 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchival Faces: Detection of Faces in Digitized Historical Documents
Apr 01, 2025When digitizing historical archives, it is necessary to search for the faces of celebrities and ordinary people, especially in newspapers, link them to the surrounding text, and make them searchable. Existing face detectors on datasets of scanned historical documents fail remarkably -- current detection tools only achieve around $24\%$ mAP at $50:90\%$ IoU. This work compensates for this failure by introducing a new manually annotated domain-specific dataset in the style of the popular Wider Face dataset, containing 2.2k new images from digitized historical newspapers from the $19^{th}$ to $20^{th}$ century, with 11k new bounding-box annotations and associated facial landmarks. This dataset allows existing detectors to be retrained to bring their results closer to the standard in the field of face detection in the wild. We report several experimental results comparing different families of fine-tuned detectors against publicly available pre-trained face detectors and ablation studies of multiple detector sizes with comprehensive detection and landmark prediction performance results.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

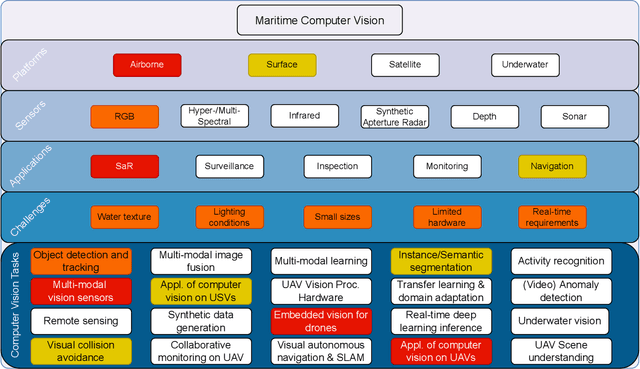
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Segmentation of Defective Skulls from CT Data for Tissue Modelling
Nov 20, 2019


In this work we present a method of automatic segmentation of defective skulls for custom cranial implant design and 3D printing purposes. Since such tissue models are usually required in patient cases with complex anatomical defects and variety of external objects present in the acquired data, most deep learning-based approaches fall short because it is not possible to create a sufficient training dataset that would encompass the spectrum of all possible structures. Because CNN segmentation experiments in this application domain have been so far limited to simple patch-based CNN architectures, we first show how the usage of the encoder-decoder architecture can substantially improve the segmentation accuracy. Then, we show how the number of segmentation artifacts, which usually require manual corrections, can be further reduced by adding a boundary term to CNN training and by globally optimizing the segmentation with graph-cut. Finally, we show that using the proposed method, 3D segmentation accurate enough for clinical application can be achieved with 2D CNN architectures as well as their 3D counterparts.
Learning Feature Aggregation in Temporal Domain for Re-Identification
Mar 12, 2019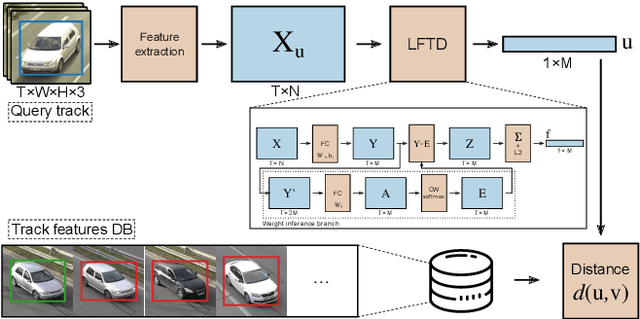

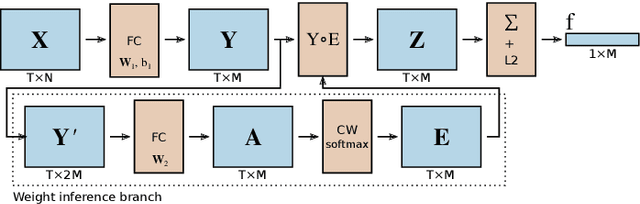

Person re-identification is a standard and established problem in the computer vision community. In recent years, vehicle re-identification is also getting more attention. In this paper, we focus on both these tasks and propose a method for aggregation of features in temporal domain as it is common to have multiple observations of the same object. The aggregation is based on weighting different elements of the feature vectors by different weights and it is trained in an end-to-end manner by a Siamese network. The experimental results show that our method outperforms other existing methods for feature aggregation in temporal domain on both vehicle and person re-identification tasks. Furthermore, to push research in vehicle re-identification further, we introduce a novel dataset CarsReId74k. The dataset is not limited to frontal/rear viewpoints. It contains 17,681 unique vehicles, 73,976 observed tracks, and 277,236 positive pairs. The dataset was captured by 66 cameras from various angles.
Segmentation of Head and Neck Organs at Risk Using CNN with Batch Dice Loss
Dec 06, 2018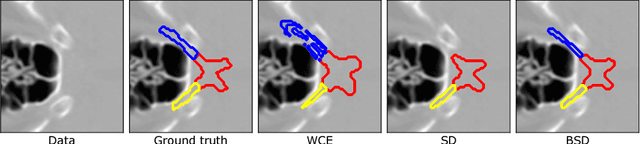
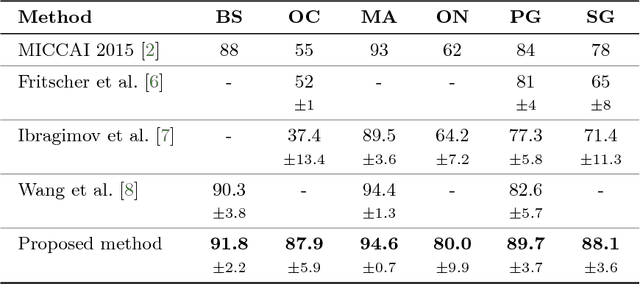
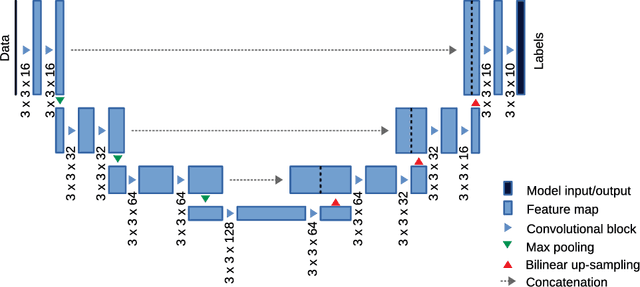
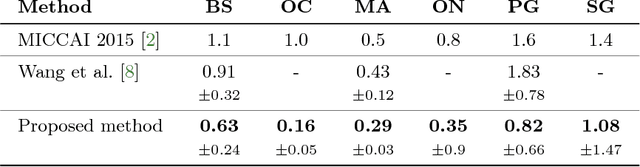
This paper deals with segmentation of organs at risk (OAR) in head and neck area in CT images which is a crucial step for reliable intensity modulated radiotherapy treatment. We introduce a convolution neural network with encoder-decoder architecture and a new loss function, the batch soft Dice loss function, used to train the network. The resulting model produces segmentations of every OAR in the public MICCAI 2015 Head And Neck Auto-Segmentation Challenge dataset. Despite the heavy class imbalance in the data, we improve accuracy of current state-of-the-art methods by 0.33 mm in terms of average surface distance and by 0.11 in terms of Dice overlap coefficient on average.
Comprehensive Data Set for Automatic Single Camera Visual Speed Measurement
May 09, 2018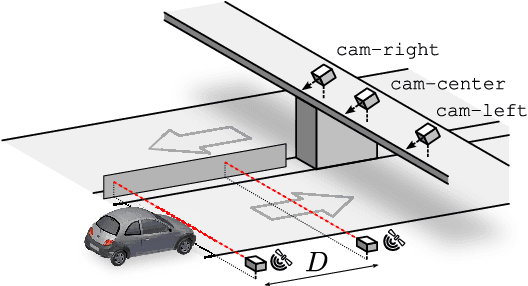


In this paper, we focus on traffic camera calibration and a visual speed measurement from a single monocular camera, which is an important task of visual traffic surveillance. Existing methods addressing this problem are difficult to compare due to a lack of a common data set with reliable ground truth. Therefore, it is not clear how the methods compare in various aspects and what factors are affecting their performance. We captured a new data set of 18 full-HD videos, each around 1 hr long, captured at six different locations. Vehicles in the videos (20865 instances in total) are annotated with the precise speed measurements from optical gates using LiDAR and verified with several reference GPS tracks. We made the data set available for download and it contains the videos and metadata (calibration, lengths of features in image, annotations, and so on) for future comparison and evaluation. Camera calibration is the most crucial part of the speed measurement; therefore, we provide a brief overview of the methods and analyze a recently published method for fully automatic camera calibration and vehicle speed measurement and report the results on this data set in detail.
BoxCars: Improving Fine-Grained Recognition of Vehicles using 3-D Bounding Boxes in Traffic Surveillance
Mar 09, 2018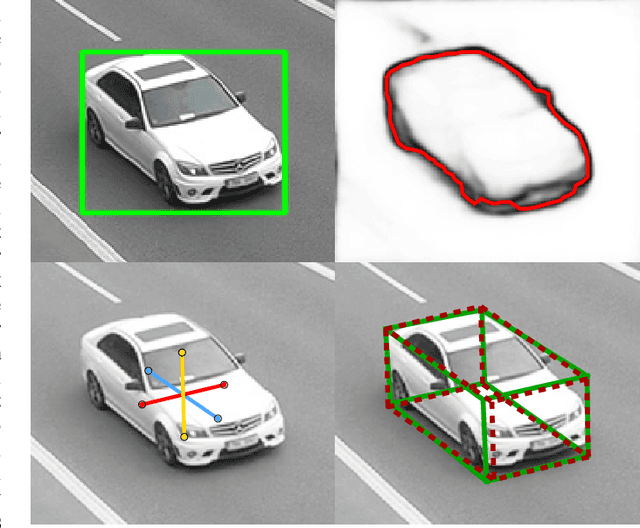



In this paper, we focus on fine-grained recognition of vehicles mainly in traffic surveillance applications. We propose an approach that is orthogonal to recent advancements in fine-grained recognition (automatic part discovery and bilinear pooling). In addition, in contrast to other methods focused on fine-grained recognition of vehicles, we do not limit ourselves to a frontal/rear viewpoint, but allow the vehicles to be seen from any viewpoint. Our approach is based on 3-D bounding boxes built around the vehicles. The bounding box can be automatically constructed from traffic surveillance data. For scenarios where it is not possible to use precise construction, we propose a method for an estimation of the 3-D bounding box. The 3-D bounding box is used to normalize the image viewpoint by "unpacking" the image into a plane. We also propose to randomly alter the color of the image and add a rectangle with random noise to a random position in the image during the training of convolutional neural networks (CNNs). We have collected a large fine-grained vehicle data set BoxCars116k, with 116k images of vehicles from various viewpoints taken by numerous surveillance cameras. We performed a number of experiments, which show that our proposed method significantly improves CNN classification accuracy (the accuracy is increased by up to 12% points and the error is reduced by up to 50% compared with CNNs without the proposed modifications). We also show that our method outperforms the state-of-the-art methods for fine-grained recognition.
CNN for IMU Assisted Odometry Estimation using Velodyne LiDAR
Dec 18, 2017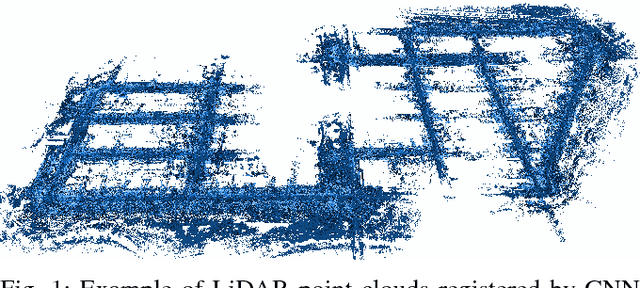
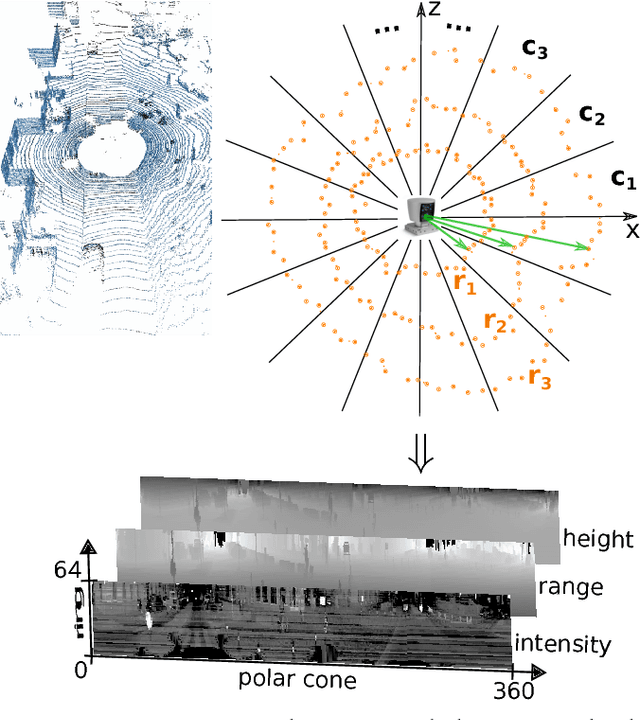
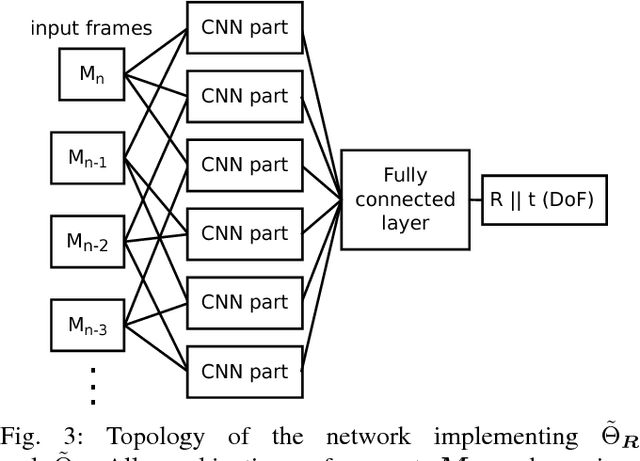
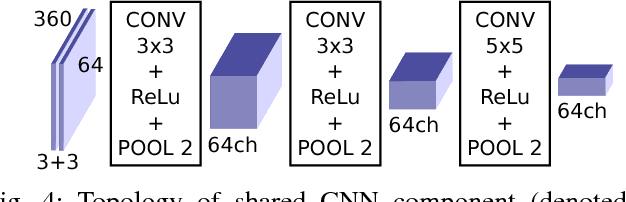
We introduce a novel method for odometry estimation using convolutional neural networks from 3D LiDAR scans. The original sparse data are encoded into 2D matrices for the training of proposed networks and for the prediction. Our networks show significantly better precision in the estimation of translational motion parameters comparing with state of the art method LOAM, while achieving real-time performance. Together with IMU support, high quality odometry estimation and LiDAR data registration is realized. Moreover, we propose alternative CNNs trained for the prediction of rotational motion parameters while achieving results also comparable with state of the art. The proposed method can replace wheel encoders in odometry estimation or supplement missing GPS data, when the GNSS signal absents (e.g. during the indoor mapping). Our solution brings real-time performance and precision which are useful to provide online preview of the mapping results and verification of the map completeness in real time.
CNN for Very Fast Ground Segmentation in Velodyne LiDAR Data
Sep 07, 2017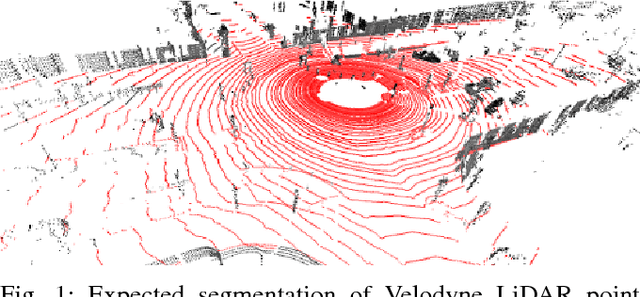

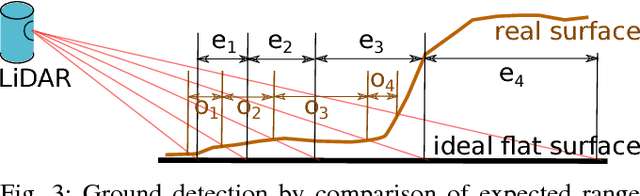
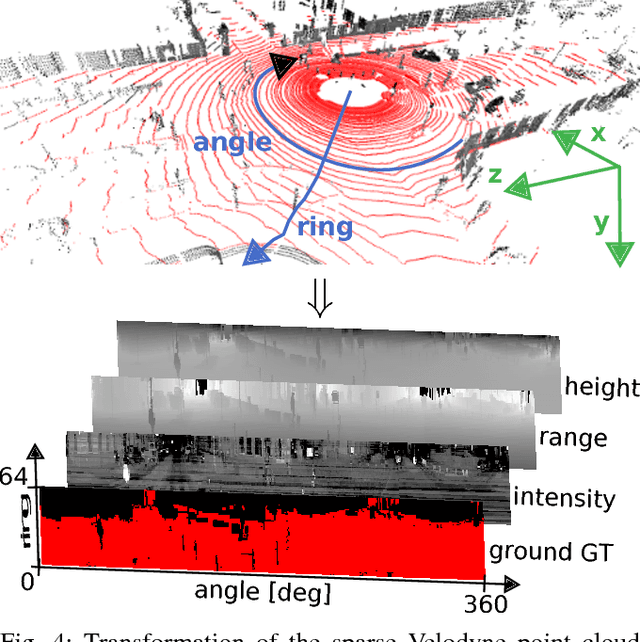
This paper presents a novel method for ground segmentation in Velodyne point clouds. We propose an encoding of sparse 3D data from the Velodyne sensor suitable for training a convolutional neural network (CNN). This general purpose approach is used for segmentation of the sparse point cloud into ground and non-ground points. The LiDAR data are represented as a multi-channel 2D signal where the horizontal axis corresponds to the rotation angle and the vertical axis the indexes channels (i.e. laser beams). Multiple topologies of relatively shallow CNNs (i.e. 3-5 convolutional layers) are trained and evaluated using a manually annotated dataset we prepared. The results show significant improvement of performance over the state-of-the-art method by Zhang et al. in terms of speed and also minor improvements in terms of accuracy.
Traffic Surveillance Camera Calibration by 3D Model Bounding Box Alignment for Accurate Vehicle Speed Measurement
Jun 01, 2017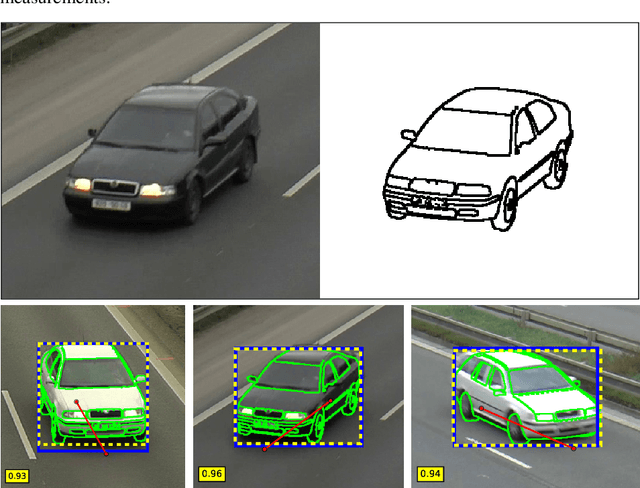
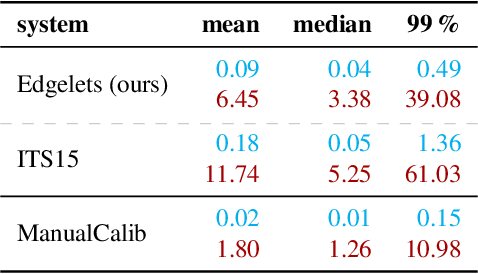


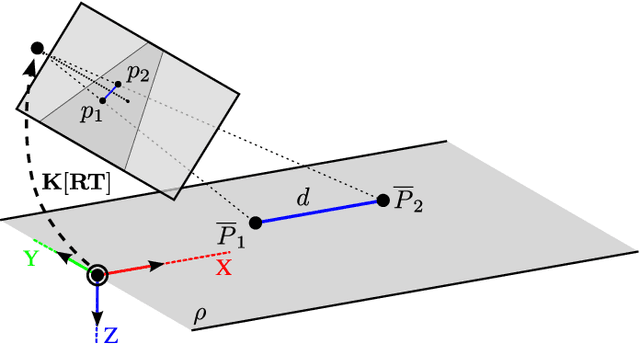
In this paper, we focus on fully automatic traffic surveillance camera calibration, which we use for speed measurement of passing vehicles. We improve over a recent state-of-the-art camera calibration method for traffic surveillance based on two detected vanishing points. More importantly, we propose a novel automatic scene scale inference method. The method is based on matching bounding boxes of rendered 3D models of vehicles with detected bounding boxes in the image. The proposed method can be used from arbitrary viewpoints, since it has no constraints on camera placement. We evaluate our method on the recent comprehensive dataset for speed measurement BrnoCompSpeed. Experiments show that our automatic camera calibration method by detection of two vanishing points reduces error by 50% (mean distance ratio error reduced from 0.18 to 0.09) compared to the previous state-of-the-art method. We also show that our scene scale inference method is more precise, outperforming both state-of-the-art automatic calibration method for speed measurement (error reduction by 86% -- 7.98km/h to 1.10km/h) and manual calibration (error reduction by 19% -- 1.35km/h to 1.10km/h). We also present qualitative results of the proposed automatic camera calibration method on video sequences obtained from real surveillance cameras in various places, and under different lighting conditions (night, dawn, day).