 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCRED: Decoder-Centric Regularization for Encoder-Decoder Based Speech Recognition
Aug 12, 2025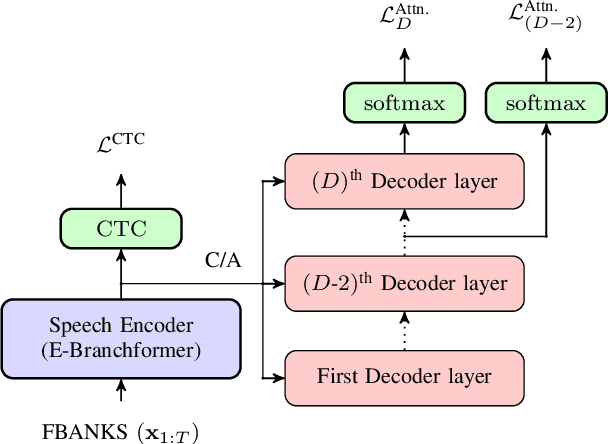
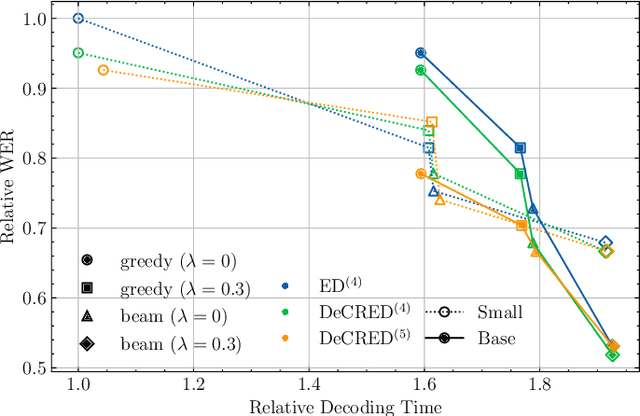


This paper presents a simple yet effective regularization for the internal language model induced by the decoder in encoder-decoder ASR models, thereby improving robustness and generalization in both in- and out-of-domain settings. The proposed method, Decoder-Centric Regularization in Encoder-Decoder (DeCRED), adds auxiliary classifiers to the decoder, enabling next token prediction via intermediate logits. Empirically, DeCRED reduces the mean internal LM BPE perplexity by 36.6% relative to 11 test sets. Furthermore, this translates into actual WER improvements over the baseline in 5 of 7 in-domain and 3 of 4 out-of-domain test sets, reducing macro WER from 6.4% to 6.3% and 18.2% to 16.2%, respectively. On TEDLIUM3, DeCRED achieves 7.0% WER, surpassing the baseline and encoder-centric InterCTC regularization by 0.6% and 0.5%, respectively. Finally, we compare DeCRED with OWSM v3.1 and Whisper-medium, showing competitive WERs despite training on much less data with fewer parameters.
TextBite: A Historical Czech Document Dataset for Logical Page Segmentation
Mar 20, 2025Logical page segmentation is an important step in document analysis, enabling better semantic representations, information retrieval, and text understanding. Previous approaches define logical segmentation either through text or geometric objects, relying on OCR or precise geometry. To avoid the need for OCR, we define the task purely as segmentation in the image domain. Furthermore, to ensure the evaluation remains unaffected by geometrical variations that do not impact text segmentation, we propose to use only foreground text pixels in the evaluation metric and disregard all background pixels. To support research in logical document segmentation, we introduce TextBite, a dataset of historical Czech documents spanning the 18th to 20th centuries, featuring diverse layouts from newspapers, dictionaries, and handwritten records. The dataset comprises 8,449 page images with 78,863 annotated segments of logically and thematically coherent text. We propose a set of baseline methods combining text region detection and relation prediction. The dataset, baselines and evaluation framework can be accessed at https://github.com/DCGM/textbite-dataset.
BenCzechMark : A Czech-centric Multitask and Multimetric Benchmark for Large Language Models with Duel Scoring Mechanism
Dec 23, 2024



We present BenCzechMark (BCM), the first comprehensive Czech language benchmark designed for large language models, offering diverse tasks, multiple task formats, and multiple evaluation metrics. Its scoring system is grounded in statistical significance theory and uses aggregation across tasks inspired by social preference theory. Our benchmark encompasses 50 challenging tasks, with corresponding test datasets, primarily in native Czech, with 11 newly collected ones. These tasks span 8 categories and cover diverse domains, including historical Czech news, essays from pupils or language learners, and spoken word. Furthermore, we collect and clean BUT-Large Czech Collection, the largest publicly available clean Czech language corpus, and use it for (i) contamination analysis, (ii) continuous pretraining of the first Czech-centric 7B language model, with Czech-specific tokenization. We use our model as a baseline for comparison with publicly available multilingual models. Lastly, we release and maintain a leaderboard, with existing 44 model submissions, where new model submissions can be made at https://huggingface.co/spaces/CZLC/BenCzechMark.
Improving Automatic Speech Recognition with Decoder-Centric Regularisation in Encoder-Decoder Models
Oct 22, 2024



This paper proposes a simple yet effective way of regularising the encoder-decoder-based automatic speech recognition (ASR) models that enhance the robustness of the model and improve the generalisation to out-of-domain scenarios. The proposed approach is dubbed as $\textbf{De}$coder-$\textbf{C}$entric $\textbf{R}$egularisation in $\textbf{E}$ncoder-$\textbf{D}$ecoder (DeCRED) architecture for ASR, where auxiliary classifier(s) is introduced in layers of the decoder module. Leveraging these classifiers, we propose two decoding strategies that re-estimate the next token probabilities. Using the recent E-branchformer architecture, we build strong ASR systems that obtained competitive WERs as compared to Whisper-medium and outperformed OWSM v3; while relying only on a fraction of training data and model size. On top of such a strong baseline, we show that DeCRED can further improve the results and, moreover, generalise much better to out-of-domain scenarios, where we show an absolute reduction of 2.7 and 2.9 WERs on AMI and Gigaspeech datasets, respectively. We provide extensive analysis and accompanying experiments that support the benefits of the proposed regularisation scheme.
BUT CHiME-7 system description
Oct 18, 2023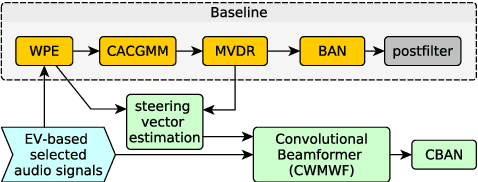
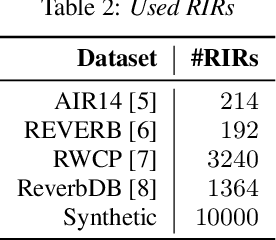
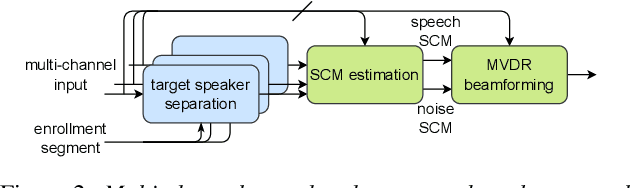
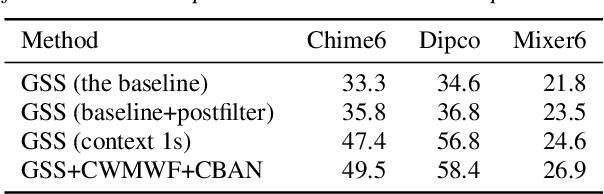
This paper describes the joint effort of Brno University of Technology (BUT), AGH University of Krakow and University of Buenos Aires on the development of Automatic Speech Recognition systems for the CHiME-7 Challenge. We train and evaluate various end-to-end models with several toolkits. We heavily relied on Guided Source Separation (GSS) to convert multi-channel audio to single channel. The ASR is leveraging speech representations from models pre-trained by self-supervised learning, and we do a fusion of several ASR systems. In addition, we modified external data from the LibriSpeech corpus to become a close domain and added it to the training. Our efforts were focused on the far-field acoustic robustness sub-track of Task 1 - Distant Automatic Speech Recognition (DASR), our systems use oracle segmentation.
Hystoc: Obtaining word confidences for fusion of end-to-end ASR systems
May 21, 2023End-to-end (e2e) systems have recently gained wide popularity in automatic speech recognition. However, these systems do generally not provide well-calibrated word-level confidences. In this paper, we propose Hystoc, a simple method for obtaining word-level confidences from hypothesis-level scores. Hystoc is an iterative alignment procedure which turns hypotheses from an n-best output of the ASR system into a confusion network. Eventually, word-level confidences are obtained as posterior probabilities in the individual bins of the confusion network. We show that Hystoc provides confidences that correlate well with the accuracy of the ASR hypothesis. Furthermore, we show that utilizing Hystoc in fusion of multiple e2e ASR systems increases the gains from the fusion by up to 1\,\% WER absolute on Spanish RTVE2020 dataset. Finally, we experiment with using Hystoc for direct fusion of n-best outputs from multiple systems, but we only achieve minor gains when fusing very similar systems.
SoftCTC $\unicode{x2013}$ Semi-Supervised Learning for Text Recognition using Soft Pseudo-Labels
Dec 05, 2022This paper explores semi-supervised training for sequence tasks, such as Optical Character Recognition or Automatic Speech Recognition. We propose a novel loss function $\unicode{x2013}$ SoftCTC $\unicode{x2013}$ which is an extension of CTC allowing to consider multiple transcription variants at the same time. This allows to omit the confidence based filtering step which is otherwise a crucial component of pseudo-labeling approaches to semi-supervised learning. We demonstrate the effectiveness of our method on a challenging handwriting recognition task and conclude that SoftCTC matches the performance of a finely-tuned filtering based pipeline. We also evaluated SoftCTC in terms of computational efficiency, concluding that it is significantly more efficient than a na\"ive CTC-based approach for training on multiple transcription variants, and we make our GPU implementation public.
Importance of Textlines in Historical Document Classification
Jan 24, 2022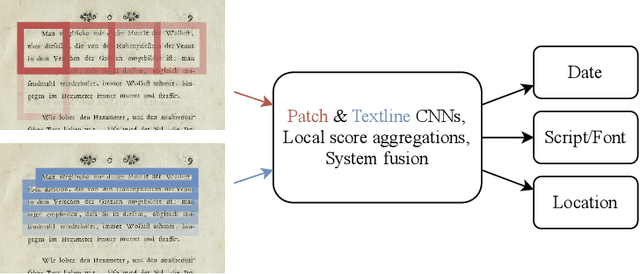
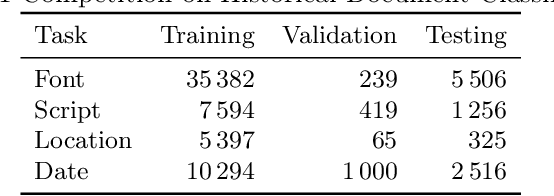


This paper describes a system prepared at Brno University of Technology for ICDAR 2021 Competition on Historical Document Classification, experiments leading to its design, and the main findings. The solved tasks include script and font classification, document origin localization, and dating. We combined patch-level and line-level approaches, where the line-level system utilizes an existing, publicly available page layout analysis engine. In both systems, neural networks provide local predictions which are combined into page-level decisions, and the results of both systems are fused using linear or log-linear interpolation. We propose loss functions suitable for weakly supervised classification problem where multiple possible labels are provided, and we propose loss functions suitable for interval regression in the dating task. The line-level system significantly improves results in script and font classification and in the dating task. The full system achieved 98.48 %, 88.84 %, and 79.69 % accuracy in the font, script, and location classification tasks respectively. In the dating task, our system achieved a mean absolute error of 21.91 years.
AT-ST: Self-Training Adaptation Strategy for OCR in Domains with Limited Transcriptions
Apr 27, 2021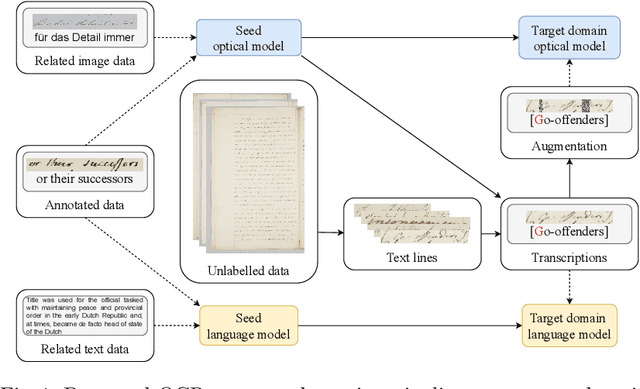

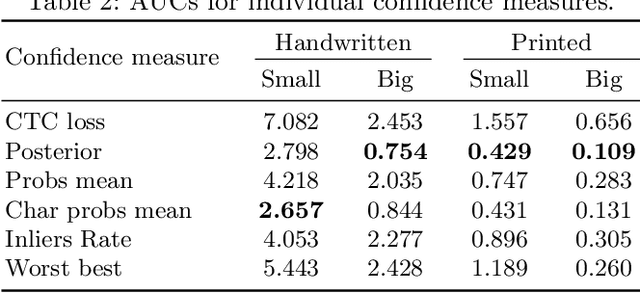
This paper addresses text recognition for domains with limited manual annotations by a simple self-training strategy. Our approach should reduce human annotation effort when target domain data is plentiful, such as when transcribing a collection of single person's correspondence or a large manuscript. We propose to train a seed system on large scale data from related domains mixed with available annotated data from the target domain. The seed system transcribes the unannotated data from the target domain which is then used to train a better system. We study several confidence measures and eventually decide to use the posterior probability of a transcription for data selection. Additionally, we propose to augment the data using an aggressive masking scheme. By self-training, we achieve up to 55 % reduction in character error rate for handwritten data and up to 38 % on printed data. The masking augmentation itself reduces the error rate by about 10 % and its effect is better pronounced in case of difficult handwritten data.
Text Augmentation for Language Models in High Error Recognition Scenario
Nov 11, 2020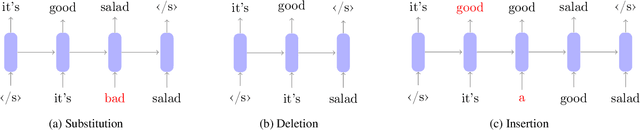
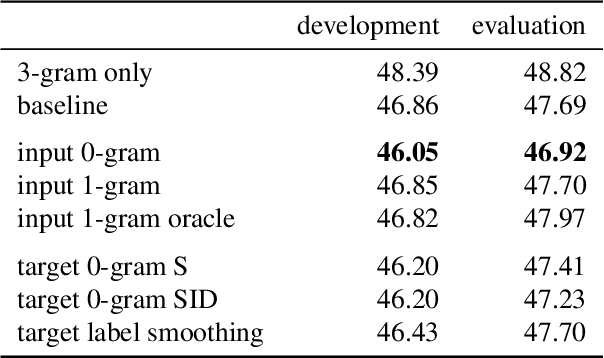
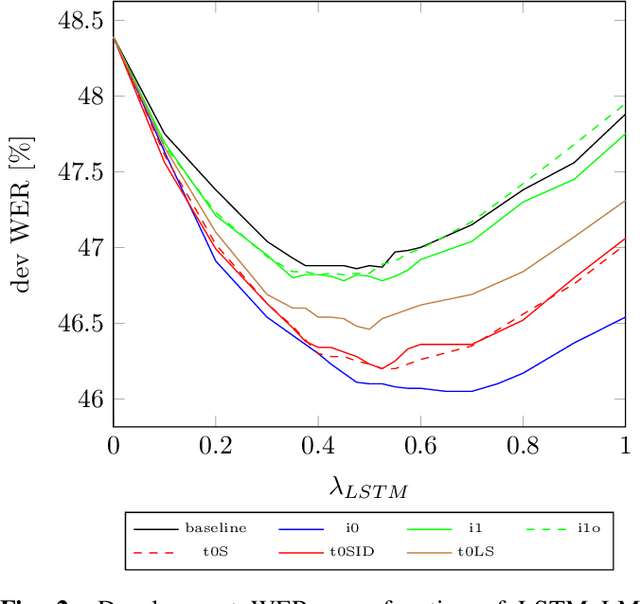
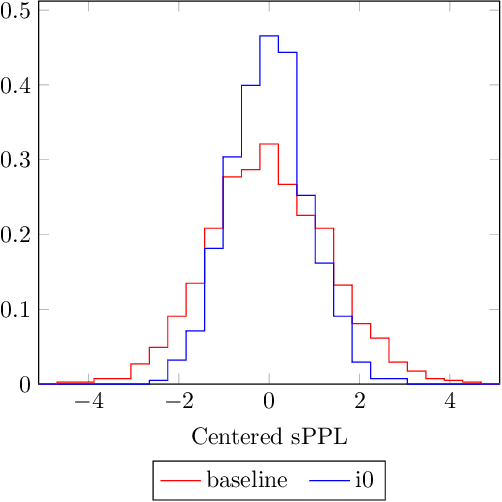
We examine the effect of data augmentation for training of language models for speech recognition. We compare augmentation based on global error statistics with one based on per-word unigram statistics of ASR errors and observe that it is better to only pay attention the global substitution, deletion and insertion rates. This simple scheme also performs consistently better than label smoothing and its sampled variants. Additionally, we investigate into the behavior of perplexity estimated on augmented data, but conclude that it gives no better prediction of the final error rate. Our best augmentation scheme increases the absolute WER improvement from second-pass rescoring from 1.1 % to 1.9 % absolute on the CHiMe-6 challenge.