 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARCOR2: Framework for Collaborative End-User Management of Industrial Robotic Workplaces using Augmented Reality
Jun 14, 2023This paper presents a novel framework enabling end-users to perform the management of complex robotic workplaces using a tablet and augmented reality. The framework allows users to commission the workplace comprising different types of robots, machines, or services irrespective of the vendor, set task-important points in space, specify program steps, generate a code, and control its execution. More users can collaborate simultaneously, for instance, within a large-scale workplace. Spatially registered visualization and programming enable a fast and easy understanding of workplace processes, while high precision is achieved by combining kinesthetic teaching with specific graphical tools for relative manipulation of poses. A visually defined program is for execution translated into Python representation, allowing efficient involvement of experts. The system was designed and developed in cooperation with a system integrator based on an offline printed circuit board testing use case, and its user interface was evaluated multiple times during the development. The latest evaluation was performed by three experts and indicates the high potential of the solution.
BUT-FIT at SemEval-2020 Task 4: Multilingual commonsense
Aug 21, 2020

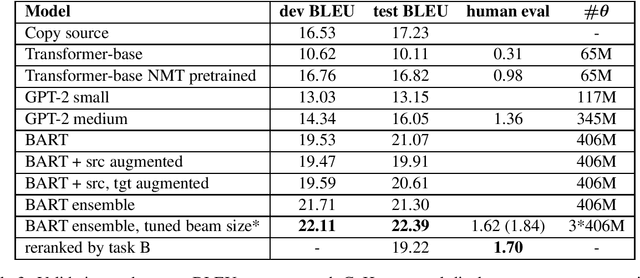
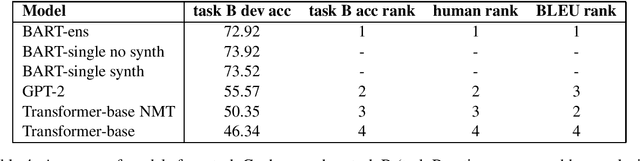
This paper describes work of the BUT-FIT's team at SemEval 2020 Task 4 - Commonsense Validation and Explanation. We participated in all three subtasks. In subtasks A and B, our submissions are based on pretrained language representation models (namely ALBERT) and data augmentation. We experimented with solving the task for another language, Czech, by means of multilingual models and machine translated dataset, or translated model inputs. We show that with a strong machine translation system, our system can be used in another language with a small accuracy loss. In subtask C, our submission, which is based on pretrained sequence-to-sequence model (BART), ranked 1st in BLEU score ranking, however, we show that the correlation between BLEU and human evaluation, in which our submission ended up 4th, is low. We analyse the metrics used in the evaluation and we propose an additional score based on model from subtask B, which correlates well with our manual ranking, as well as reranking method based on the same principle. We performed an error and dataset analysis for all subtasks and we present our findings.