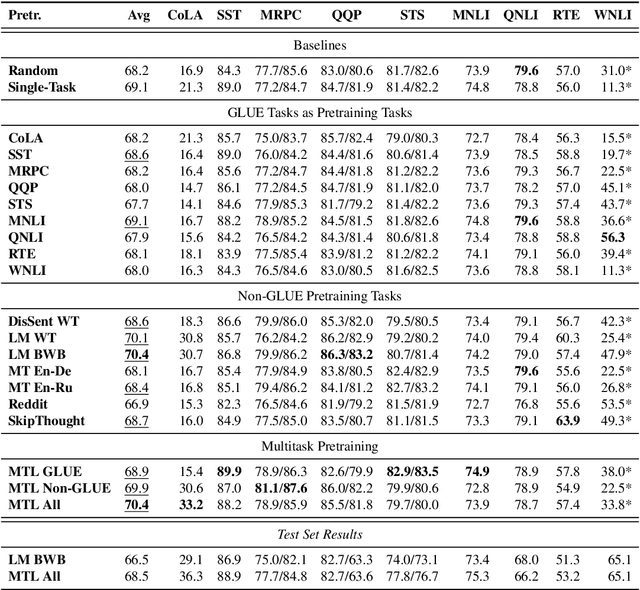
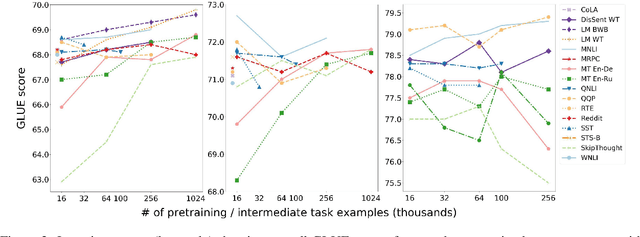
Work on the problem of contextualized word representation -- the development of reusable neural network components for sentence understanding -- has recently seen a surge of progress centered on the unsupervised pretraining task of language modeling with methods like ELMo. This paper contributes the first large-scale systematic study comparing different pretraining tasks in this context, both as complements to language modeling and as potential alternatives. The primary results of the study support the use of language modeling as a pretraining task and set a new state of the art among comparable models using multitask learning with language models. However, a closer look at these results reveals worryingly strong baselines and strikingly varied results across target tasks, suggesting that the widely-used paradigm of pretraining and freezing sentence encoders may not be an ideal platform for further work.
Duluth UROP at SemEval-2018 Task 2: Multilingual Emoji Prediction with Ensemble Learning and Oversampling
May 25, 2018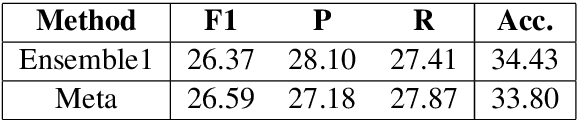

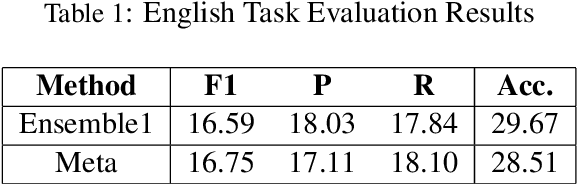

This paper describes the Duluth UROP systems that participated in SemEval--2018 Task 2, Multilingual Emoji Prediction. We relied on a variety of ensembles made up of classifiers using Naive Bayes, Logistic Regression, and Random Forests. We used unigram and bigram features and tried to offset the skewness of the data through the use of oversampling. Our task evaluation results place us 19th of 48 systems in the English evaluation, and 5th of 21 in the Spanish. After the evaluation we realized that some simple changes to preprocessing could significantly improve our results. After making these changes we attained results that would have placed us sixth in the English evaluation, and second in the Spanish.