 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiblioPage: A Dataset of Scanned Title Pages for Bibliographic Metadata Extraction
Mar 25, 2025Manual digitization of bibliographic metadata is time consuming and labor intensive, especially for historical and real-world archives with highly variable formatting across documents. Despite advances in machine learning, the absence of dedicated datasets for metadata extraction hinders automation. To address this gap, we introduce BiblioPage, a dataset of scanned title pages annotated with structured bibliographic metadata. The dataset consists of approximately 2,000 monograph title pages collected from 14 Czech libraries, spanning a wide range of publication periods, typographic styles, and layout structures. Each title page is annotated with 16 bibliographic attributes, including title, contributors, and publication metadata, along with precise positional information in the form of bounding boxes. To extract structured information from this dataset, we valuated object detection models such as YOLO and DETR combined with transformer-based OCR, achieving a maximum mAP of 52 and an F1 score of 59. Additionally, we assess the performance of various visual large language models, including LlamA 3.2-Vision and GPT-4o, with the best model reaching an F1 score of 67. BiblioPage serves as a real-world benchmark for bibliographic metadata extraction, contributing to document understanding, document question answering, and document information extraction. Dataset and evaluation scripts are availible at: https://github.com/DCGM/biblio-dataset
BUT-FIT at SemEval-2020 Task 4: Multilingual commonsense
Aug 21, 2020

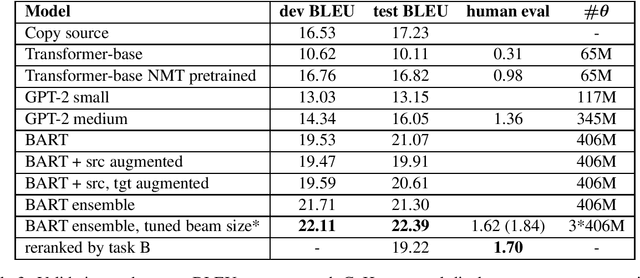
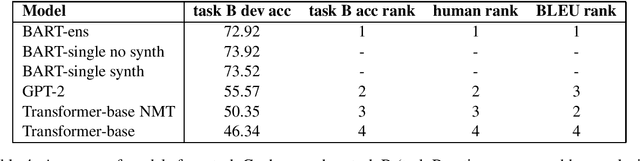
This paper describes work of the BUT-FIT's team at SemEval 2020 Task 4 - Commonsense Validation and Explanation. We participated in all three subtasks. In subtasks A and B, our submissions are based on pretrained language representation models (namely ALBERT) and data augmentation. We experimented with solving the task for another language, Czech, by means of multilingual models and machine translated dataset, or translated model inputs. We show that with a strong machine translation system, our system can be used in another language with a small accuracy loss. In subtask C, our submission, which is based on pretrained sequence-to-sequence model (BART), ranked 1st in BLEU score ranking, however, we show that the correlation between BLEU and human evaluation, in which our submission ended up 4th, is low. We analyse the metrics used in the evaluation and we propose an additional score based on model from subtask B, which correlates well with our manual ranking, as well as reranking method based on the same principle. We performed an error and dataset analysis for all subtasks and we present our findings.