 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Self-Supervised Pre-Training for Text Recognition Transformers on Large-Scale Datasets
Mar 28, 2025



Self-supervised learning has emerged as a powerful approach for leveraging large-scale unlabeled data to improve model performance in various domains. In this paper, we explore masked self-supervised pre-training for text recognition transformers. Specifically, we propose two modifications to the pre-training phase: progressively increasing the masking probability, and modifying the loss function to incorporate both masked and non-masked patches. We conduct extensive experiments using a dataset of 50M unlabeled text lines for pre-training and four differently sized annotated datasets for fine-tuning. Furthermore, we compare our pre-trained models against those trained with transfer learning, demonstrating the effectiveness of the self-supervised pre-training. In particular, pre-training consistently improves the character error rate of models, in some cases up to 30 % relatively. It is also on par with transfer learning but without relying on extra annotated text lines.
AnnoPage Dataset: Dataset of Non-Textual Elements in Documents with Fine-Grained Categorization
Mar 28, 2025We introduce the AnnoPage Dataset, a novel collection of 7550 pages from historical documents, primarily in Czech and German, spanning from 1485 to the present, focusing on the late 19th and early 20th centuries. The dataset is designed to support research in document layout analysis and object detection. Each page is annotated with axis-aligned bounding boxes (AABB) representing elements of 25 categories of non-textual elements, such as images, maps, decorative elements, or charts, following the Czech Methodology of image document processing. The annotations were created by expert librarians to ensure accuracy and consistency. The dataset also incorporates pages from multiple, mainly historical, document datasets to enhance variability and maintain continuity. The dataset is divided into development and test subsets, with the test set carefully selected to maintain the category distribution. We provide baseline results using YOLO and DETR object detectors, offering a reference point for future research. The AnnoPage Dataset is publicly available on Zenodo (https://doi.org/10.5281/zenodo.12788419), along with ground-truth annotations in YOLO format.
Self-supervised Pre-training of Text Recognizers
May 01, 2024



In this paper, we investigate self-supervised pre-training methods for document text recognition. Nowadays, large unlabeled datasets can be collected for many research tasks, including text recognition, but it is costly to annotate them. Therefore, methods utilizing unlabeled data are researched. We study self-supervised pre-training methods based on masked label prediction using three different approaches -- Feature Quantization, VQ-VAE, and Post-Quantized AE. We also investigate joint-embedding approaches with VICReg and NT-Xent objectives, for which we propose an image shifting technique to prevent model collapse where it relies solely on positional encoding while completely ignoring the input image. We perform our experiments on historical handwritten (Bentham) and historical printed datasets mainly to investigate the benefits of the self-supervised pre-training techniques with different amounts of annotated target domain data. We use transfer learning as strong baselines. The evaluation shows that the self-supervised pre-training on data from the target domain is very effective, but it struggles to outperform transfer learning from closely related domains. This paper is one of the first researches exploring self-supervised pre-training in document text recognition, and we believe that it will become a cornerstone for future research in this area. We made our implementation of the investigated methods publicly available at https://github.com/DCGM/pero-pretraining.
Towards Writing Style Adaptation in Handwriting Recognition
Feb 13, 2023



One of the challenges of handwriting recognition is to transcribe a large number of vastly different writing styles. State-of-the-art approaches do not explicitly use information about the writer's style, which may be limiting overall accuracy due to various ambiguities. We explore models with writer-dependent parameters which take the writer's identity as an additional input. The proposed models can be trained on datasets with partitions likely written by a single author (e.g. single letter, diary, or chronicle). We propose a Writer Style Block (WSB), an adaptive instance normalization layer conditioned on learned embeddings of the partitions. We experimented with various placements and settings of WSB and contrastively pre-trained embeddings. We show that our approach outperforms a baseline with no WSB in a writer-dependent scenario and that it is possible to estimate embeddings for new writers. However, domain adaptation using simple finetuning in a writer-independent setting provides superior accuracy at a similar computational cost. The proposed approach should be further investigated in terms of training stability and embedding regularization to overcome such a baseline.
SoftCTC $\unicode{x2013}$ Semi-Supervised Learning for Text Recognition using Soft Pseudo-Labels
Dec 05, 2022This paper explores semi-supervised training for sequence tasks, such as Optical Character Recognition or Automatic Speech Recognition. We propose a novel loss function $\unicode{x2013}$ SoftCTC $\unicode{x2013}$ which is an extension of CTC allowing to consider multiple transcription variants at the same time. This allows to omit the confidence based filtering step which is otherwise a crucial component of pseudo-labeling approaches to semi-supervised learning. We demonstrate the effectiveness of our method on a challenging handwriting recognition task and conclude that SoftCTC matches the performance of a finely-tuned filtering based pipeline. We also evaluated SoftCTC in terms of computational efficiency, concluding that it is significantly more efficient than a na\"ive CTC-based approach for training on multiple transcription variants, and we make our GPU implementation public.
Importance of Textlines in Historical Document Classification
Jan 24, 2022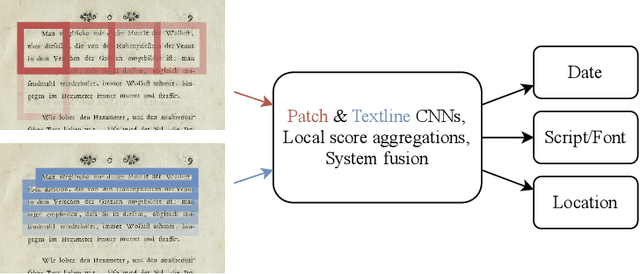
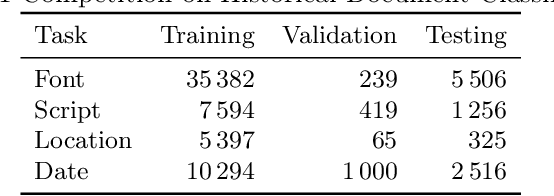


This paper describes a system prepared at Brno University of Technology for ICDAR 2021 Competition on Historical Document Classification, experiments leading to its design, and the main findings. The solved tasks include script and font classification, document origin localization, and dating. We combined patch-level and line-level approaches, where the line-level system utilizes an existing, publicly available page layout analysis engine. In both systems, neural networks provide local predictions which are combined into page-level decisions, and the results of both systems are fused using linear or log-linear interpolation. We propose loss functions suitable for weakly supervised classification problem where multiple possible labels are provided, and we propose loss functions suitable for interval regression in the dating task. The line-level system significantly improves results in script and font classification and in the dating task. The full system achieved 98.48 %, 88.84 %, and 79.69 % accuracy in the font, script, and location classification tasks respectively. In the dating task, our system achieved a mean absolute error of 21.91 years.
AT-ST: Self-Training Adaptation Strategy for OCR in Domains with Limited Transcriptions
Apr 27, 2021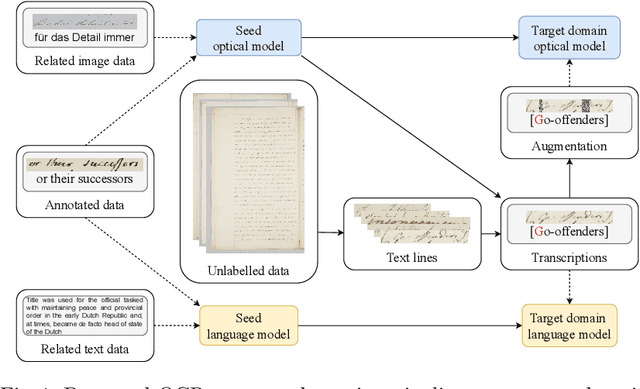
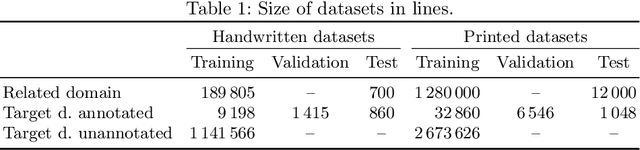

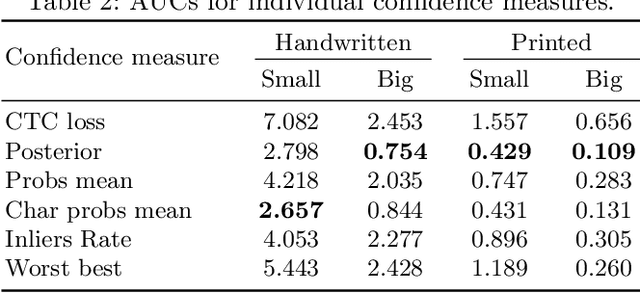
This paper addresses text recognition for domains with limited manual annotations by a simple self-training strategy. Our approach should reduce human annotation effort when target domain data is plentiful, such as when transcribing a collection of single person's correspondence or a large manuscript. We propose to train a seed system on large scale data from related domains mixed with available annotated data from the target domain. The seed system transcribes the unannotated data from the target domain which is then used to train a better system. We study several confidence measures and eventually decide to use the posterior probability of a transcription for data selection. Additionally, we propose to augment the data using an aggressive masking scheme. By self-training, we achieve up to 55 % reduction in character error rate for handwritten data and up to 38 % on printed data. The masking augmentation itself reduces the error rate by about 10 % and its effect is better pronounced in case of difficult handwritten data.
Brno Mobile OCR Dataset
Jul 02, 2019
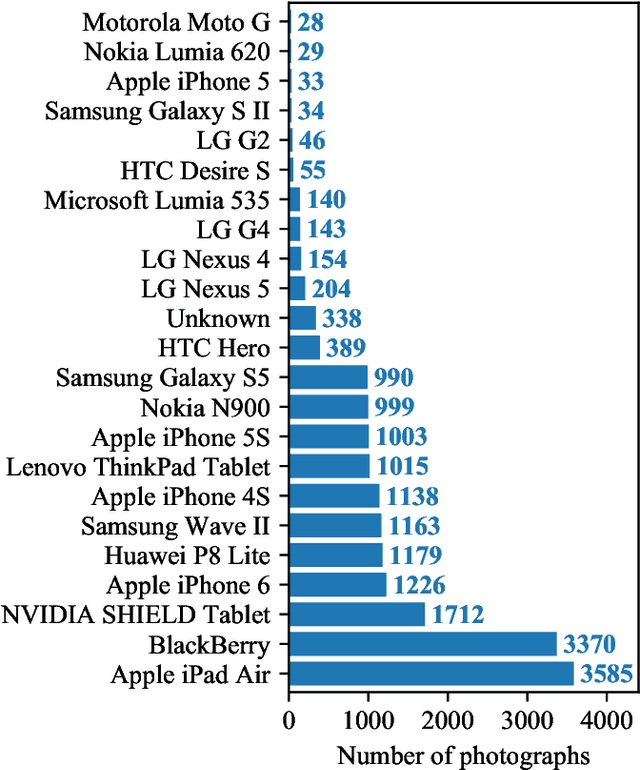

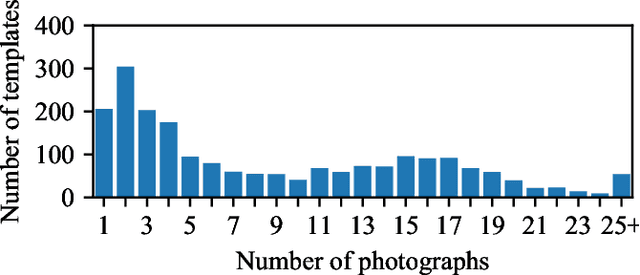
We introduce the Brno Mobile OCR Dataset (B-MOD) for document Optical Character Recognition from low-quality images captured by handheld mobile devices. While OCR of high-quality scanned documents is a mature field where many commercial tools are available, and large datasets of text in the wild exist, no existing datasets can be used to develop and test document OCR methods robust to non-uniform lighting, image blur, strong noise, built-in denoising, sharpening, compression and other artifacts present in many photographs from mobile devices. This dataset contains 2 113 unique pages from random scientific papers, which were photographed by multiple people using 23 different mobile devices. The resulting 19 728 photographs of various visual quality are accompanied by precise positions and text annotations of 500k text lines. We further provide an evaluation methodology, including an evaluation server and a testset with non-public annotations. We provide a state-of-the-art text recognition baseline build on convolutional and recurrent neural networks trained with Connectionist Temporal Classification loss. This baseline achieves 2 %, 22 % and 73 % word error rates on easy, medium and hard parts of the dataset, respectively, confirming that the dataset is challenging. The presented dataset will enable future development and evaluation of document analysis for low-quality images. It is primarily intended for line-level text recognition, and can be further used for line localization, layout analysis, image restoration and text binarization.