 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenCzechMark : A Czech-centric Multitask and Multimetric Benchmark for Large Language Models with Duel Scoring Mechanism
Dec 23, 2024



We present BenCzechMark (BCM), the first comprehensive Czech language benchmark designed for large language models, offering diverse tasks, multiple task formats, and multiple evaluation metrics. Its scoring system is grounded in statistical significance theory and uses aggregation across tasks inspired by social preference theory. Our benchmark encompasses 50 challenging tasks, with corresponding test datasets, primarily in native Czech, with 11 newly collected ones. These tasks span 8 categories and cover diverse domains, including historical Czech news, essays from pupils or language learners, and spoken word. Furthermore, we collect and clean BUT-Large Czech Collection, the largest publicly available clean Czech language corpus, and use it for (i) contamination analysis, (ii) continuous pretraining of the first Czech-centric 7B language model, with Czech-specific tokenization. We use our model as a baseline for comparison with publicly available multilingual models. Lastly, we release and maintain a leaderboard, with existing 44 model submissions, where new model submissions can be made at https://huggingface.co/spaces/CZLC/BenCzechMark.
R2-D2: A Modular Baseline for Open-Domain Question Answering
Sep 08, 2021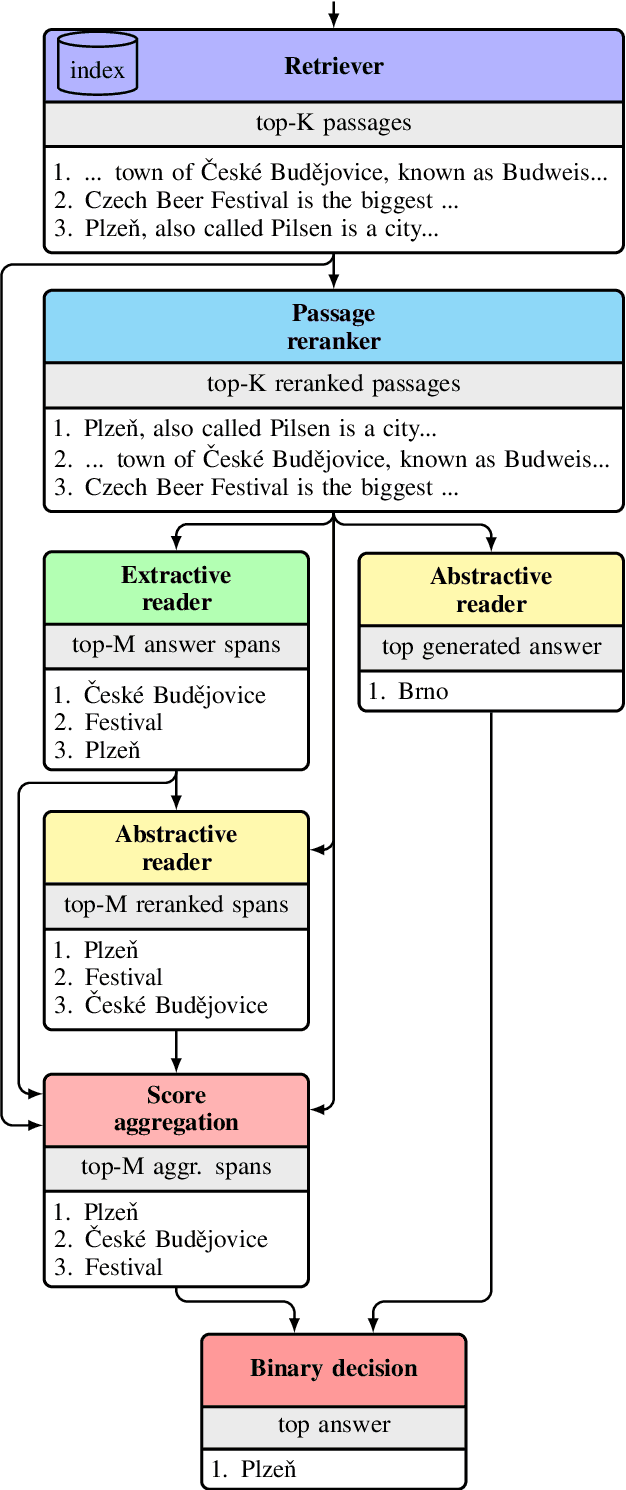
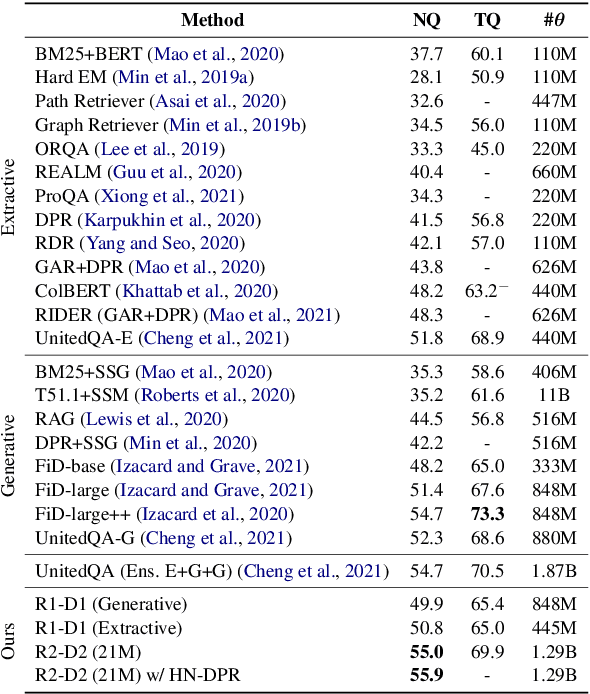
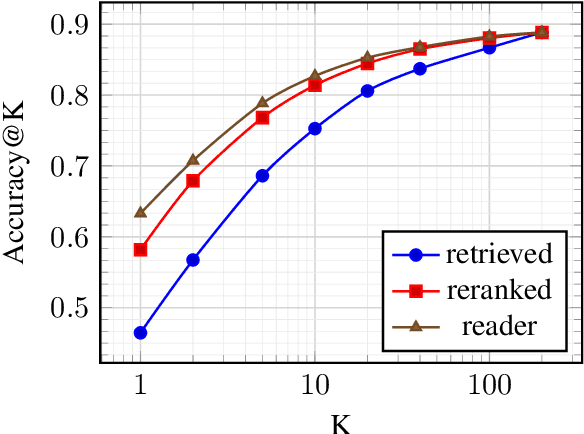
This work presents a novel four-stage open-domain QA pipeline R2-D2 (Rank twice, reaD twice). The pipeline is composed of a retriever, passage reranker, extractive reader, generative reader and a mechanism that aggregates the final prediction from all system's components. We demonstrate its strength across three open-domain QA datasets: NaturalQuestions, TriviaQA and EfficientQA, surpassing state-of-the-art on the first two. Our analysis demonstrates that: (i) combining extractive and generative reader yields absolute improvements up to 5 exact match and it is at least twice as effective as the posterior averaging ensemble of the same models with different parameters, (ii) the extractive reader with fewer parameters can match the performance of the generative reader on extractive QA datasets.
Pruning the Index Contents for Memory Efficient Open-Domain QA
Feb 21, 2021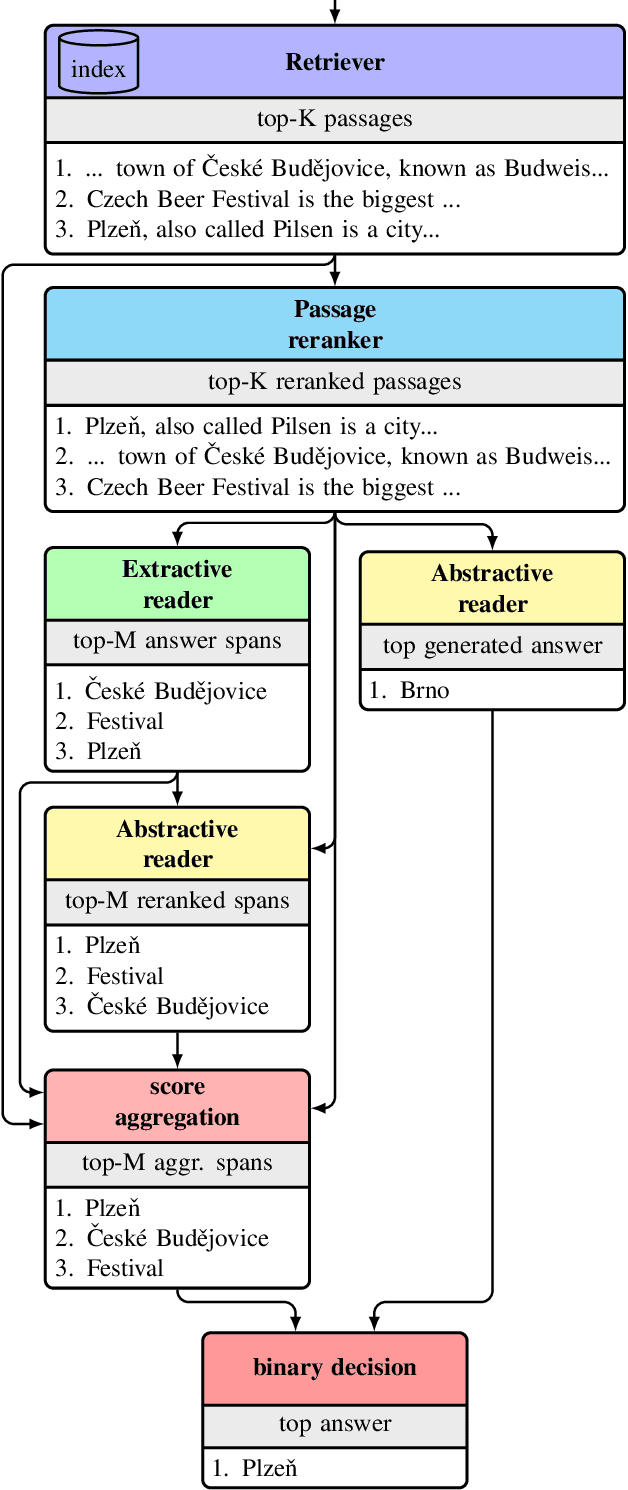
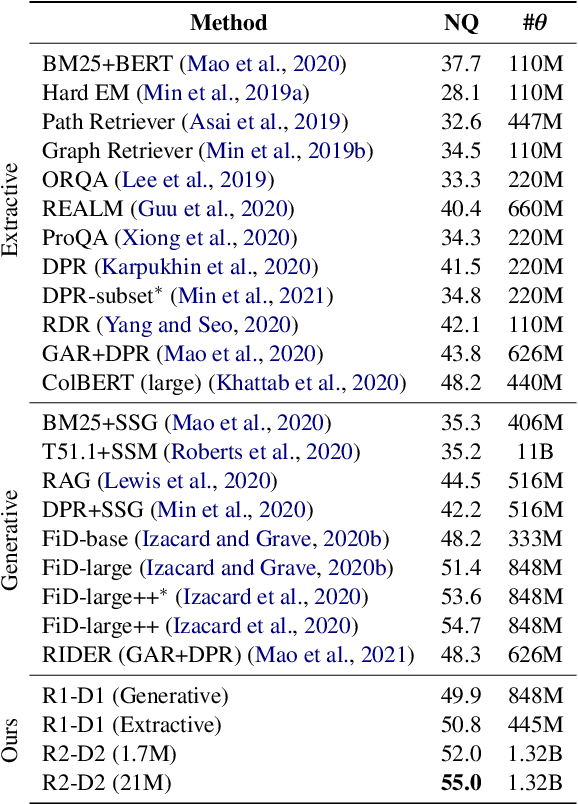
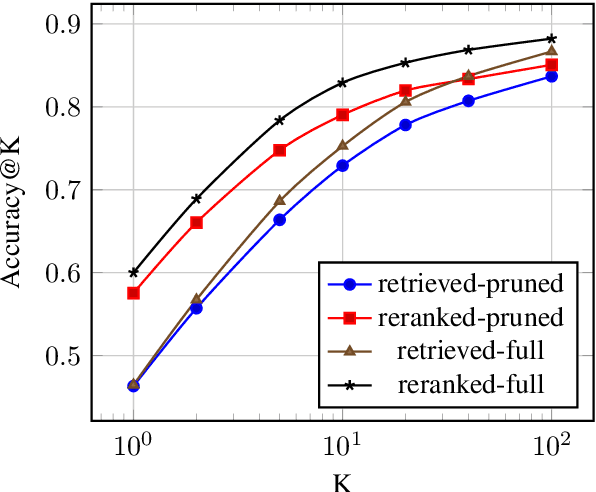
This work presents a novel pipeline that demonstrates what is achievable with a combined effort of state-of-the-art approaches, surpassing the 50% exact match on NaturalQuestions and EfficentQA datasets. Specifically, it proposes the novel R2-D2 (Rank twice, reaD twice) pipeline composed of retriever, reranker, extractive reader, generative reader and a simple way to combine them. Furthermore, previous work often comes with a massive index of external documents that scales in the order of tens of GiB. This work presents a simple approach for pruning the contents of a massive index such that the open-domain QA system altogether with index, OS, and library components fits into 6GiB docker image while retaining only 8% of original index contents and losing only 3% EM accuracy.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021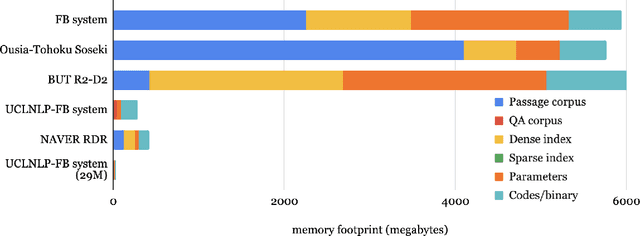
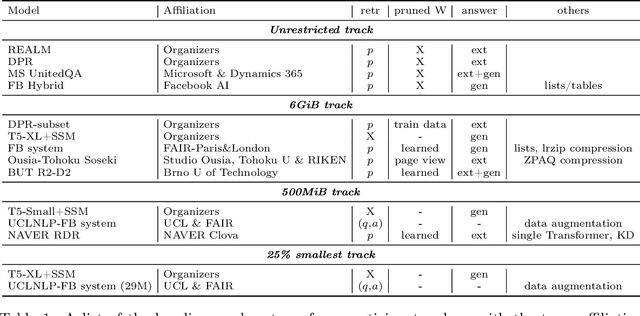
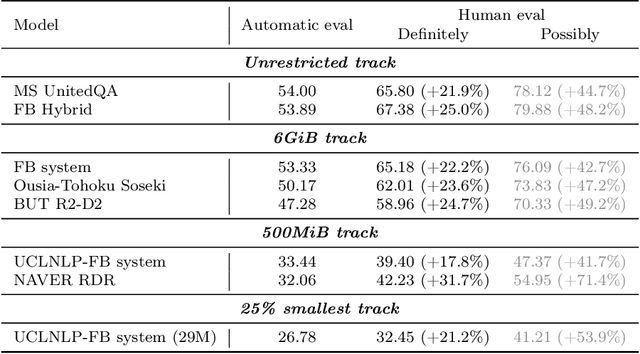
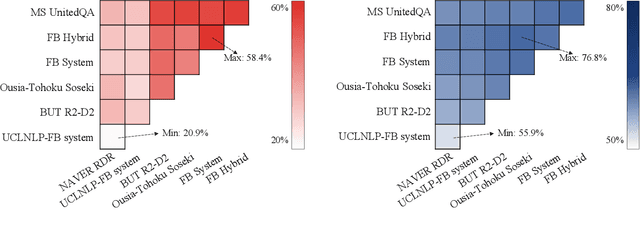
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.