 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance of Textlines in Historical Document Classification
Paper and Code
Jan 24, 2022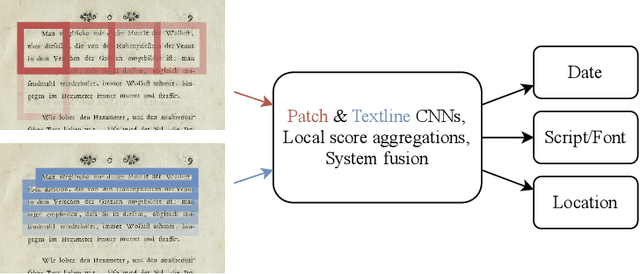


This paper describes a system prepared at Brno University of Technology for ICDAR 2021 Competition on Historical Document Classification, experiments leading to its design, and the main findings. The solved tasks include script and font classification, document origin localization, and dating. We combined patch-level and line-level approaches, where the line-level system utilizes an existing, publicly available page layout analysis engine. In both systems, neural networks provide local predictions which are combined into page-level decisions, and the results of both systems are fused using linear or log-linear interpolation. We propose loss functions suitable for weakly supervised classification problem where multiple possible labels are provided, and we propose loss functions suitable for interval regression in the dating task. The line-level system significantly improves results in script and font classification and in the dating task. The full system achieved 98.48 %, 88.84 %, and 79.69 % accuracy in the font, script, and location classification tasks respectively. In the dating task, our system achieved a mean absolute error of 21.91 years.