 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-segmentation Inspired Attention Module for Video-based Computer Vision Tasks
Nov 25, 2021
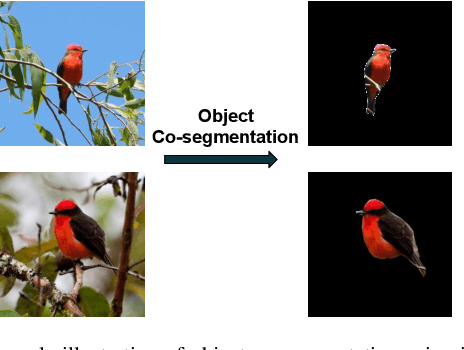

Video-based computer vision tasks can benefit from the estimation of the salient regions and interactions between those regions. Traditionally, this has been done by identifying the object regions in the images by utilizing pre-trained models to perform object detection, object segmentation, and/or object pose estimation. Though using pre-trained models seems to be a viable approach, it is infeasible in practice due to the need for exhaustive annotation of object categories, domain gap between datasets, and bias present in pre-trained models. To overcome these downsides, we propose to utilize the common rationale that a sequence of video frames capture a set of common objects and interactions between them, thus a notion of co-segmentation between the video frame features may equip the model with the ability to automatically focus on salient regions and improve underlying task's performance in an end-to-end manner. In this regard, we propose a generic module called "Co-Segmentation Activation Module" (COSAM) that can be plugged into any CNN to promote the notion of co-segmentation based attention among a sequence of video frame features. We show the application of COSAM in three video-based tasks namely: 1) Video-based person re-ID, 2) Video captioning, & 3) Video action classification, and demonstrate that COSAM is able to capture salient regions in the video frames, thus leading to notable performance improvements along with interpretable attention maps.