 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaching Dialogue State Tracking via Aligning Speech Encoders and LLMs
Jun 10, 2025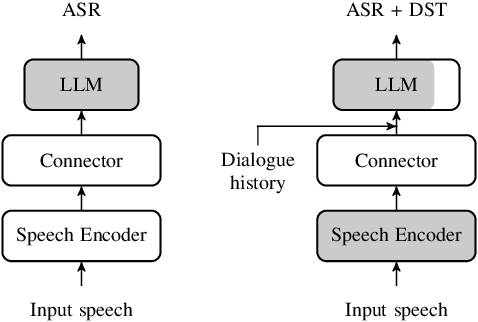
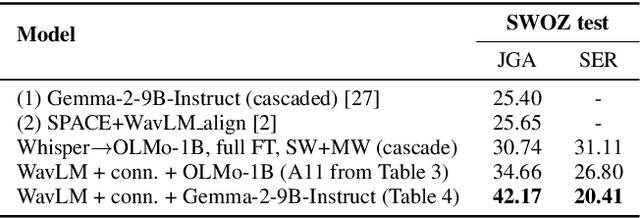
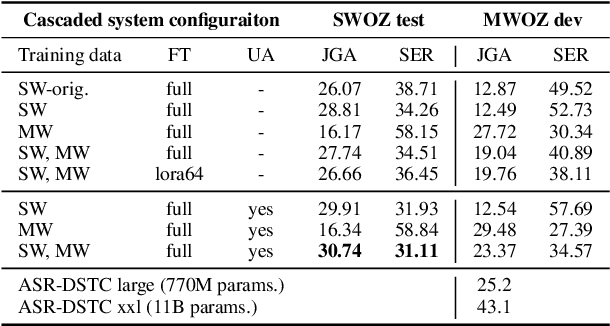
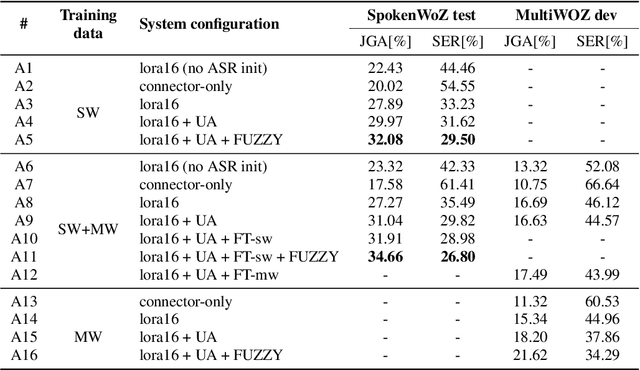
In this work, we approach spoken Dialogue State Tracking (DST) by bridging the representation spaces of speech encoders and LLMs via a small connector module, with a focus on fully open-sourced and open-data components (WavLM-large, OLMo). We focus on ablating different aspects of such systems including full/LoRA adapter fine-tuning, the effect of agent turns in the dialogue history, as well as fuzzy matching-based output post-processing, which greatly improves performance of our systems on named entities in the dialogue slot values. We conduct our experiments on the SpokenWOZ dataset, and additionally utilize the Speech-Aware MultiWOZ dataset to augment our training data. Ultimately, our best-performing WavLM + connector + OLMo-1B aligned models achieve state of the art on the SpokenWOZ test set (34.66% JGA), and our system with Gemma-2-9B-instruct further surpasses this result, reaching 42.17% JGA on SpokenWOZ test.
Factors affecting the in-context learning abilities of LLMs for dialogue state tracking
Jun 10, 2025This study explores the application of in-context learning (ICL) to the dialogue state tracking (DST) problem and investigates the factors that influence its effectiveness. We use a sentence embedding based k-nearest neighbour method to retrieve the suitable demonstrations for ICL. The selected demonstrations, along with the test samples, are structured within a template as input to the LLM. We then conduct a systematic study to analyse the impact of factors related to demonstration selection and prompt context on DST performance. This work is conducted using the MultiWoZ2.4 dataset and focuses primarily on the OLMo-7B-instruct, Mistral-7B-Instruct-v0.3, and Llama3.2-3B-Instruct models. Our findings provide several useful insights on in-context learning abilities of LLMs for dialogue state tracking.
Aligning Pre-trained Models for Spoken Language Translation
Nov 27, 2024This paper investigates a novel approach to end-to-end speech translation (ST) based on aligning frozen pre-trained automatic speech recognition (ASR) and machine translation (MT) models via a small connector module (Q-Former, our Subsampler-Transformer Encoder). This connector bridges the gap between the speech and text modalities, transforming ASR encoder embeddings into the latent representation space of the MT encoder while being the only part of the system optimized during training. Experiments are conducted on the How2 English-Portuguese dataset as we investigate the alignment approach in a small-scale scenario focusing on ST. While keeping the size of the connector module constant and small in comparison ( < 5% of the size of the larger aligned models), increasing the size and capability of the foundation ASR and MT models universally improves translation results. We also find that the connectors can serve as domain adapters for the foundation MT models, significantly improving translation performance in the aligned ST setting. We conclude that this approach represents a viable and scalable approach to training end-to-end ST systems.