 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Efficient Multi-Scale Fovea for Semantic-Based Visual Search Attention
Apr 04, 2026Semantics are one of the primary sources of top-down preattentive information. Modern deep object detectors excel at extracting such valuable semantic cues from complex visual scenes. However, the size of the visual input to be processed by these detectors can become a bottleneck, particularly in terms of time costs, affecting an artificial attention system's biological plausibility and real-time deployability. Inspired by classical exponential density roll-off topologies, we apply a new artificial foveation module to our novel attention prediction pipeline: the Semantic-based Bayesian Attention (SemBA) framework. We aim at reducing detection-related computational costs without compromising visual task accuracy, thereby making SemBA more biologically plausible. The proposed multi-scale pyramidal field-of-view retains maximum acuity at an innermost level, around a focal point, while gradually increasing distortion for outer levels to mimic peripheral uncertainty via downsampling. In this work we evaluate the performance of our novel Multi-Scale Fovea, incorporated into \textit{SemBA}, on target-present visual search. We also compare it against other artificial foveal systems, and conduct ablation studies with different deep object detection models to assess the impact of the new topology in terms of computational costs. We experimentally demonstrate that including the new Multi-Scale Fovea module effectively reduces inherent processing costs while improving SemBA's scanpath prediction accuracy. Remarkably, we show that SemBA closely approximates human consistency while retaining the actual human fovea's proportions.
Integrating Deep RL and Bayesian Inference for ObjectNav in Mobile Robotics
Mar 26, 2026Autonomous object search is challenging for mobile robots operating in indoor environments due to partial observability, perceptual uncertainty, and the need to trade off exploration and navigation efficiency. Classical probabilistic approaches explicitly represent uncertainty but typically rely on handcrafted action-selection heuristics, while deep reinforcement learning enables adaptive policies but often suffers from slow convergence and limited interpretability. This paper proposes a hybrid object-search framework that integrates Bayesian inference with deep reinforcement learning. The method maintains a spatial belief map over target locations, updated online through Bayesian inference from calibrated object detections, and trains a reinforcement learning policy to select navigation actions directly from this probabilistic representation. The approach is evaluated in realistic indoor simulation using Habitat 3.0 and compared against developed baseline strategies. Across two indoor environments, the proposed method improves success rate while reducing search effort. Overall, the results support the value of combining Bayesian belief estimation with learned action selection to achieve more efficient and reliable objectsearch behavior under partial observability.
Generalized Referring Expression Segmentation on Aerial Photos
Dec 08, 2025Referring expression segmentation is a fundamental task in computer vision that integrates natural language understanding with precise visual localization of target regions. Considering aerial imagery (e.g., modern aerial photos collected through drones, historical photos from aerial archives, high-resolution satellite imagery, etc.) presents unique challenges because spatial resolution varies widely across datasets, the use of color is not consistent, targets often shrink to only a few pixels, and scenes contain very high object densities and objects with partial occlusions. This work presents Aerial-D, a new large-scale referring expression segmentation dataset for aerial imagery, comprising 37,288 images with 1,522,523 referring expressions that cover 259,709 annotated targets, spanning across individual object instances, groups of instances, and semantic regions covering 21 distinct classes that range from vehicles and infrastructure to land coverage types. The dataset was constructed through a fully automatic pipeline that combines systematic rule-based expression generation with a Large Language Model (LLM) enhancement procedure that enriched both the linguistic variety and the focus on visual details within the referring expressions. Filters were additionally used to simulate historic imaging conditions for each scene. We adopted the RSRefSeg architecture, and trained models on Aerial-D together with prior aerial datasets, yielding unified instance and semantic segmentation from text for both modern and historical images. Results show that the combined training achieves competitive performance on contemporary benchmarks, while maintaining strong accuracy under monochrome, sepia, and grainy degradations that appear in archival aerial photography. The dataset, trained models, and complete software pipeline are publicly available at https://luispl77.github.io/aerial-d .
Comprehension of Multilingual Expressions Referring to Target Objects in Visual Inputs
Nov 14, 2025Referring Expression Comprehension (REC) requires models to localize objects in images based on natural language descriptions. Research on the area remains predominantly English-centric, despite increasing global deployment demands. This work addresses multilingual REC through two main contributions. First, we construct a unified multilingual dataset spanning 10 languages, by systematically expanding 12 existing English REC benchmarks through machine translation and context-based translation enhancement. The resulting dataset comprises approximately 8 million multilingual referring expressions across 177,620 images, with 336,882 annotated objects. Second, we introduce an attention-anchored neural architecture that uses multilingual SigLIP2 encoders. Our attention-based approach generates coarse spatial anchors from attention distributions, which are subsequently refined through learned residuals. Experimental evaluation demonstrates competitive performance on standard benchmarks, e.g. achieving 86.9% accuracy at IoU@50 on RefCOCO aggregate multilingual evaluation, compared to an English-only result of 91.3%. Multilingual evaluation shows consistent capabilities across languages, establishing the practical feasibility of multilingual visual grounding systems. The dataset and model are available at $\href{https://multilingual.franreno.com}{multilingual.franreno.com}$.
Frame-Level Real-Time Assessment of Stroke Rehabilitation Exercises from Video-Level Labeled Data: Task-Specific vs. Foundation Models
Jun 04, 2025The growing demands of stroke rehabilitation have increased the need for solutions to support autonomous exercising. Virtual coaches can provide real-time exercise feedback from video data, helping patients improve motor function and keep engagement. However, training real-time motion analysis systems demands frame-level annotations, which are time-consuming and costly to obtain. In this work, we present a framework that learns to classify individual frames from video-level annotations for real-time assessment of compensatory motions in rehabilitation exercises. We use a gradient-based technique and a pseudo-label selection method to create frame-level pseudo-labels for training a frame-level classifier. We leverage pre-trained task-specific models - Action Transformer, SkateFormer - and a foundation model - MOMENT - for pseudo-label generation, aiming to improve generalization to new patients. To validate the approach, we use the \textit{SERE} dataset with 18 post-stroke patients performing five rehabilitation exercises annotated on compensatory motions. MOMENT achieves better video-level assessment results (AUC = $73\%$), outperforming the baseline LSTM (AUC = $58\%$). The Action Transformer, with the Integrated Gradient technique, leads to better outcomes (AUC = $72\%$) for frame-level assessment, outperforming the baseline trained with ground truth frame-level labeling (AUC = $69\%$). We show that our proposed approach with pre-trained models enhances model generalization ability and facilitates the customization to new patients, reducing the demands of data labeling.
MIL vs. Aggregation: Evaluating Patient-Level Survival Prediction Strategies Using Graph-Based Learning
Mar 29, 2025Oncologists often rely on a multitude of data, including whole-slide images (WSIs), to guide therapeutic decisions, aiming for the best patient outcome. However, predicting the prognosis of cancer patients can be a challenging task due to tumor heterogeneity and intra-patient variability, and the complexity of analyzing WSIs. These images are extremely large, containing billions of pixels, making direct processing computationally expensive and requiring specialized methods to extract relevant information. Additionally, multiple WSIs from the same patient may capture different tumor regions, some being more informative than others. This raises a fundamental question: Should we use all WSIs to characterize the patient, or should we identify the most representative slide for prognosis? Our work seeks to answer this question by performing a comparison of various strategies for predicting survival at the WSI and patient level. The former treats each WSI as an independent sample, mimicking the strategy adopted in other works, while the latter comprises methods to either aggregate the predictions of the several WSIs or automatically identify the most relevant slide using multiple-instance learning (MIL). Additionally, we evaluate different Graph Neural Networks architectures under these strategies. We conduct our experiments using the MMIST-ccRCC dataset, which comprises patients with clear cell renal cell carcinoma (ccRCC). Our results show that MIL-based selection improves accuracy, suggesting that choosing the most representative slide benefits survival prediction.
Investigating an Intelligent System to Monitor \& Explain Abnormal Activity Patterns of Older Adults
Jan 30, 2025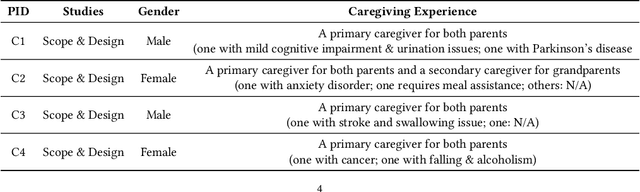
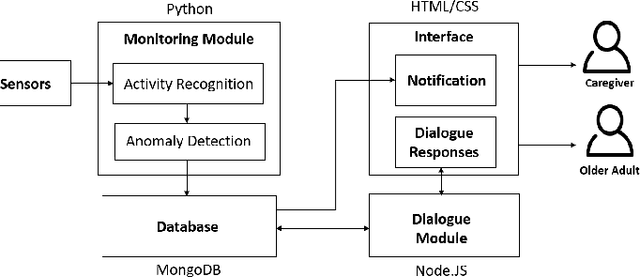

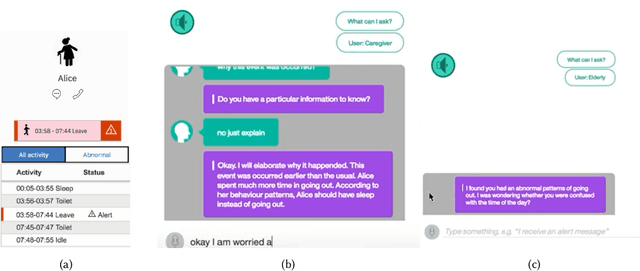
Despite the growing potential of older adult care technologies, the adoption of these technologies remains challenging. In this work, we conducted a focus-group session with family caregivers to scope designs of the older adult care technology. We then developed a high-fidelity prototype and conducted its qualitative study with professional caregivers and older adults to understand their perspectives on the system functionalities. This system monitors abnormal activity patterns of older adults using wireless motion sensors and machine learning models and supports interactive dialogue responses to explain abnormal activity patterns of older adults to caregivers and allow older adults proactively sharing their status with caregivers for an adequate intervention. Both older adults and professional caregivers appreciated that our system can provide a faster, personalized service while proactively controlling what information is to be shared through interactive dialogue responses. We further discuss other considerations to realize older adult technology in practice.
Semantic-Based Active Perception for Humanoid Visual Tasks with Foveal Sensors
Apr 16, 2024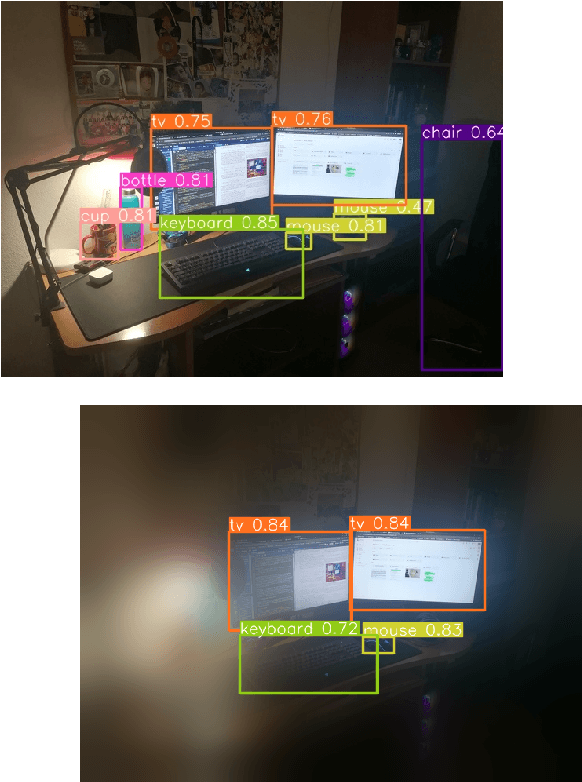
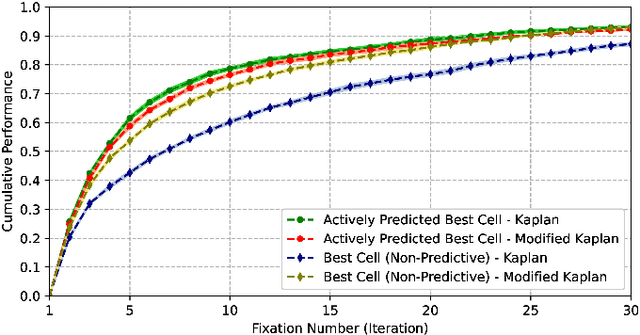
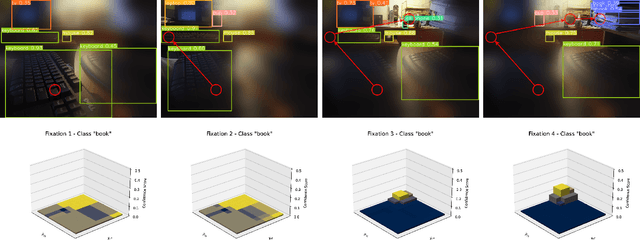
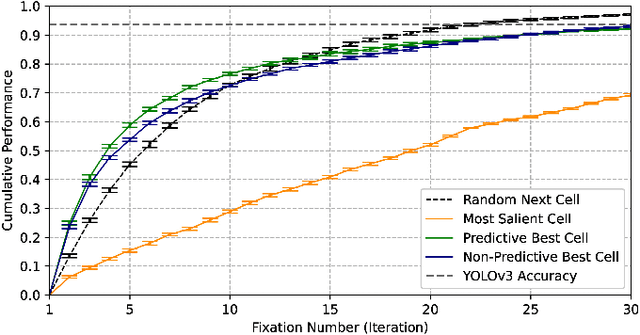
The aim of this work is to establish how accurately a recent semantic-based foveal active perception model is able to complete visual tasks that are regularly performed by humans, namely, scene exploration and visual search. This model exploits the ability of current object detectors to localize and classify a large number of object classes and to update a semantic description of a scene across multiple fixations. It has been used previously in scene exploration tasks. In this paper, we revisit the model and extend its application to visual search tasks. To illustrate the benefits of using semantic information in scene exploration and visual search tasks, we compare its performance against traditional saliency-based models. In the task of scene exploration, the semantic-based method demonstrates superior performance compared to the traditional saliency-based model in accurately representing the semantic information present in the visual scene. In visual search experiments, searching for instances of a target class in a visual field containing multiple distractors shows superior performance compared to the saliency-driven model and a random gaze selection algorithm. Our results demonstrate that semantic information, from the top-down, influences visual exploration and search tasks significantly, suggesting a potential area of research for integrating it with traditional bottom-up cues.
Pose-free object classification from surface contact features in sequences of Robotic grasps
Mar 28, 2024In this work, we propose two cost efficient methods for object identification, using a multi-fingered robotic hand equipped with proprioceptive sensing. Both methods are trained on known objects and rely on a limited set of features, obtained during a few grasps on an object. Contrary to most methods in the literature, our methods do not rely on the knowledge of the relative pose between object and hand, which greatly expands the domain of application. However, if that knowledge is available, we propose an additional active exploration step that reduces the overall number of grasps required for a good recognition of the object. One of the methods depends on the contact positions and normals and the other depends on the contact positions alone. We test the proposed methods in the GraspIt! simulator and show that haptic-based object classification is possible in pose-free conditions. We evaluate the parameters that produce the most accurate results and require the least number of grasps for classification.
Finding safe 3D robot grasps through efficient haptic exploration with unscented Bayesian optimization and collision penalty
Feb 10, 2024Robust grasping is a major, and still unsolved, problem in robotics. Information about the 3D shape of an object can be obtained either from prior knowledge (e.g., accurate models of known objects or approximate models of familiar objects) or real-time sensing (e.g., partial point clouds of unknown objects) and can be used to identify good potential grasps. However, due to modeling and sensing inaccuracies, local exploration is often needed to refine such grasps and successfully apply them in the real world. The recently proposed unscented Bayesian optimization technique can make such exploration safer by selecting grasps that are robust to uncertainty in the input space (e.g., inaccuracies in the grasp execution). Extending our previous work on 2D optimization, in this paper we propose a 3D haptic exploration strategy that combines unscented Bayesian optimization with a novel collision penalty heuristic to find safe grasps in a very efficient way: while by augmenting the search-space to 3D we are able to find better grasps, the collision penalty heuristic allows us to do so without increasing the number of exploration steps.
* 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)