 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAT-ST: Self-Training Adaptation Strategy for OCR in Domains with Limited Transcriptions
Paper and Code
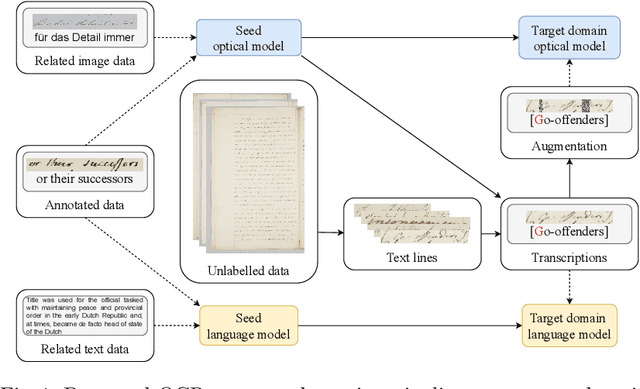
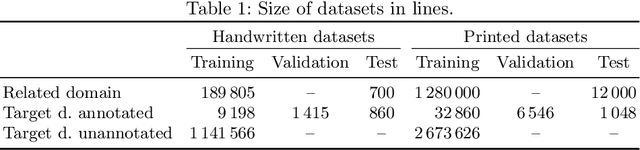

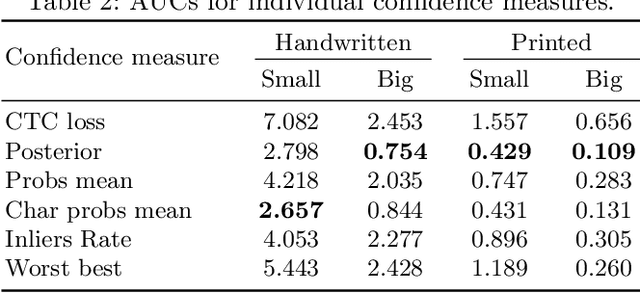
This paper addresses text recognition for domains with limited manual annotations by a simple self-training strategy. Our approach should reduce human annotation effort when target domain data is plentiful, such as when transcribing a collection of single person's correspondence or a large manuscript. We propose to train a seed system on large scale data from related domains mixed with available annotated data from the target domain. The seed system transcribes the unannotated data from the target domain which is then used to train a better system. We study several confidence measures and eventually decide to use the posterior probability of a transcription for data selection. Additionally, we propose to augment the data using an aggressive masking scheme. By self-training, we achieve up to 55 % reduction in character error rate for handwritten data and up to 38 % on printed data. The masking augmentation itself reduces the error rate by about 10 % and its effect is better pronounced in case of difficult handwritten data.