Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Augmentation for Language Models in High Error Recognition Scenario
Paper and Code
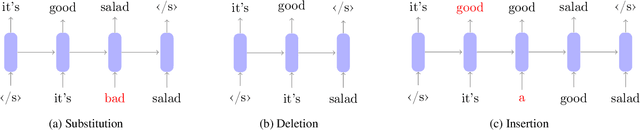
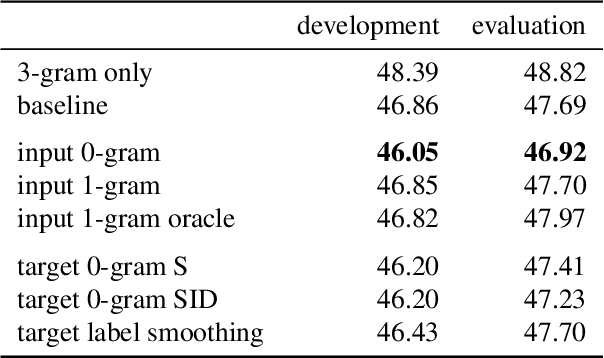
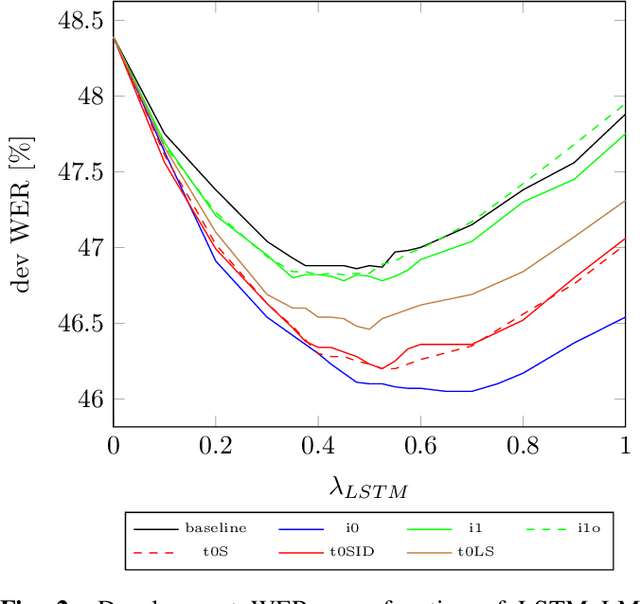
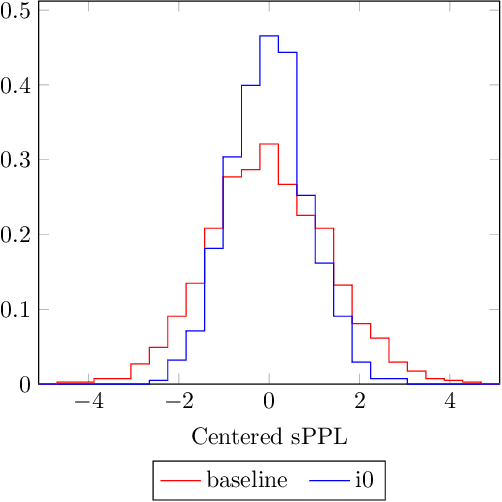
We examine the effect of data augmentation for training of language models for speech recognition. We compare augmentation based on global error statistics with one based on per-word unigram statistics of ASR errors and observe that it is better to only pay attention the global substitution, deletion and insertion rates. This simple scheme also performs consistently better than label smoothing and its sampled variants. Additionally, we investigate into the behavior of perplexity estimated on augmented data, but conclude that it gives no better prediction of the final error rate. Our best augmentation scheme increases the absolute WER improvement from second-pass rescoring from 1.1 % to 1.9 % absolute on the CHiMe-6 challenge.
View paper on