 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Fine-Tuning of Autoregressive Models on Limited Handwritten Texts
Mar 25, 2025



A common use case for OCR applications involves users uploading documents and progressively correcting automatic recognition to obtain the final transcript. This correction phase presents an opportunity for progressive adaptation of the OCR model, making it crucial to adapt early, while ensuring stability and reliability. We demonstrate that state-of-the-art transformer-based models can effectively support this adaptation, gradually reducing the annotator's workload. Our results show that fine-tuning can reliably start with just 16 lines, yielding a 10% relative improvement in CER, and scale up to 40% with 256 lines. We further investigate the impact of model components, clarifying the roles of the encoder and decoder in the fine-tuning process. To guide adaptation, we propose reliable stopping criteria, considering both direct approaches and global trend analysis. Additionally, we show that OCR models can be leveraged to cut annotation costs by half through confidence-based selection of informative lines, achieving the same performance with fewer annotations.
BiblioPage: A Dataset of Scanned Title Pages for Bibliographic Metadata Extraction
Mar 25, 2025Manual digitization of bibliographic metadata is time consuming and labor intensive, especially for historical and real-world archives with highly variable formatting across documents. Despite advances in machine learning, the absence of dedicated datasets for metadata extraction hinders automation. To address this gap, we introduce BiblioPage, a dataset of scanned title pages annotated with structured bibliographic metadata. The dataset consists of approximately 2,000 monograph title pages collected from 14 Czech libraries, spanning a wide range of publication periods, typographic styles, and layout structures. Each title page is annotated with 16 bibliographic attributes, including title, contributors, and publication metadata, along with precise positional information in the form of bounding boxes. To extract structured information from this dataset, we valuated object detection models such as YOLO and DETR combined with transformer-based OCR, achieving a maximum mAP of 52 and an F1 score of 59. Additionally, we assess the performance of various visual large language models, including LlamA 3.2-Vision and GPT-4o, with the best model reaching an F1 score of 67. BiblioPage serves as a real-world benchmark for bibliographic metadata extraction, contributing to document understanding, document question answering, and document information extraction. Dataset and evaluation scripts are availible at: https://github.com/DCGM/biblio-dataset
Finetuning Is a Surprisingly Effective Domain Adaptation Baseline in Handwriting Recognition
Feb 13, 2023



In many machine learning tasks, a large general dataset and a small specialized dataset are available. In such situations, various domain adaptation methods can be used to adapt a general model to the target dataset. We show that in the case of neural networks trained for handwriting recognition using CTC, simple finetuning with data augmentation works surprisingly well in such scenarios and that it is resistant to overfitting even for very small target domain datasets. We evaluated the behavior of finetuning with respect to augmentation, training data size, and quality of the pre-trained network, both in writer-dependent and writer-independent settings. On a large real-world dataset, finetuning provided an average relative CER improvement of 25 % with 16 text lines for new writers and 50 % for 256 text lines.
Towards Writing Style Adaptation in Handwriting Recognition
Feb 13, 2023



One of the challenges of handwriting recognition is to transcribe a large number of vastly different writing styles. State-of-the-art approaches do not explicitly use information about the writer's style, which may be limiting overall accuracy due to various ambiguities. We explore models with writer-dependent parameters which take the writer's identity as an additional input. The proposed models can be trained on datasets with partitions likely written by a single author (e.g. single letter, diary, or chronicle). We propose a Writer Style Block (WSB), an adaptive instance normalization layer conditioned on learned embeddings of the partitions. We experimented with various placements and settings of WSB and contrastively pre-trained embeddings. We show that our approach outperforms a baseline with no WSB in a writer-dependent scenario and that it is possible to estimate embeddings for new writers. However, domain adaptation using simple finetuning in a writer-independent setting provides superior accuracy at a similar computational cost. The proposed approach should be further investigated in terms of training stability and embedding regularization to overcome such a baseline.
Importance of Textlines in Historical Document Classification
Jan 24, 2022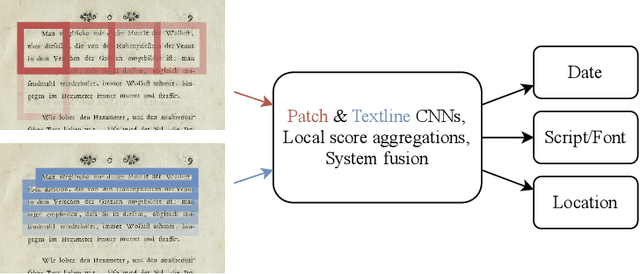


This paper describes a system prepared at Brno University of Technology for ICDAR 2021 Competition on Historical Document Classification, experiments leading to its design, and the main findings. The solved tasks include script and font classification, document origin localization, and dating. We combined patch-level and line-level approaches, where the line-level system utilizes an existing, publicly available page layout analysis engine. In both systems, neural networks provide local predictions which are combined into page-level decisions, and the results of both systems are fused using linear or log-linear interpolation. We propose loss functions suitable for weakly supervised classification problem where multiple possible labels are provided, and we propose loss functions suitable for interval regression in the dating task. The line-level system significantly improves results in script and font classification and in the dating task. The full system achieved 98.48 %, 88.84 %, and 79.69 % accuracy in the font, script, and location classification tasks respectively. In the dating task, our system achieved a mean absolute error of 21.91 years.
TS-Net: OCR Trained to Switch Between Text Transcription Styles
Mar 09, 2021



Users of OCR systems, from different institutions and scientific disciplines, prefer and produce different transcription styles. This presents a problem for training of consistent text recognition neural networks on real-world data. We propose to extend existing text recognition networks with a Transcription Style Block (TSB) which can learn from data to switch between multiple transcription styles without any explicit knowledge of transcription rules. TSB is an adaptive instance normalization conditioned by identifiers representing consistently transcribed documents (e.g. single document, documents by a single transcriber, or an institution). We show that TSB is able to learn completely different transcription styles in controlled experiments on artificial data, it improves text recognition accuracy on large-scale real-world data, and it learns semantically meaningful transcription style embedding. We also show how TSB can efficiently adapt to transcription styles of new documents from transcriptions of only a few text lines.