 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dental Landmarks from Intraoral 3D Scans: the 3DTeethLand challenge
Dec 09, 2025Teeth landmark detection is a critical task in modern clinical orthodontics. Their precise identification enables advanced diagnostics, facilitates personalized treatment strategies, and supports more effective monitoring of treatment progress in clinical dentistry. However, several significant challenges may arise due to the intricate geometry of individual teeth and the substantial variations observed across different individuals. To address these complexities, the development of advanced techniques, especially through the application of deep learning, is essential for the precise and reliable detection of 3D tooth landmarks. In this context, the 3DTeethLand challenge was held in collaboration with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2024, calling for algorithms focused on teeth landmark detection from intraoral 3D scans. This challenge introduced the first publicly available dataset for 3D teeth landmark detection, offering a valuable resource to assess the state-of-the-art methods in this task and encourage the community to provide methodological contributions towards the resolution of their problem with significant clinical implications.
Leveraging Point Transformers for Detecting Anatomical Landmarks in Digital Dentistry
Apr 15, 2025The increasing availability of intraoral scanning devices has heightened their importance in modern clinical orthodontics. Clinicians utilize advanced Computer-Aided Design techniques to create patient-specific treatment plans that include laboriously identifying crucial landmarks such as cusps, mesial-distal locations, facial axis points, and tooth-gingiva boundaries. Detecting such landmarks automatically presents challenges, including limited dataset sizes, significant anatomical variability among subjects, and the geometric nature of the data. We present our experiments from the 3DTeethLand Grand Challenge at MICCAI 2024. Our method leverages recent advancements in point cloud learning through transformer architectures. We designed a Point Transformer v3 inspired module to capture meaningful geometric and anatomical features, which are processed by a lightweight decoder to predict per-point distances, further processed by graph-based non-minima suppression. We report promising results and discuss insights on learned feature interpretability.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Page Layout Analysis System for Unconstrained Historic Documents
Feb 23, 2021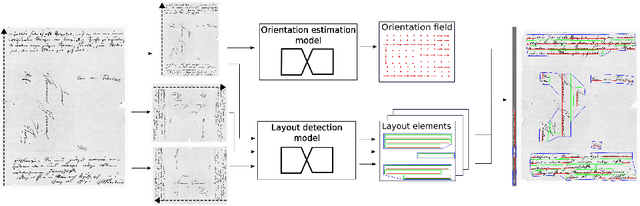
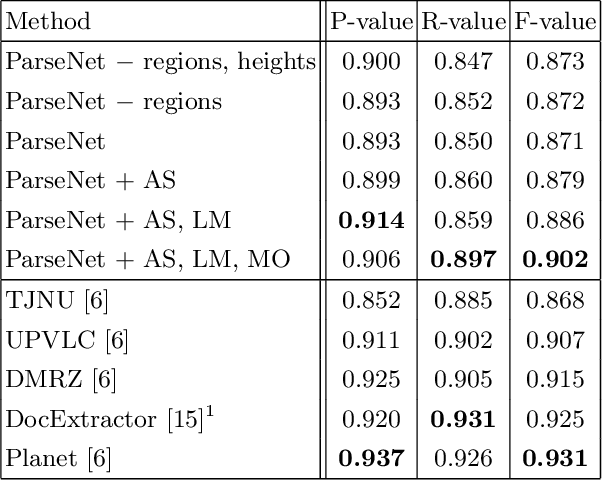

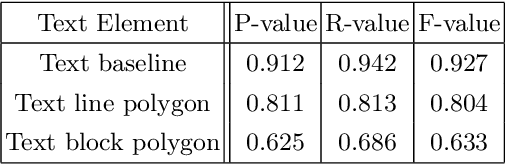
Extraction of text regions and individual text lines from historic documents is necessary for automatic transcription. We propose extending a CNN-based text baseline detection system by adding line height and text block boundary predictions to the model output, allowing the system to extract more comprehensive layout information. We also show that pixel-wise text orientation prediction can be used for processing documents with multiple text orientations. We demonstrate that the proposed method performs well on the cBAD baseline detection dataset. Additionally, we benchmark the method on newly introduced PERO layout dataset which we also make public.
Segmentation of Defective Skulls from CT Data for Tissue Modelling
Nov 20, 2019
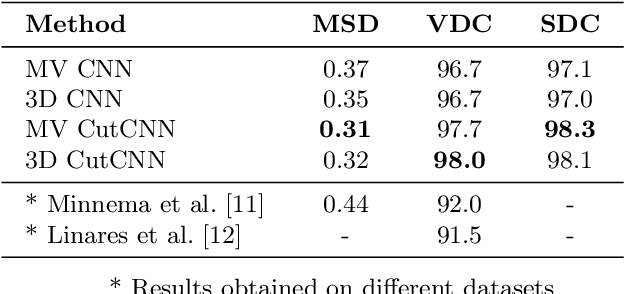


In this work we present a method of automatic segmentation of defective skulls for custom cranial implant design and 3D printing purposes. Since such tissue models are usually required in patient cases with complex anatomical defects and variety of external objects present in the acquired data, most deep learning-based approaches fall short because it is not possible to create a sufficient training dataset that would encompass the spectrum of all possible structures. Because CNN segmentation experiments in this application domain have been so far limited to simple patch-based CNN architectures, we first show how the usage of the encoder-decoder architecture can substantially improve the segmentation accuracy. Then, we show how the number of segmentation artifacts, which usually require manual corrections, can be further reduced by adding a boundary term to CNN training and by globally optimizing the segmentation with graph-cut. Finally, we show that using the proposed method, 3D segmentation accurate enough for clinical application can be achieved with 2D CNN architectures as well as their 3D counterparts.
Brno Mobile OCR Dataset
Jul 02, 2019
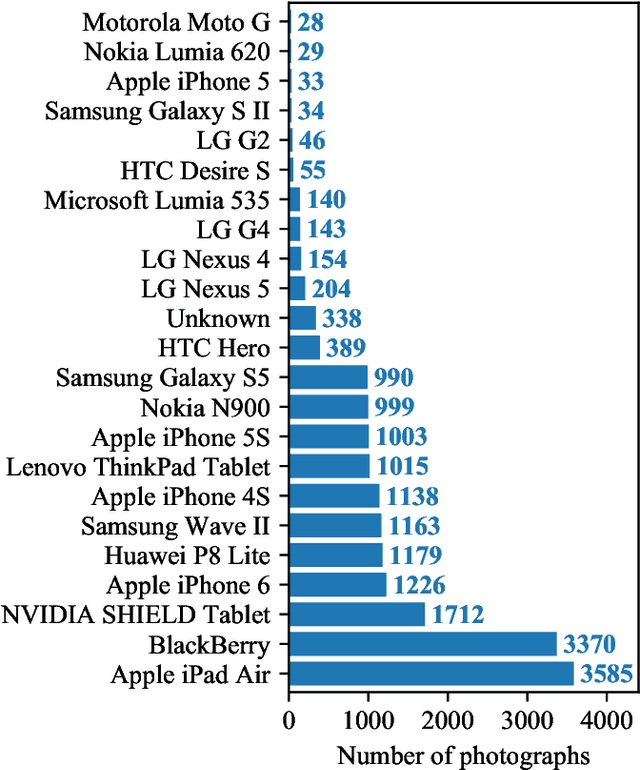

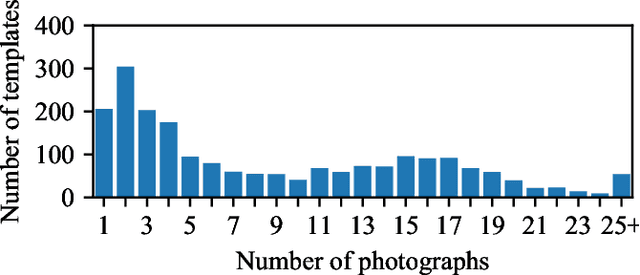
We introduce the Brno Mobile OCR Dataset (B-MOD) for document Optical Character Recognition from low-quality images captured by handheld mobile devices. While OCR of high-quality scanned documents is a mature field where many commercial tools are available, and large datasets of text in the wild exist, no existing datasets can be used to develop and test document OCR methods robust to non-uniform lighting, image blur, strong noise, built-in denoising, sharpening, compression and other artifacts present in many photographs from mobile devices. This dataset contains 2 113 unique pages from random scientific papers, which were photographed by multiple people using 23 different mobile devices. The resulting 19 728 photographs of various visual quality are accompanied by precise positions and text annotations of 500k text lines. We further provide an evaluation methodology, including an evaluation server and a testset with non-public annotations. We provide a state-of-the-art text recognition baseline build on convolutional and recurrent neural networks trained with Connectionist Temporal Classification loss. This baseline achieves 2 %, 22 % and 73 % word error rates on easy, medium and hard parts of the dataset, respectively, confirming that the dataset is challenging. The presented dataset will enable future development and evaluation of document analysis for low-quality images. It is primarily intended for line-level text recognition, and can be further used for line localization, layout analysis, image restoration and text binarization.
Segmentation of Head and Neck Organs at Risk Using CNN with Batch Dice Loss
Dec 06, 2018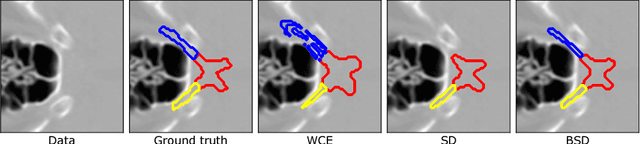
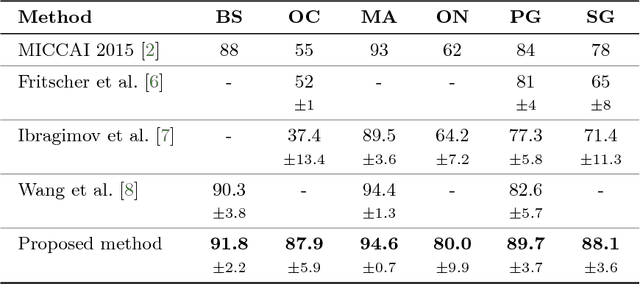
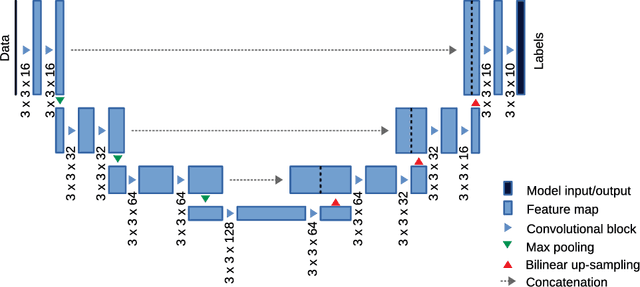
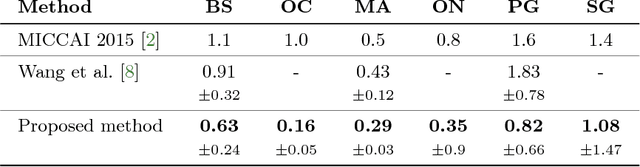
This paper deals with segmentation of organs at risk (OAR) in head and neck area in CT images which is a crucial step for reliable intensity modulated radiotherapy treatment. We introduce a convolution neural network with encoder-decoder architecture and a new loss function, the batch soft Dice loss function, used to train the network. The resulting model produces segmentations of every OAR in the public MICCAI 2015 Head And Neck Auto-Segmentation Challenge dataset. Despite the heavy class imbalance in the data, we improve accuracy of current state-of-the-art methods by 0.33 mm in terms of average surface distance and by 0.11 in terms of Dice overlap coefficient on average.