 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning the Index Contents for Memory Efficient Open-Domain QA
Paper and Code
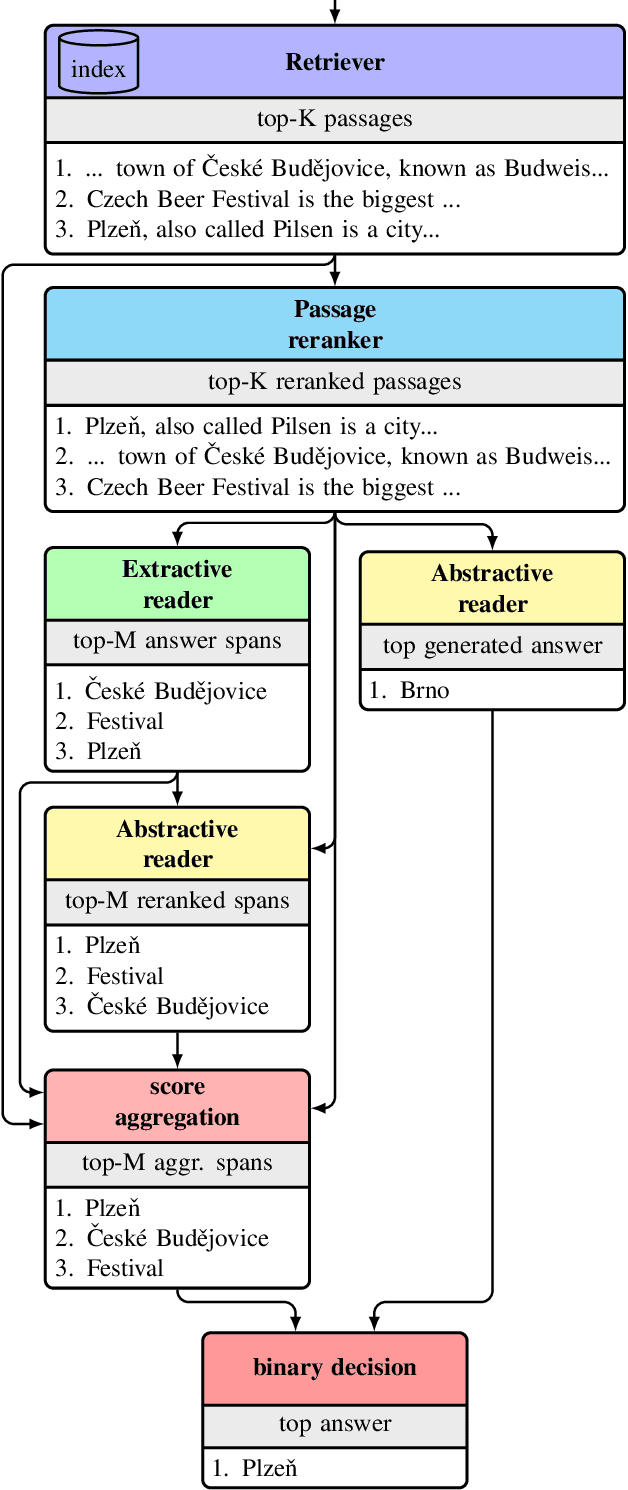
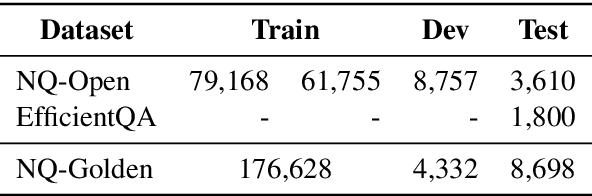
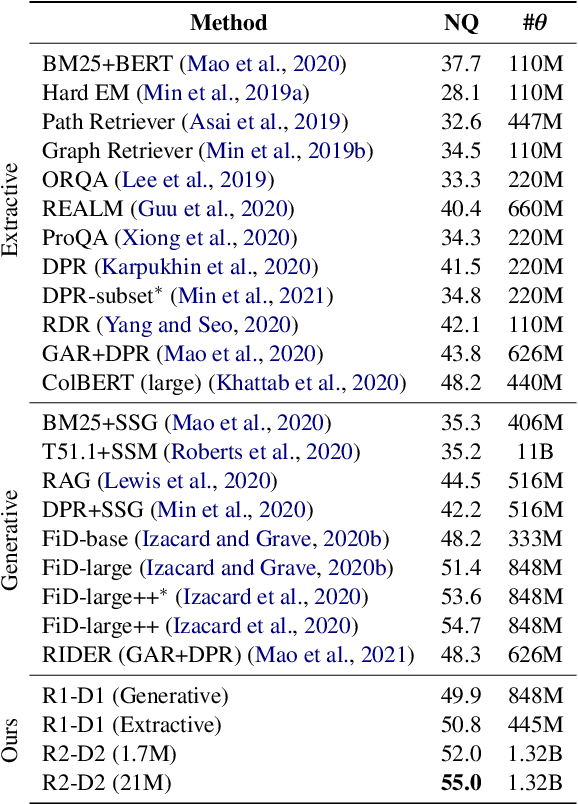
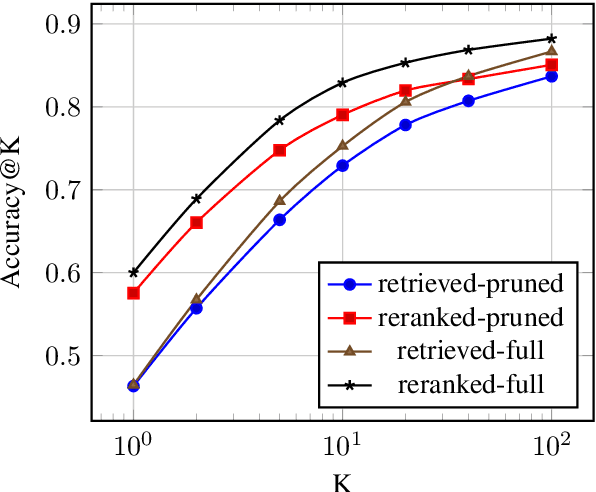
This work presents a novel pipeline that demonstrates what is achievable with a combined effort of state-of-the-art approaches, surpassing the 50% exact match on NaturalQuestions and EfficentQA datasets. Specifically, it proposes the novel R2-D2 (Rank twice, reaD twice) pipeline composed of retriever, reranker, extractive reader, generative reader and a simple way to combine them. Furthermore, previous work often comes with a massive index of external documents that scales in the order of tens of GiB. This work presents a simple approach for pruning the contents of a massive index such that the open-domain QA system altogether with index, OS, and library components fits into 6GiB docker image while retaining only 8% of original index contents and losing only 3% EM accuracy.