 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB-X Classification for Electronics Sorting
Sep 08, 2022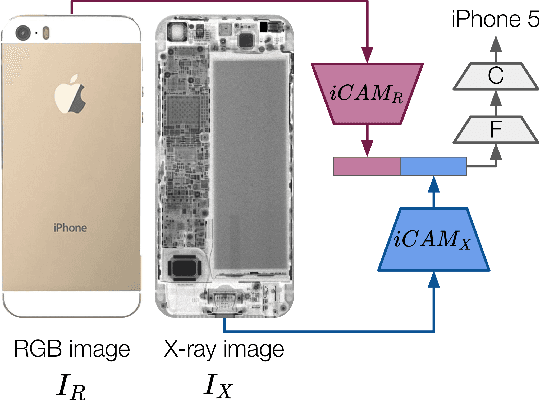


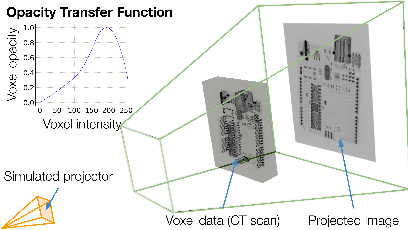
Effectively disassembling and recovering materials from waste electrical and electronic equipment (WEEE) is a critical step in moving global supply chains from carbon-intensive, mined materials to recycled and renewable ones. Conventional recycling processes rely on shredding and sorting waste streams, but for WEEE, which is comprised of numerous dissimilar materials, we explore targeted disassembly of numerous objects for improved material recovery. Many WEEE objects share many key features and therefore can look quite similar, but their material composition and internal component layout can vary, and thus it is critical to have an accurate classifier for subsequent disassembly steps for accurate material separation and recovery. This work introduces RGB-X, a multi-modal image classification approach, that utilizes key features from external RGB images with those generated from X-ray images to accurately classify electronic objects. More specifically, this work develops Iterative Class Activation Mapping (iCAM), a novel network architecture that explicitly focuses on the finer-details in the multi-modal feature maps that are needed for accurate electronic object classification. In order to train a classifier, electronic objects lack large and well annotated X-ray datasets due to expense and need of expert guidance. To overcome this issue, we present a novel way of creating a synthetic dataset using domain randomization applied to the X-ray domain. The combined RGB-X approach gives us an accuracy of 98.6% on 10 generations of modern smartphones, which is greater than their individual accuracies of 89.1% (RGB) and 97.9% (X-ray) independently. We provide experimental results3 to corroborate our results.
Analysing Long Short Term Memory Models for Cricket Match Outcome Prediction
Nov 04, 2020
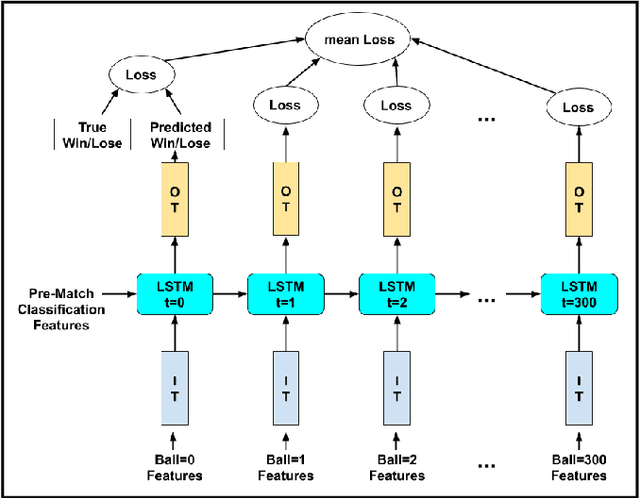
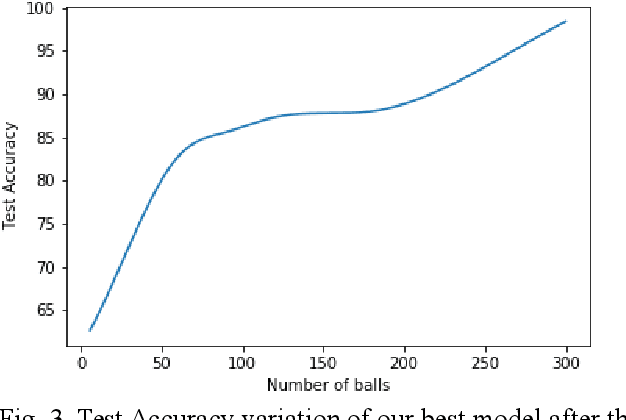
As the technology advances, an ample amount of data is collected in sports with the help of advanced sensors. Sports Analytics is the study of this data to provide a constructive advantage to the team and its players. The game of international cricket is popular all across the globe. Recently, various machine learning techniques have been used to analyse the cricket match data and predict the match outcome as win or lose. Generally these models make use of the overall match level statistics such as teams, venue, average run rate, win margin, etc to predict the match results before the beginning of the match. However, very few works provide insights based on the ball-by-ball level statistics. Here we propose a novel Recurrent Neural Network model which can predict the win probability of a match at regular intervals given the ball-by-ball statistics. The Long Short Term Memory (LSTM) Model takes as input the ball wise features as well as the match level details available from the training dataset. It gives a prediction of winning the match at any time stamp during the match. This level of insight will help the team to predict the probability of them winning the match after every ball and help them determine the critical in-game changes they should make in their game strategies.
MARNet: Multi-Abstraction Refinement Network for 3D Point Cloud Analysis
Nov 02, 2020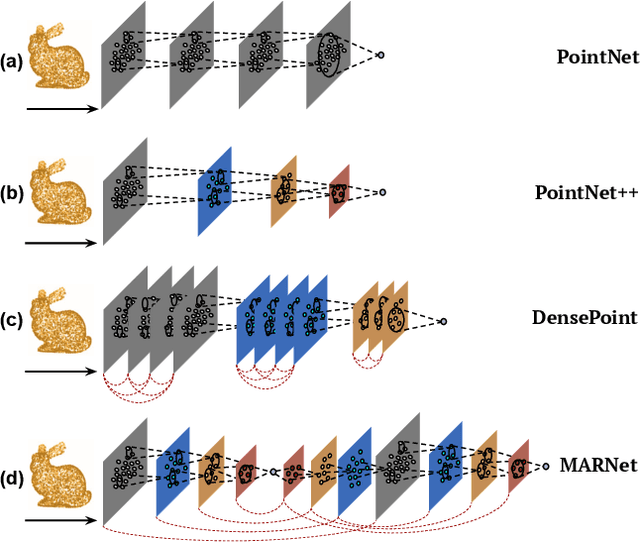
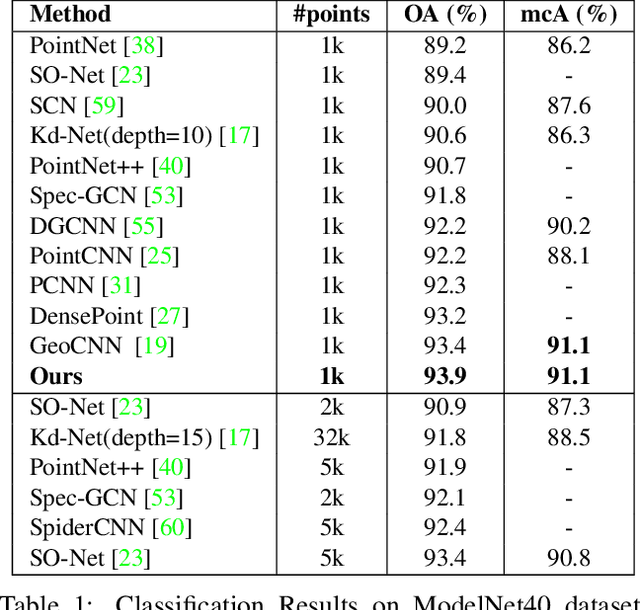
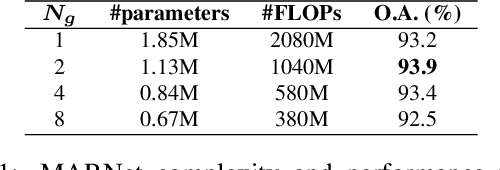
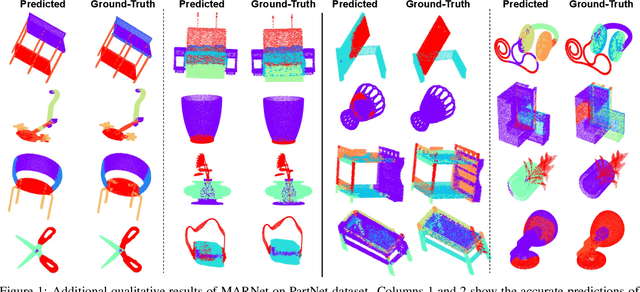
Representation learning from 3D point clouds is challenging due to their inherent nature of permutation invariance and irregular distribution in space. Existing deep learning methods follow a hierarchical feature extraction paradigm in which high-level abstract features are derived from low-level features. However, they fail to exploit different granularity of information due to the limited interaction between these features. To this end, we propose Multi-Abstraction Refinement Network (MARNet) that ensures an effective exchange of information between multi-level features to gain local and global contextual cues while effectively preserving them till the final layer. We empirically show the effectiveness of MARNet in terms of state-of-the-art results on two challenging tasks: Shape classification and Coarse-to-fine grained semantic segmentation. MARNet significantly improves the classification performance by 2% over the baseline and outperforms the state-of-the-art methods on semantic segmentation task.
Correspondence Matrices are Underrated
Oct 30, 2020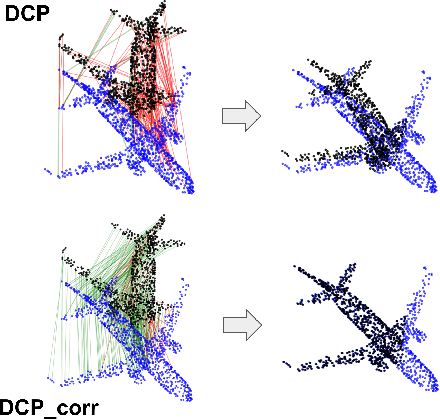



Point-cloud registration (PCR) is an important task in various applications such as robotic manipulation, augmented and virtual reality, SLAM, etc. PCR is an optimization problem involving minimization over two different types of interdependent variables: transformation parameters and point-to-point correspondences. Recent developments in deep-learning have produced computationally fast approaches for PCR. The loss functions that are optimized in these networks are based on the error in the transformation parameters. We hypothesize that these methods would perform significantly better if they calculated their loss function using correspondence error instead of only using error in transformation parameters. We define correspondence error as a metric based on incorrectly matched point pairs. We provide a fundamental explanation for why this is the case and test our hypothesis by modifying existing methods to use correspondence-based loss instead of transformation-based loss. These experiments show that the modified networks converge faster and register more accurately even at larger misalignment when compared to the original networks.