 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftCTC $\unicode{x2013}$ Semi-Supervised Learning for Text Recognition using Soft Pseudo-Labels
Dec 05, 2022This paper explores semi-supervised training for sequence tasks, such as Optical Character Recognition or Automatic Speech Recognition. We propose a novel loss function $\unicode{x2013}$ SoftCTC $\unicode{x2013}$ which is an extension of CTC allowing to consider multiple transcription variants at the same time. This allows to omit the confidence based filtering step which is otherwise a crucial component of pseudo-labeling approaches to semi-supervised learning. We demonstrate the effectiveness of our method on a challenging handwriting recognition task and conclude that SoftCTC matches the performance of a finely-tuned filtering based pipeline. We also evaluated SoftCTC in terms of computational efficiency, concluding that it is significantly more efficient than a na\"ive CTC-based approach for training on multiple transcription variants, and we make our GPU implementation public.
The Parallel Algorithm for the 2-D Discrete Wavelet Transform
Sep 26, 2017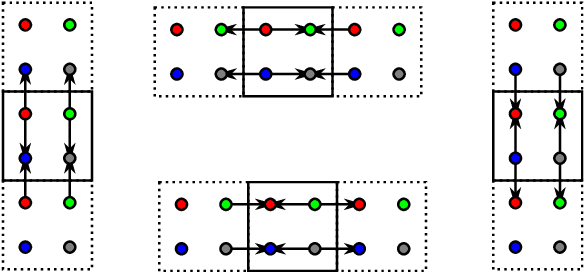



The discrete wavelet transform can be found at the heart of many image-processing algorithms. Until now, the transform on general-purpose processors (CPUs) was mostly computed using a separable lifting scheme. As the lifting scheme consists of a small number of operations, it is preferred for processing using single-core CPUs. However, considering a parallel processing using multi-core processors, this scheme is inappropriate due to a large number of steps. On such architectures, the number of steps corresponds to the number of points that represent the exchange of data. Consequently, these points often form a performance bottleneck. Our approach appropriately rearranges calculations inside the transform, and thereby reduces the number of steps. In other words, we propose a new scheme that is friendly to parallel environments. When evaluating on multi-core CPUs, we consistently overcome the original lifting scheme. The evaluation was performed on 61-core Intel Xeon Phi and 8-core Intel Xeon processors.
Accelerating Discrete Wavelet Transforms on GPUs
May 18, 2017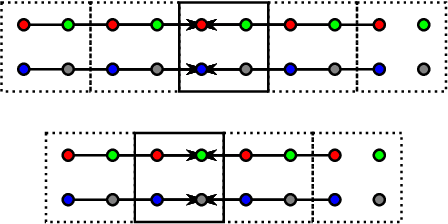

The two-dimensional discrete wavelet transform has a huge number of applications in image-processing techniques. Until now, several papers compared the performance of such transform on graphics processing units (GPUs). However, all of them only dealt with lifting and convolution computation schemes. In this paper, we show that corresponding horizontal and vertical lifting parts of the lifting scheme can be merged into non-separable lifting units, which halves the number of steps. We also discuss an optimization strategy leading to a reduction in the number of arithmetic operations. The schemes were assessed using the OpenCL and pixel shaders. The proposed non-separable lifting scheme outperforms the existing schemes in many cases, irrespective of its higher complexity.
Parallel Wavelet Schemes for Images
Oct 12, 2016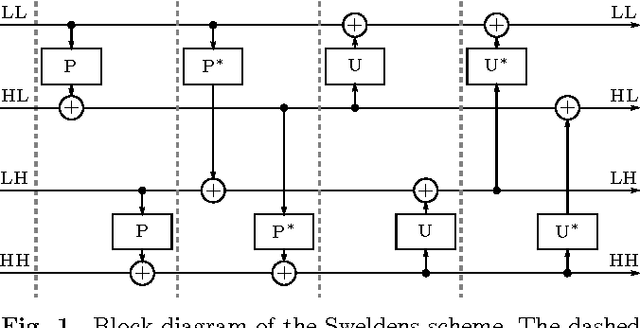
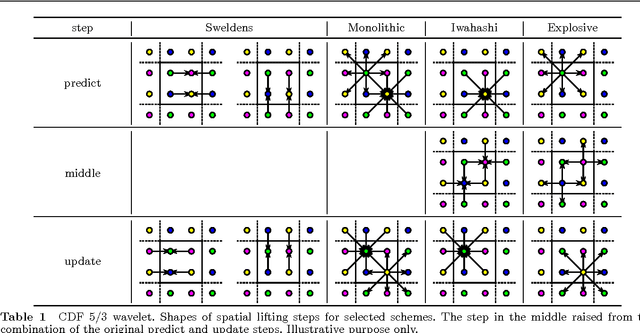
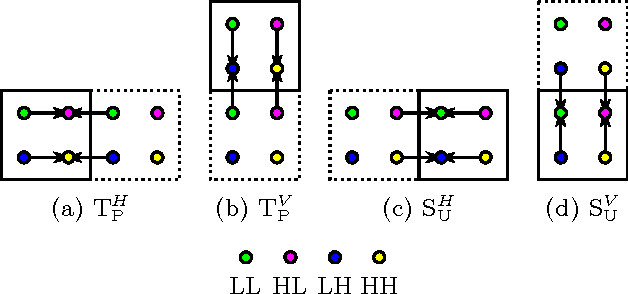
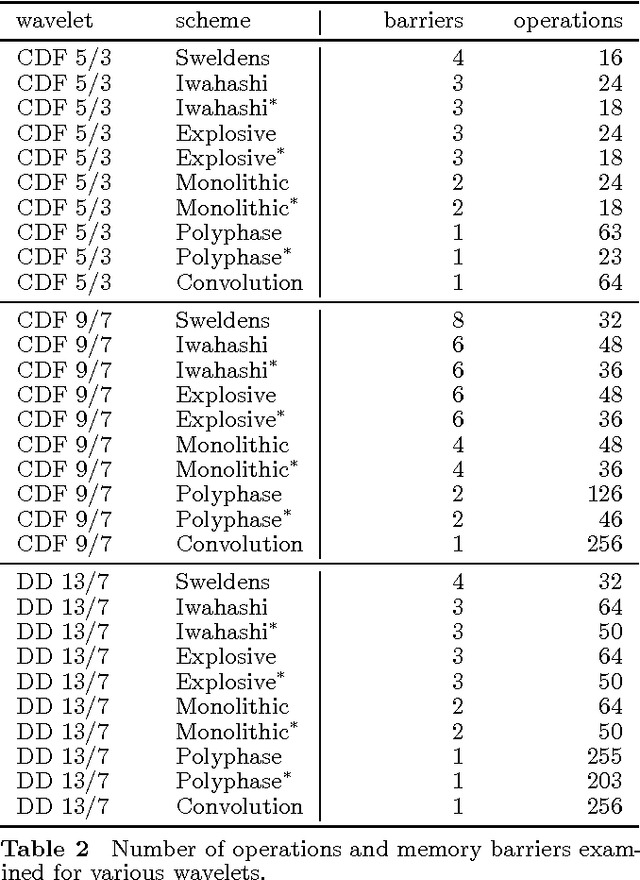
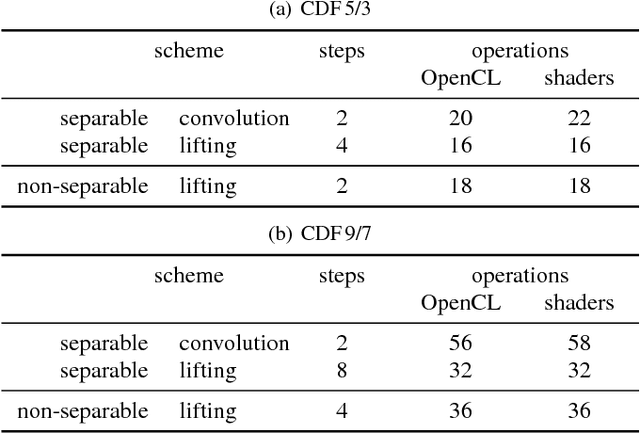
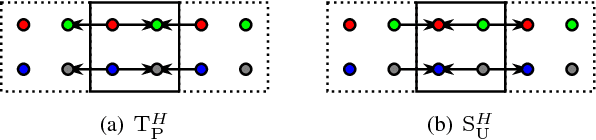
In this paper, we introduce several new schemes for calculation of discrete wavelet transforms of images. These schemes reduce the number of steps and, as a consequence, allow to reduce the number of synchronizations on parallel architectures. As an additional useful property, the proposed schemes can reduce also the number of arithmetic operations. The schemes are primarily demonstrated on CDF 5/3 and CDF 9/7 wavelets employed in JPEG 2000 image compression standard. However, the presented method is general, and it can be applied on any wavelet transform. As a result, our scheme requires only two memory barriers for 2-D CDF 5/3 transform compared to four barriers in the original separable form or three barriers in the non-separable scheme recently published. Our reasoning is supported by exhaustive experiments on high-end graphics cards.