 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed simulation framework for realistic sonar image generation and statistical validation
May 19, 2026Synthetic sonar datasets offer a scalable alternative to costly real-world acquisition, yet their utility remains limited by the absence of rigorous quantitative validation. We present ACOUSIM (ACOustic SIMulation and Validation Platform), a physics-informed framework that evaluates the statistical alignment between synthetic and real sonar imagery without relying on generative models. A Gazebo-based environment generates sonar-like images by explicitly controlling seabed texture, illumination-driven shadowing, platform altitude, and noise. Realism is quantified against two public sonar datasets, SeabedObjects-KLSG-II and Sonar Common Target Detection (SCTD), using global intensity and local texture (LBP) distributions assessed via Kullback-Leibler divergence, Jensen-Shannon divergence, and Earth Mover's Distance. Results show strong texture alignment (KL < 0.07) across all classes, with plane-class intensity alignment outperforming ship-class due to shadow geometry complexity. ACOUSIM establishes a reproducible, distribution-level baseline for sim-to-real sonar evaluation and directly supports reliable dataset validation for underwater image analysis.
Dynamic Class-Aware Active Learning for Unbiased Satellite Image Segmentation
Apr 10, 2026Semantic segmentation of satellite imagery plays a vital role in land cover mapping and environmental monitoring. However, annotating large-scale, high-resolution satellite datasets is costly and time consuming, especially when covering vast geographic regions. Instead of randomly labeling data or exhaustively annotating entire datasets, Active Learning (AL) offers an efficient alternative by intelligently selecting the most informative samples for annotation with the help of Human-in-the-loop (HITL), thereby reducing labeling costs while maintaining high model performance. AL is particularly beneficial for large-scale or resource-constrained satellite applications, as it enables high segmentation accuracy with significantly fewer labeled samples. Despite these advantages, standard AL strategies typically rely on global uncertainty or diversity measures and lack the adaptability to target underperforming or rare classes as training progresses, leading to bias in the system. To overcome these limitations, we propose a novel adaptive acquisition function, Dynamic Class-Aware Uncertainty based Active learning (DCAU-AL) that prioritizes sample selection based on real-time class-wise performance gaps, thereby overcoming class-imbalance issue. The proposed DCAU-AL mechanism continuously tracks the performance of the segmentation per class and dynamically adjusts the sampling weights to focus on poorly performing or underrepresented classes throughout the active learning process. Extensive experiments on the OpenEarth land cover dataset show that DCAU-AL significantly outperforms existing AL methods, especially under severe class imbalance, delivering superior per-class IoU and improved annotation efficiency.
Replay to Remember (R2R): An Efficient Uncertainty-driven Unsupervised Continual Learning Framework Using Generative Replay
May 07, 2025Continual Learning entails progressively acquiring knowledge from new data while retaining previously acquired knowledge, thereby mitigating ``Catastrophic Forgetting'' in neural networks. Our work presents a novel uncertainty-driven Unsupervised Continual Learning framework using Generative Replay, namely ``Replay to Remember (R2R)''. The proposed R2R architecture efficiently uses unlabelled and synthetic labelled data in a balanced proportion using a cluster-level uncertainty-driven feedback mechanism and a VLM-powered generative replay module. Unlike traditional memory-buffer methods that depend on pretrained models and pseudo-labels, our R2R framework operates without any prior training. It leverages visual features from unlabeled data and adapts continuously using clustering-based uncertainty estimation coupled with dynamic thresholding. Concurrently, a generative replay mechanism along with DeepSeek-R1 powered CLIP VLM produces labelled synthetic data representative of past experiences, resembling biological visual thinking that replays memory to remember and act in new, unseen tasks. Extensive experimental analyses are carried out in CIFAR-10, CIFAR-100, CINIC-10, SVHN and TinyImageNet datasets. Our proposed R2R approach improves knowledge retention, achieving a state-of-the-art performance of 98.13%, 73.06%, 93.41%, 95.18%, 59.74%, respectively, surpassing state-of-the-art performance by over 4.36%.
PRIMEDrive-CoT: A Precognitive Chain-of-Thought Framework for Uncertainty-Aware Object Interaction in Driving Scene Scenario
Apr 08, 2025Driving scene understanding is a critical real-world problem that involves interpreting and associating various elements of a driving environment, such as vehicles, pedestrians, and traffic signals. Despite advancements in autonomous driving, traditional pipelines rely on deterministic models that fail to capture the probabilistic nature and inherent uncertainty of real-world driving. To address this, we propose PRIMEDrive-CoT, a novel uncertainty-aware model for object interaction and Chain-of-Thought (CoT) reasoning in driving scenarios. In particular, our approach combines LiDAR-based 3D object detection with multi-view RGB references to ensure interpretable and reliable scene understanding. Uncertainty and risk assessment, along with object interactions, are modelled using Bayesian Graph Neural Networks (BGNNs) for probabilistic reasoning under ambiguous conditions. Interpretable decisions are facilitated through CoT reasoning, leveraging object dynamics and contextual cues, while Grad-CAM visualizations highlight attention regions. Extensive evaluations on the DriveCoT dataset demonstrate that PRIMEDrive-CoT outperforms state-of-the-art CoT and risk-aware models.
Synth-SONAR: Sonar Image Synthesis with Enhanced Diversity and Realism via Dual Diffusion Models and GPT Prompting
Oct 11, 2024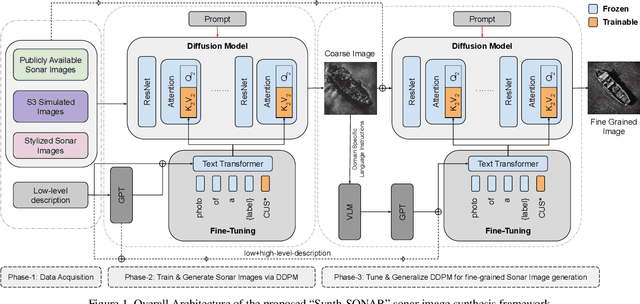
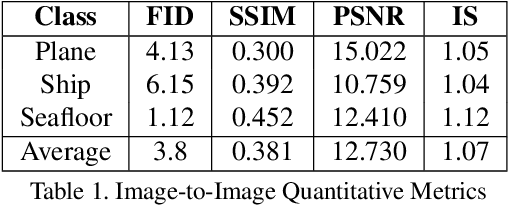
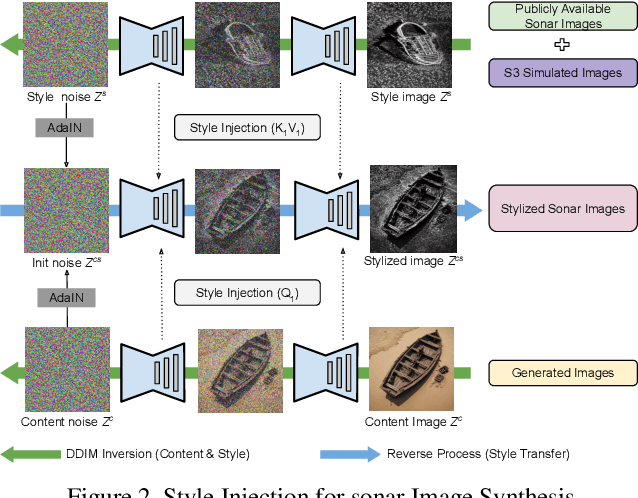

Sonar image synthesis is crucial for advancing applications in underwater exploration, marine biology, and defence. Traditional methods often rely on extensive and costly data collection using sonar sensors, jeopardizing data quality and diversity. To overcome these limitations, this study proposes a new sonar image synthesis framework, Synth-SONAR leveraging diffusion models and GPT prompting. The key novelties of Synth-SONAR are threefold: First, by integrating Generative AI-based style injection techniques along with publicly available real/simulated data, thereby producing one of the largest sonar data corpus for sonar research. Second, a dual text-conditioning sonar diffusion model hierarchy synthesizes coarse and fine-grained sonar images with enhanced quality and diversity. Third, high-level (coarse) and low-level (detailed) text-based sonar generation methods leverage advanced semantic information available in visual language models (VLMs) and GPT-prompting. During inference, the method generates diverse and realistic sonar images from textual prompts, bridging the gap between textual descriptions and sonar image generation. This marks the application of GPT-prompting in sonar imagery for the first time, to the best of our knowledge. Synth-SONAR achieves state-of-the-art results in producing high-quality synthetic sonar datasets, significantly enhancing their diversity and realism.
S3Simulator: A benchmarking Side Scan Sonar Simulator dataset for Underwater Image Analysis
Aug 23, 2024



Acoustic sonar imaging systems are widely used for underwater surveillance in both civilian and military sectors. However, acquiring high-quality sonar datasets for training Artificial Intelligence (AI) models confronts challenges such as limited data availability, financial constraints, and data confidentiality. To overcome these challenges, we propose a novel benchmark dataset of Simulated Side-Scan Sonar images, which we term as 'S3Simulator dataset'. Our dataset creation utilizes advanced simulation techniques to accurately replicate underwater conditions and produce diverse synthetic sonar imaging. In particular, the cutting-edge AI segmentation tool i.e. Segment Anything Model (SAM) is leveraged for optimally isolating and segmenting the object images, such as ships and planes, from real scenes. Further, advanced Computer-Aided Design tools i.e. SelfCAD and simulation software such as Gazebo are employed to create the 3D model and to optimally visualize within realistic environments, respectively. Further, a range of computational imaging techniques are employed to improve the quality of the data, enabling the AI models for the analysis of the sonar images. Extensive analyses are carried out on S3simulator as well as real sonar datasets to validate the performance of AI models for underwater object classification. Our experimental results highlight that the S3Simulator dataset will be a promising benchmark dataset for research on underwater image analysis. https://github.com/bashakamal/S3Simulator.
VALE: A Multimodal Visual and Language Explanation Framework for Image Classifiers using eXplainable AI and Language Models
Aug 23, 2024Deep Neural Networks (DNNs) have revolutionized various fields by enabling task automation and reducing human error. However, their internal workings and decision-making processes remain obscure due to their black box nature. Consequently, the lack of interpretability limits the application of these models in high-risk scenarios. To address this issue, the emerging field of eXplainable Artificial Intelligence (XAI) aims to explain and interpret the inner workings of DNNs. Despite advancements, XAI faces challenges such as the semantic gap between machine and human understanding, the trade-off between interpretability and performance, and the need for context-specific explanations. To overcome these limitations, we propose a novel multimodal framework named VALE Visual and Language Explanation. VALE integrates explainable AI techniques with advanced language models to provide comprehensive explanations. This framework utilizes visual explanations from XAI tools, an advanced zero-shot image segmentation model, and a visual language model to generate corresponding textual explanations. By combining visual and textual explanations, VALE bridges the semantic gap between machine outputs and human interpretation, delivering results that are more comprehensible to users. In this paper, we conduct a pilot study of the VALE framework for image classification tasks. Specifically, Shapley Additive Explanations (SHAP) are used to identify the most influential regions in classified images. The object of interest is then extracted using the Segment Anything Model (SAM), and explanations are generated using state-of-the-art pre-trained Vision-Language Models (VLMs). Extensive experimental studies are performed on two datasets: the ImageNet dataset and a custom underwater SONAR image dataset, demonstrating VALEs real-world applicability in underwater image classification.
Underwater SONAR Image Classification and Analysis using LIME-based Explainable Artificial Intelligence
Aug 23, 2024Deep learning techniques have revolutionized image classification by mimicking human cognition and automating complex decision-making processes. However, the deployment of AI systems in the wild, especially in high-security domains such as defence, is curbed by the lack of explainability of the model. To this end, eXplainable AI (XAI) is an emerging area of research that is intended to explore the unexplained hidden black box nature of deep neural networks. This paper explores the application of the eXplainable Artificial Intelligence (XAI) tool to interpret the underwater image classification results, one of the first works in the domain to the best of our knowledge. Our study delves into the realm of SONAR image classification using a custom dataset derived from diverse sources, including the Seabed Objects KLSG dataset, the camera SONAR dataset, the mine SONAR images dataset, and the SCTD dataset. An extensive analysis of transfer learning techniques for image classification using benchmark Convolutional Neural Network (CNN) architectures such as VGG16, ResNet50, InceptionV3, DenseNet121, etc. is carried out. On top of this classification model, a post-hoc XAI technique, viz. Local Interpretable Model-Agnostic Explanations (LIME) are incorporated to provide transparent justifications for the model's decisions by perturbing input data locally to see how predictions change. Furthermore, Submodular Picks LIME (SP-LIME) a version of LIME particular to images, that perturbs the image based on the submodular picks is also extensively studied. To this end, two submodular optimization algorithms i.e. Quickshift and Simple Linear Iterative Clustering (SLIC) are leveraged towards submodular picks. The extensive analysis of XAI techniques highlights interpretability of the results in a more human-compliant way, thus boosting our confidence and reliability.
SegXAL: Explainable Active Learning for Semantic Segmentation in Driving Scene Scenarios
Aug 08, 2024Most of the sophisticated AI models utilize huge amounts of annotated data and heavy training to achieve high-end performance. However, there are certain challenges that hinder the deployment of AI models "in-the-wild" scenarios, i.e., inefficient use of unlabeled data, lack of incorporation of human expertise, and lack of interpretation of the results. To mitigate these challenges, we propose a novel Explainable Active Learning (XAL) model, XAL-based semantic segmentation model "SegXAL", that can (i) effectively utilize the unlabeled data, (ii) facilitate the "Human-in-the-loop" paradigm, and (iii) augment the model decisions in an interpretable way. In particular, we investigate the application of the SegXAL model for semantic segmentation in driving scene scenarios. The SegXAL model proposes the image regions that require labeling assistance from Oracle by dint of explainable AI (XAI) and uncertainty measures in a weakly-supervised manner. Specifically, we propose a novel Proximity-aware Explainable-AI (PAE) module and Entropy-based Uncertainty (EBU) module to get an Explainable Error Mask, which enables the machine teachers/human experts to provide intuitive reasoning behind the results and to solicit feedback to the AI system via an active learning strategy. Such a mechanism bridges the semantic gap between man and machine through collaborative intelligence, where humans and AI actively enhance each other's complementary strengths. A novel high-confidence sample selection technique based on the DICE similarity coefficient is also presented within the SegXAL framework. Extensive quantitative and qualitative analyses are carried out in the benchmarking Cityscape dataset. Results show the outperformance of our proposed SegXAL against other state-of-the-art models.
Multimodal Adaptive Fusion of Face and Gait Features using Keyless attention based Deep Neural Networks for Human Identification
Mar 24, 2023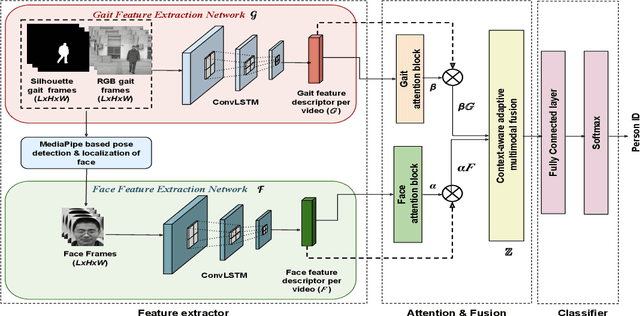
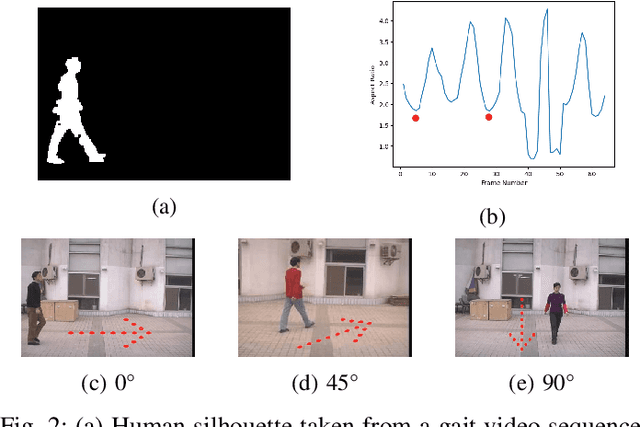
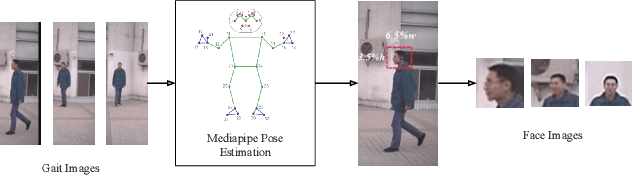

Biometrics plays a significant role in vision-based surveillance applications. Soft biometrics such as gait is widely used with face in surveillance tasks like person recognition and re-identification. Nevertheless, in practical scenarios, classical fusion techniques respond poorly to changes in individual users and in the external environment. To this end, we propose a novel adaptive multi-biometric fusion strategy for the dynamic incorporation of gait and face biometric cues by leveraging keyless attention deep neural networks. Various external factors such as viewpoint and distance to the camera, are investigated in this study. Extensive experiments have shown superior performanceof the proposed model compared with the state-of-the-art model.