 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenCzechMark : A Czech-centric Multitask and Multimetric Benchmark for Large Language Models with Duel Scoring Mechanism
Dec 23, 2024



We present BenCzechMark (BCM), the first comprehensive Czech language benchmark designed for large language models, offering diverse tasks, multiple task formats, and multiple evaluation metrics. Its scoring system is grounded in statistical significance theory and uses aggregation across tasks inspired by social preference theory. Our benchmark encompasses 50 challenging tasks, with corresponding test datasets, primarily in native Czech, with 11 newly collected ones. These tasks span 8 categories and cover diverse domains, including historical Czech news, essays from pupils or language learners, and spoken word. Furthermore, we collect and clean BUT-Large Czech Collection, the largest publicly available clean Czech language corpus, and use it for (i) contamination analysis, (ii) continuous pretraining of the first Czech-centric 7B language model, with Czech-specific tokenization. We use our model as a baseline for comparison with publicly available multilingual models. Lastly, we release and maintain a leaderboard, with existing 44 model submissions, where new model submissions can be made at https://huggingface.co/spaces/CZLC/BenCzechMark.
Towards an Understanding of Stepwise Inference in Transformers: A Synthetic Graph Navigation Model
Feb 12, 2024Stepwise inference protocols, such as scratchpads and chain-of-thought, help language models solve complex problems by decomposing them into a sequence of simpler subproblems. Despite the significant gain in performance achieved via these protocols, the underlying mechanisms of stepwise inference have remained elusive. To address this, we propose to study autoregressive Transformer models on a synthetic task that embodies the multi-step nature of problems where stepwise inference is generally most useful. Specifically, we define a graph navigation problem wherein a model is tasked with traversing a path from a start to a goal node on the graph. Despite is simplicity, we find we can empirically reproduce and analyze several phenomena observed at scale: (i) the stepwise inference reasoning gap, the cause of which we find in the structure of the training data; (ii) a diversity-accuracy tradeoff in model generations as sampling temperature varies; (iii) a simplicity bias in the model's output; and (iv) compositional generalization and a primacy bias with in-context exemplars. Overall, our work introduces a grounded, synthetic framework for studying stepwise inference and offers mechanistic hypotheses that can lay the foundation for a deeper understanding of this phenomenon.
Poly-YOLO: higher speed, more precise detection and instance segmentation for YOLOv3
May 29, 2020
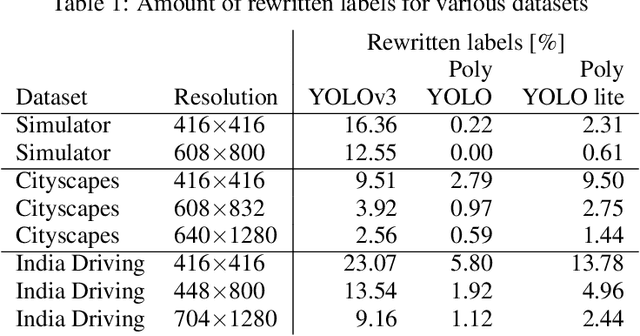

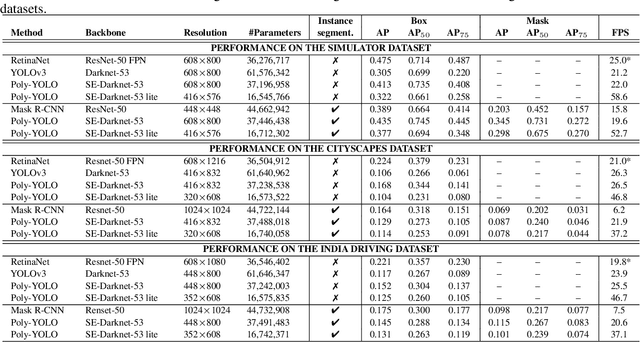
We present a new version of YOLO with better performance and extended with instance segmentation called Poly-YOLO. Poly-YOLO builds on the original ideas of YOLOv3 and removes two of its weaknesses: a large amount of rewritten labels and inefficient distribution of anchors. Poly-YOLO reduces the issues by aggregating features from a light SE-Darknet-53 backbone with a hypercolumn technique, using stairstep upsampling, and produces a single scale output with high resolution. In comparison with YOLOv3, Poly-YOLO has only 60% of its trainable parameters but improves mAP by a relative 40%. We also present Poly-YOLO lite with fewer parameters and a lower output resolution. It has the same precision as YOLOv3, but it is three times smaller and twice as fast, thus suitable for embedded devices. Finally, Poly-YOLO performs instance segmentation using bounding polygons. The network is trained to detect size-independent polygons defined on a polar grid. Vertices of each polygon are being predicted with their confidence, and therefore Poly-YOLO produces polygons with a varying number of vertices.
Identifying collaborators in large codebases
May 07, 2019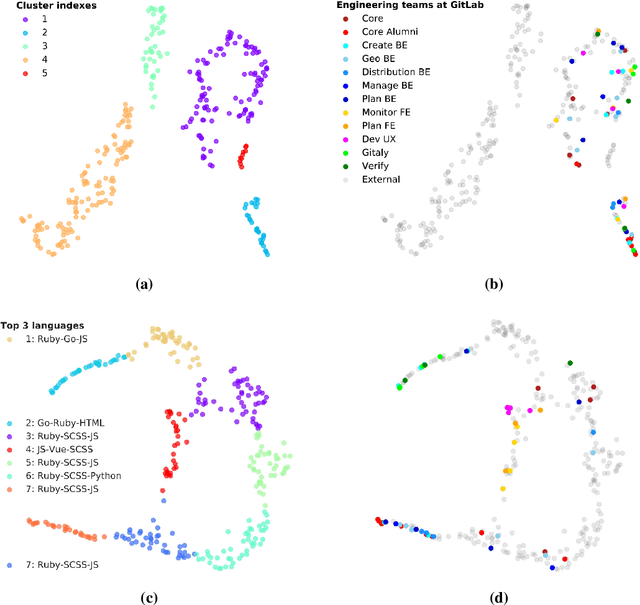
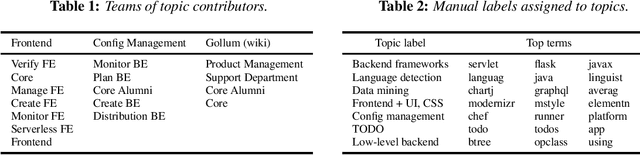
The way developers collaborate inside and particularly across teams often escapes management's attention, despite a formal organization with designated teams being defined. Observability of the actual, organically formed engineering structure provides decision makers invaluable additional tools to manage their talent pool. To identify existing inter and intra-team interactions - and suggest relevant opportunities for suitable collaborations - this paper studies contributors' commit activity, usage of programming languages, and code identifier topics by embedding and clustering them. We evaluate our findings collaborating with the GitLab organization, analyzing 117 of their open source projects. We show that we are able to restore their engineering organization in broad strokes, and also reveal hidden coding collaborations as well as justify in-house technical decisions.
Looking for ELMo's friends: Sentence-Level Pretraining Beyond Language Modeling
Dec 28, 2018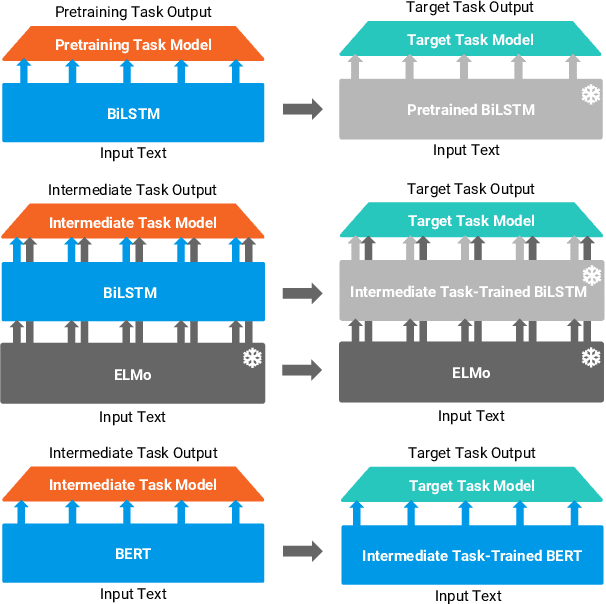
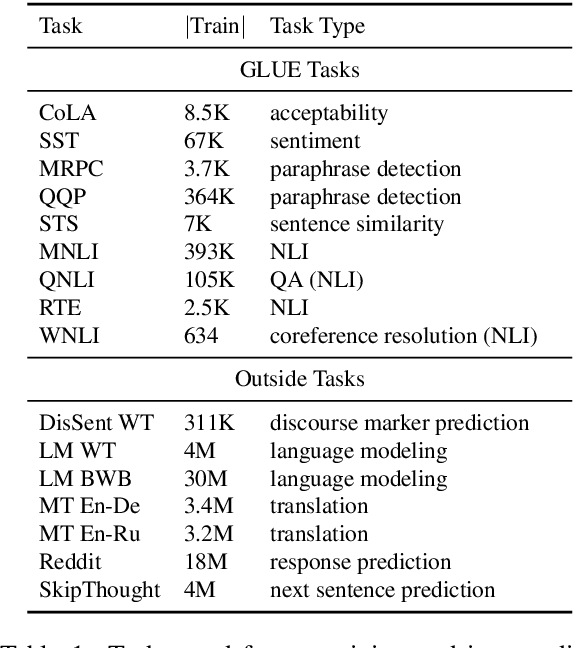
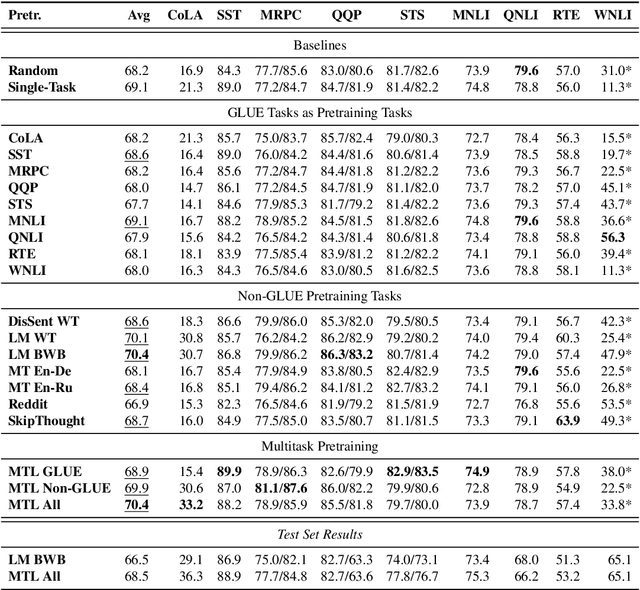
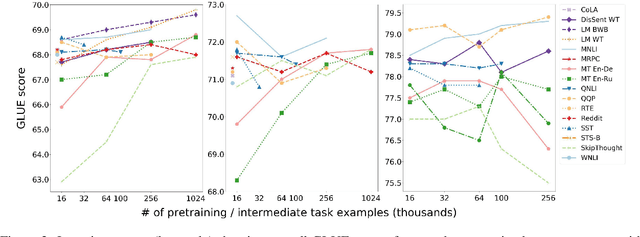
Work on the problem of contextualized word representation -- the development of reusable neural network components for sentence understanding -- has recently seen a surge of progress centered on the unsupervised pretraining task of language modeling with methods like ELMo. This paper contributes the first large-scale systematic study comparing different pretraining tasks in this context, both as complements to language modeling and as potential alternatives. The primary results of the study support the use of language modeling as a pretraining task and set a new state of the art among comparable models using multitask learning with language models. However, a closer look at these results reveals worryingly strong baselines and strikingly varied results across target tasks, suggesting that the widely-used paradigm of pretraining and freezing sentence encoders may not be an ideal platform for further work.