 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-DiCoW: Self-Enrolled Diarization-Conditioned Whisper
Jan 27, 2026Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a major challenge. While some approaches achieve strong performance when fine-tuned on specific domains, few systems generalize well across out-of-domain datasets. Our prior work, Diarization-Conditioned Whisper (DiCoW), leverages speaker diarization outputs as conditioning information and, with minimal fine-tuning, demonstrated strong multilingual and multi-domain performance. In this paper, we address a key limitation of DiCoW: ambiguity in Silence-Target-Non-target-Overlap (STNO) masks, where two or more fully overlapping speakers may have nearly identical conditioning despite differing transcriptions. We introduce SE-DiCoW (Self-Enrolled Diarization-Conditioned Whisper), which uses diarization output to locate an enrollment segment anywhere in the conversation where the target speaker is most active. This enrollment segment is used as fixed conditioning via cross-attention at each encoder layer. We further refine DiCoW with improved data segmentation, model initialization, and augmentation. Together, these advances yield substantial gains: SE-DiCoW reduces macro-averaged tcpWER by 52.4% relative to the original DiCoW on the EMMA MT-ASR benchmark.
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
DeCRED: Decoder-Centric Regularization for Encoder-Decoder Based Speech Recognition
Aug 12, 2025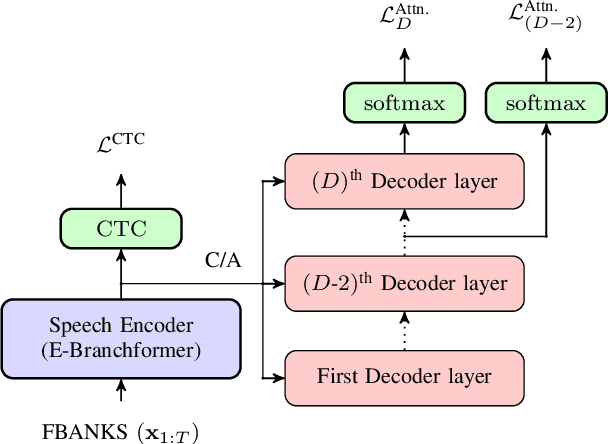
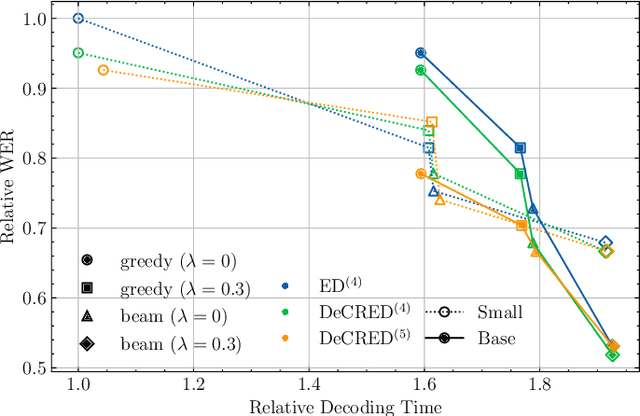


This paper presents a simple yet effective regularization for the internal language model induced by the decoder in encoder-decoder ASR models, thereby improving robustness and generalization in both in- and out-of-domain settings. The proposed method, Decoder-Centric Regularization in Encoder-Decoder (DeCRED), adds auxiliary classifiers to the decoder, enabling next token prediction via intermediate logits. Empirically, DeCRED reduces the mean internal LM BPE perplexity by 36.6% relative to 11 test sets. Furthermore, this translates into actual WER improvements over the baseline in 5 of 7 in-domain and 3 of 4 out-of-domain test sets, reducing macro WER from 6.4% to 6.3% and 18.2% to 16.2%, respectively. On TEDLIUM3, DeCRED achieves 7.0% WER, surpassing the baseline and encoder-centric InterCTC regularization by 0.6% and 0.5%, respectively. Finally, we compare DeCRED with OWSM v3.1 and Whisper-medium, showing competitive WERs despite training on much less data with fewer parameters.
BUT System for the MLC-SLM Challenge
Jun 16, 2025



We present a two-speaker automatic speech recognition (ASR) system that combines DiCoW -- a diarization-conditioned variant of Whisper -- with DiariZen, a diarization pipeline built on top of Pyannote. We first evaluate both systems in out-of-domain (OOD) multilingual scenarios without any fine-tuning. In this scenario, DiariZen consistently outperforms the baseline Pyannote diarization model, demonstrating strong generalization. Despite being fine-tuned on English-only data for target-speaker ASR, DiCoW retains solid multilingual performance, indicating that encoder modifications preserve Whisper's multilingual capabilities. We then fine-tune both DiCoW and DiariZen on the MLC-SLM challenge data. The fine-tuned DiariZen continues to outperform the fine-tuned Pyannote baseline, while DiCoW sees further gains from domain adaptation. Our final system achieves a micro-average tcpWER/CER of 16.75% and ranks second in Task 2 of the MLC-SLM challenge. Lastly, we identify several labeling inconsistencies in the training data -- such as missing speech segments and incorrect silence annotations -- which can hinder diarization fine-tuning. We propose simple mitigation strategies to address these issues and improve system robustness.
DiCoW: Diarization-Conditioned Whisper for Target Speaker Automatic Speech Recognition
Dec 30, 2024Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a significant challenge, particularly when systems conditioned on speaker embeddings fail to generalize to unseen speakers. In this work, we propose Diarization-Conditioned Whisper (DiCoW), a novel approach to target-speaker ASR that leverages speaker diarization outputs as conditioning information. DiCoW extends the pre-trained Whisper model by integrating diarization labels directly, eliminating reliance on speaker embeddings and reducing the need for extensive speaker-specific training data. Our method introduces frame-level diarization-dependent transformations (FDDT) and query-key biasing (QKb) techniques to refine the model's focus on target speakers while effectively handling overlapping speech. By leveraging diarization outputs as conditioning signals, DiCoW simplifies the workflow for multi-speaker ASR, improves generalization to unseen speakers and enables more reliable transcription in real-world multi-speaker recordings. Additionally, we explore the integration of a connectionist temporal classification (CTC) head to Whisper and demonstrate its ability to improve transcription efficiency through hybrid decoding. Notably, we show that our approach is not limited to Whisper; it also provides similar benefits when applied to the Branchformer model. We validate DiCoW on real-world datasets, including AMI and NOTSOFAR-1 from CHiME-8 challenge, as well as synthetic benchmarks such as Libri2Mix and LibriCSS, enabling direct comparisons with previous methods. Results demonstrate that DiCoW enhances the model's target-speaker ASR capabilities while maintaining Whisper's accuracy and robustness on single-speaker data.
BenCzechMark : A Czech-centric Multitask and Multimetric Benchmark for Large Language Models with Duel Scoring Mechanism
Dec 23, 2024



We present BenCzechMark (BCM), the first comprehensive Czech language benchmark designed for large language models, offering diverse tasks, multiple task formats, and multiple evaluation metrics. Its scoring system is grounded in statistical significance theory and uses aggregation across tasks inspired by social preference theory. Our benchmark encompasses 50 challenging tasks, with corresponding test datasets, primarily in native Czech, with 11 newly collected ones. These tasks span 8 categories and cover diverse domains, including historical Czech news, essays from pupils or language learners, and spoken word. Furthermore, we collect and clean BUT-Large Czech Collection, the largest publicly available clean Czech language corpus, and use it for (i) contamination analysis, (ii) continuous pretraining of the first Czech-centric 7B language model, with Czech-specific tokenization. We use our model as a baseline for comparison with publicly available multilingual models. Lastly, we release and maintain a leaderboard, with existing 44 model submissions, where new model submissions can be made at https://huggingface.co/spaces/CZLC/BenCzechMark.
Aligning Pre-trained Models for Spoken Language Translation
Nov 27, 2024This paper investigates a novel approach to end-to-end speech translation (ST) based on aligning frozen pre-trained automatic speech recognition (ASR) and machine translation (MT) models via a small connector module (Q-Former, our Subsampler-Transformer Encoder). This connector bridges the gap between the speech and text modalities, transforming ASR encoder embeddings into the latent representation space of the MT encoder while being the only part of the system optimized during training. Experiments are conducted on the How2 English-Portuguese dataset as we investigate the alignment approach in a small-scale scenario focusing on ST. While keeping the size of the connector module constant and small in comparison ( < 5% of the size of the larger aligned models), increasing the size and capability of the foundation ASR and MT models universally improves translation results. We also find that the connectors can serve as domain adapters for the foundation MT models, significantly improving translation performance in the aligned ST setting. We conclude that this approach represents a viable and scalable approach to training end-to-end ST systems.
Improving Automatic Speech Recognition with Decoder-Centric Regularisation in Encoder-Decoder Models
Oct 22, 2024



This paper proposes a simple yet effective way of regularising the encoder-decoder-based automatic speech recognition (ASR) models that enhance the robustness of the model and improve the generalisation to out-of-domain scenarios. The proposed approach is dubbed as $\textbf{De}$coder-$\textbf{C}$entric $\textbf{R}$egularisation in $\textbf{E}$ncoder-$\textbf{D}$ecoder (DeCRED) architecture for ASR, where auxiliary classifier(s) is introduced in layers of the decoder module. Leveraging these classifiers, we propose two decoding strategies that re-estimate the next token probabilities. Using the recent E-branchformer architecture, we build strong ASR systems that obtained competitive WERs as compared to Whisper-medium and outperformed OWSM v3; while relying only on a fraction of training data and model size. On top of such a strong baseline, we show that DeCRED can further improve the results and, moreover, generalise much better to out-of-domain scenarios, where we show an absolute reduction of 2.7 and 2.9 WERs on AMI and Gigaspeech datasets, respectively. We provide extensive analysis and accompanying experiments that support the benefits of the proposed regularisation scheme.
Target Speaker ASR with Whisper
Sep 14, 2024We propose a novel approach to enable the use of large, single speaker ASR models, such as Whisper, for target speaker ASR. The key insight of this method is that it is much easier to model relative differences among speakers by learning to condition on frame-level diarization outputs, than to learn the space of all speaker embeddings. We find that adding even a single bias term per diarization output type before the first transformer block can transform single speaker ASR models, into target speaker ASR models. Our target-speaker ASR model can be used for speaker attributed ASR by producing, in sequence, a transcript for each hypothesized speaker in a diarization output. This simplified model for speaker attributed ASR using only a single microphone outperforms cascades of speech separation and diarization by 11% absolute ORC-WER on the NOTSOFAR-1 dataset.