 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-linear Motion Estimation for Video Frame Interpolation using Space-time Convolutions
Jan 27, 2022Video frame interpolation aims to synthesize one or multiple frames between two consecutive frames in a video. It has a wide range of applications including slow-motion video generation, frame-rate up-scaling and developing video codecs. Some older works tackled this problem by assuming per-pixel linear motion between video frames. However, objects often follow a non-linear motion pattern in the real domain and some recent methods attempt to model per-pixel motion by non-linear models (e.g., quadratic). A quadratic model can also be inaccurate, especially in the case of motion discontinuities over time (i.e. sudden jerks) and occlusions, where some of the flow information may be invalid or inaccurate. In our paper, we propose to approximate the per-pixel motion using a space-time convolution network that is able to adaptively select the motion model to be used. Specifically, we are able to softly switch between a linear and a quadratic model. Towards this end, we use an end-to-end 3D CNN encoder-decoder architecture over bidirectional optical flows and occlusion maps to estimate the non-linear motion model of each pixel. Further, a motion refinement module is employed to refine the non-linear motion and the interpolated frames are estimated by a simple warping of the neighboring frames with the estimated per-pixel motion. Through a set of comprehensive experiments, we validate the effectiveness of our model and show that our method outperforms state-of-the-art algorithms on four datasets (Vimeo, DAVIS, HD and GoPro).
Co-segmentation Inspired Attention Module for Video-based Computer Vision Tasks
Nov 25, 2021
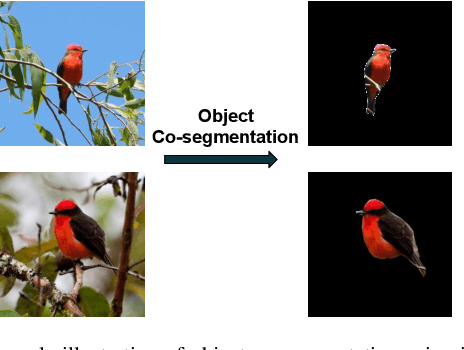

Video-based computer vision tasks can benefit from the estimation of the salient regions and interactions between those regions. Traditionally, this has been done by identifying the object regions in the images by utilizing pre-trained models to perform object detection, object segmentation, and/or object pose estimation. Though using pre-trained models seems to be a viable approach, it is infeasible in practice due to the need for exhaustive annotation of object categories, domain gap between datasets, and bias present in pre-trained models. To overcome these downsides, we propose to utilize the common rationale that a sequence of video frames capture a set of common objects and interactions between them, thus a notion of co-segmentation between the video frame features may equip the model with the ability to automatically focus on salient regions and improve underlying task's performance in an end-to-end manner. In this regard, we propose a generic module called "Co-Segmentation Activation Module" (COSAM) that can be plugged into any CNN to promote the notion of co-segmentation based attention among a sequence of video frame features. We show the application of COSAM in three video-based tasks namely: 1) Video-based person re-ID, 2) Video captioning, & 3) Video action classification, and demonstrate that COSAM is able to capture salient regions in the video frames, thus leading to notable performance improvements along with interpretable attention maps.
MARNet: Multi-Abstraction Refinement Network for 3D Point Cloud Analysis
Nov 02, 2020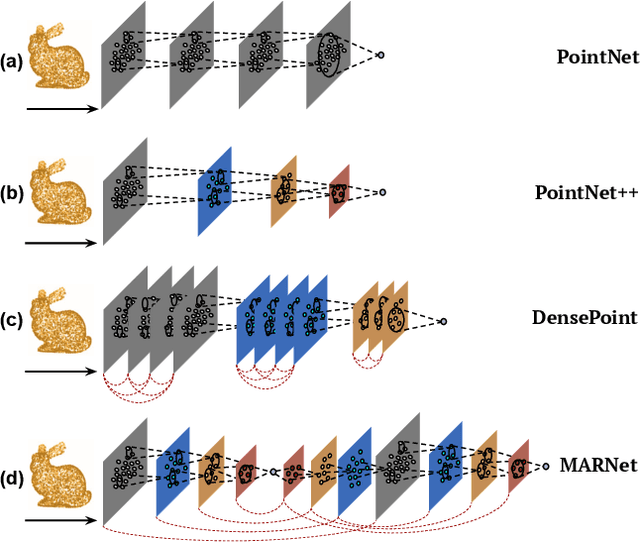
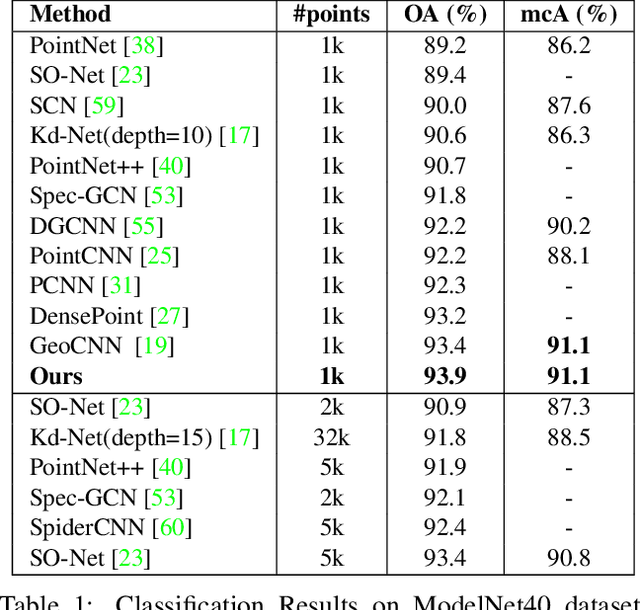
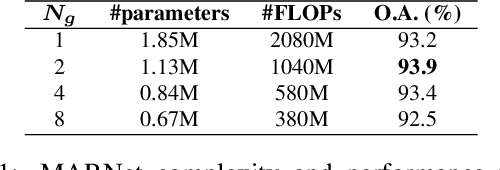
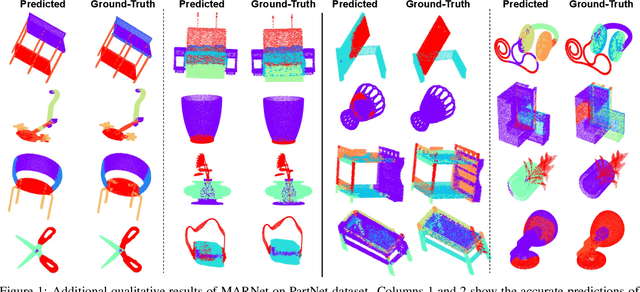
Representation learning from 3D point clouds is challenging due to their inherent nature of permutation invariance and irregular distribution in space. Existing deep learning methods follow a hierarchical feature extraction paradigm in which high-level abstract features are derived from low-level features. However, they fail to exploit different granularity of information due to the limited interaction between these features. To this end, we propose Multi-Abstraction Refinement Network (MARNet) that ensures an effective exchange of information between multi-level features to gain local and global contextual cues while effectively preserving them till the final layer. We empirically show the effectiveness of MARNet in terms of state-of-the-art results on two challenging tasks: Shape classification and Coarse-to-fine grained semantic segmentation. MARNet significantly improves the classification performance by 2% over the baseline and outperforms the state-of-the-art methods on semantic segmentation task.
Bi-modal First Impressions Recognition using Temporally Ordered Deep Audio and Stochastic Visual Features
Oct 31, 2016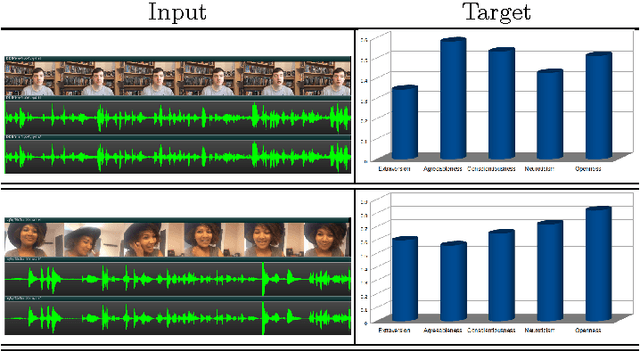
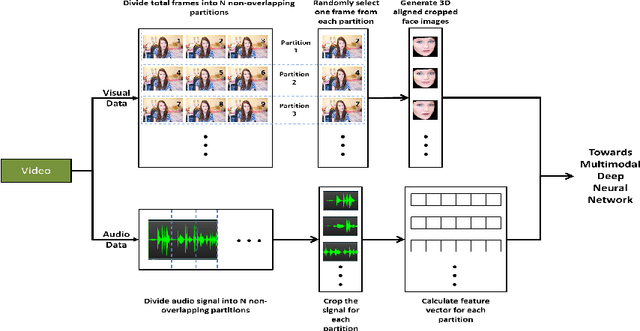
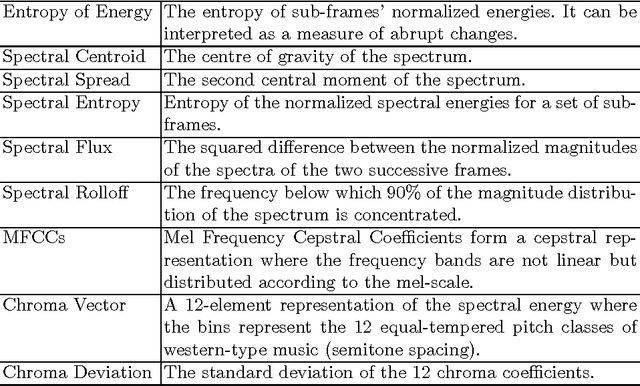
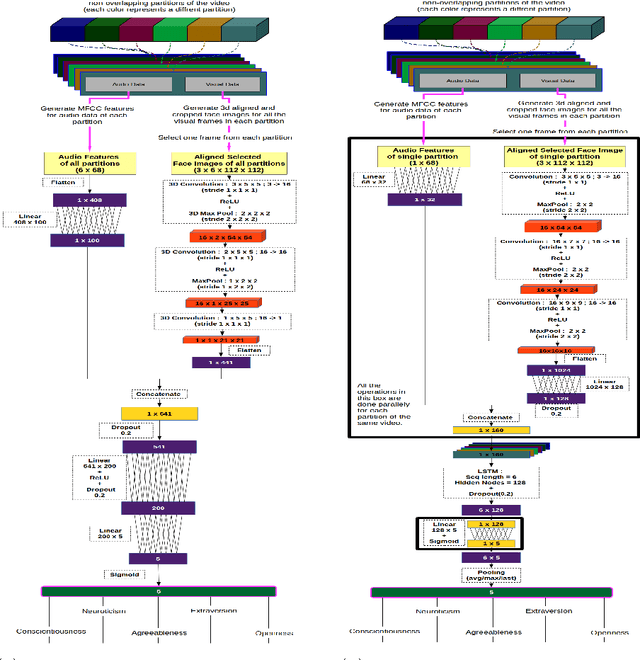
We propose a novel approach for First Impressions Recognition in terms of the Big Five personality-traits from short videos. The Big Five personality traits is a model to describe human personality using five broad categories: Extraversion, Agreeableness, Conscientiousness, Neuroticism and Openness. We train two bi-modal end-to-end deep neural network architectures using temporally ordered audio and novel stochastic visual features from few frames, without over-fitting. We empirically show that the trained models perform exceptionally well, even after training from a small sub-portions of inputs. Our method is evaluated in ChaLearn LAP 2016 Apparent Personality Analysis (APA) competition using ChaLearn LAP APA2016 dataset and achieved excellent performance.