 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrespondence Matrices are Underrated
Oct 30, 2020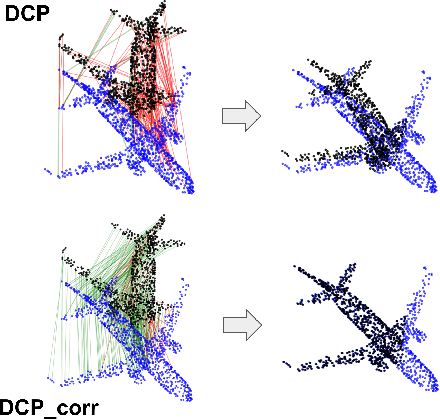



Point-cloud registration (PCR) is an important task in various applications such as robotic manipulation, augmented and virtual reality, SLAM, etc. PCR is an optimization problem involving minimization over two different types of interdependent variables: transformation parameters and point-to-point correspondences. Recent developments in deep-learning have produced computationally fast approaches for PCR. The loss functions that are optimized in these networks are based on the error in the transformation parameters. We hypothesize that these methods would perform significantly better if they calculated their loss function using correspondence error instead of only using error in transformation parameters. We define correspondence error as a metric based on incorrectly matched point pairs. We provide a fundamental explanation for why this is the case and test our hypothesis by modifying existing methods to use correspondence-based loss instead of transformation-based loss. These experiments show that the modified networks converge faster and register more accurately even at larger misalignment when compared to the original networks.
MaskNet: A Fully-Convolutional Network to Estimate Inlier Points
Oct 19, 2020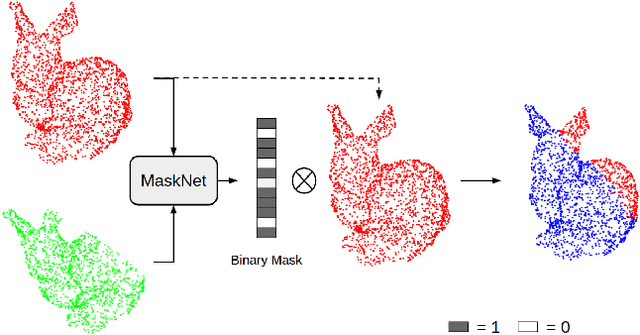
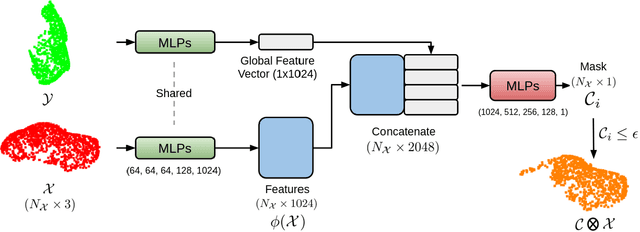
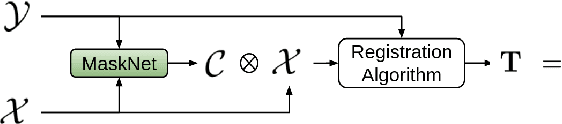

Point clouds have grown in importance in the way computers perceive the world. From LIDAR sensors in autonomous cars and drones to the time of flight and stereo vision systems in our phones, point clouds are everywhere. Despite their ubiquity, point clouds in the real world are often missing points because of sensor limitations or occlusions, or contain extraneous points from sensor noise or artifacts. These problems challenge algorithms that require computing correspondences between a pair of point clouds. Therefore, this paper presents a fully-convolutional neural network that identifies which points in one point cloud are most similar (inliers) to the points in another. We show improvements in learning-based and classical point cloud registration approaches when retrofitted with our network. We demonstrate these improvements on synthetic and real-world datasets. Finally, our network produces impressive results on test datasets that were unseen during training, thus exhibiting generalizability. Code and videos are available at https://github.com/vinits5/masknet
One Framework to Register Them All: PointNet Encoding for Point Cloud Alignment
Dec 12, 2019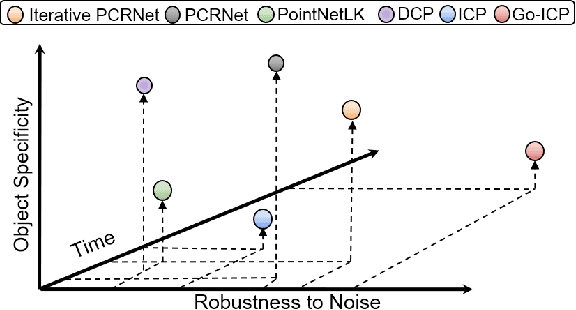
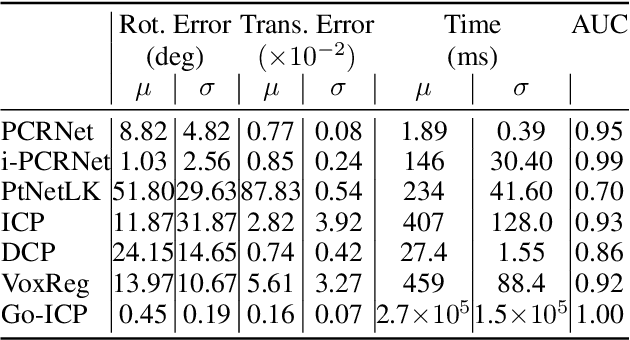
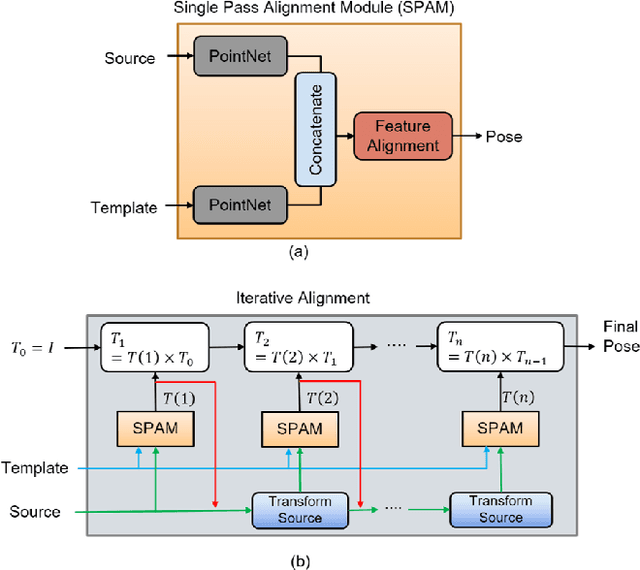
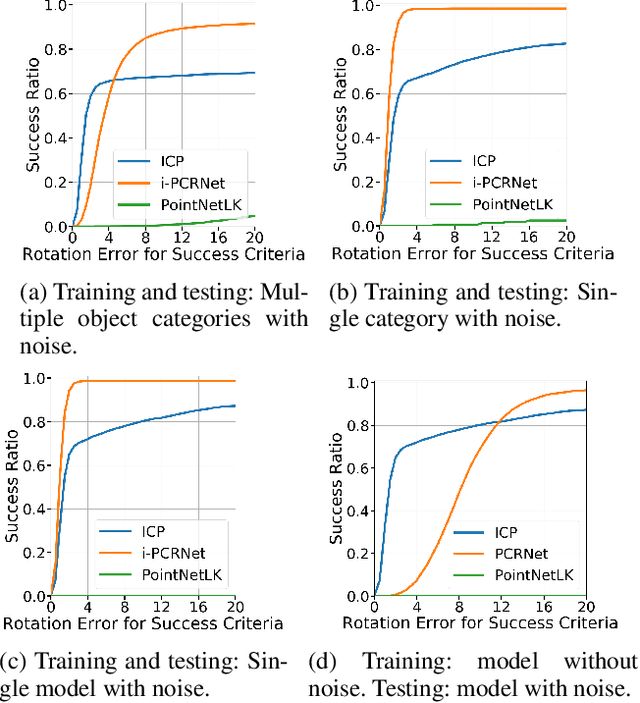
PointNet has recently emerged as a popular representation for unstructured point cloud data, allowing application of deep learning to tasks such as object detection, segmentation and shape completion. However, recent works in literature have shown the sensitivity of the PointNet representation to pose misalignment. This paper presents a novel framework that uses PointNet encoding to align point clouds and perform registration for applications such as 3D reconstruction, tracking and pose estimation. We develop a framework that compares PointNet features of template and source point clouds to find the transformation that aligns them accurately. In doing so, we avoid computationally expensive correspondence finding steps, that are central to popular registration methods such as ICP and its variants. Depending on the prior information about the shape of the object formed by the point clouds, our framework can produce approaches that are shape specific or general to unseen shapes. Our framework produces approaches that are robust to noise and initial misalignment in data and work robustly with sparse as well as partial point clouds. We perform extensive simulation and real-world experiments to validate the efficacy of our approach and compare the performance with state-of-art approaches. Code is available at https://github.com/vinits5/pointnet-registrationframework.
Globally optimal registration of noisy point clouds
Aug 22, 2019
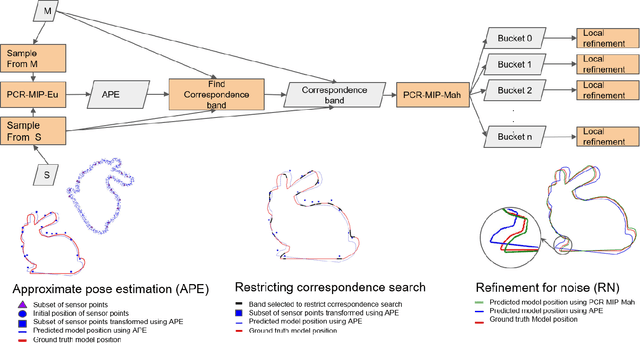
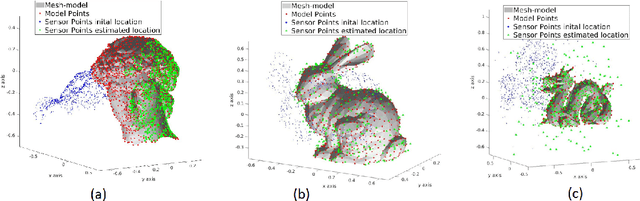

Registration of 3D point clouds is a fundamental task in several applications of robotics and computer vision. While registration methods such as iterative closest point and variants are very popular, they are only locally optimal. There has been some recent work on globally optimal registration, but they perform poorly in the presence of noise in the measurements. In this work we develop a mixed integer programming-based approach for globally optimal registration that explicitly considers uncertainty in its optimization, and hence produces more accurate estimates. Furthermore, from a practical implementation perspective we develop a multi-step optimization that combines fast local methods with our accurate global formulation. Through extensive simulation and real world experiments we demonstrate improved performance over state-of-the-art methods for various level of noise and outliers in the data as well as for partial geometric overlap.
PCRNet: Point Cloud Registration Network using PointNet Encoding
Aug 21, 2019

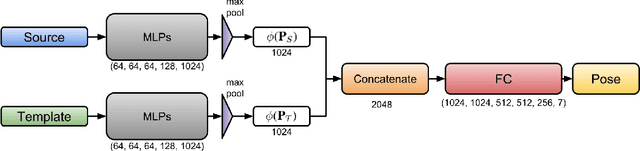
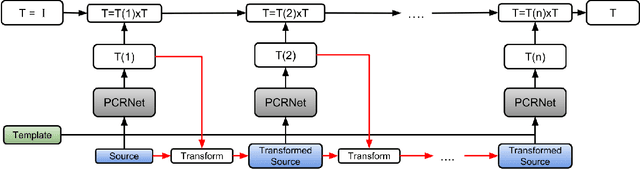
PointNet has recently emerged as a popular representation for unstructured point cloud data, allowing application of deep learning to tasks such as object detection, segmentation and shape completion. However, recent works in literature have shown the sensitivity of the PointNet representation to pose misalignment. This paper presents a novel framework that uses the PointNet representation to align point clouds and perform registration for applications such as tracking, 3D reconstruction and pose estimation. We develop a framework that compares PointNet features of template and source point clouds to find the transformation that aligns them accurately. Depending on the prior information about the shape of the object formed by the point clouds, our framework can produce approaches that are shape specific or general to unseen shapes. The shape specific approach uses a Siamese architecture with fully connected (FC) layers and is robust to noise and initial misalignment in data. We perform extensive simulation and real-world experiments to validate the efficacy of our approach and compare the performance with state-of-art approaches.
PointNetLK: Robust & Efficient Point Cloud Registration using PointNet
Apr 04, 2019
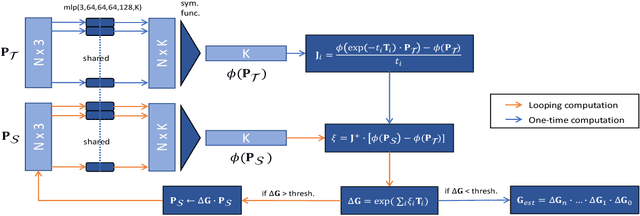
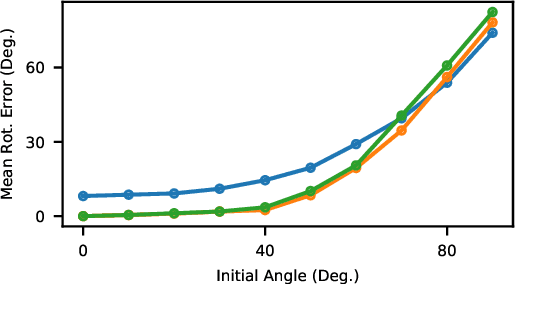
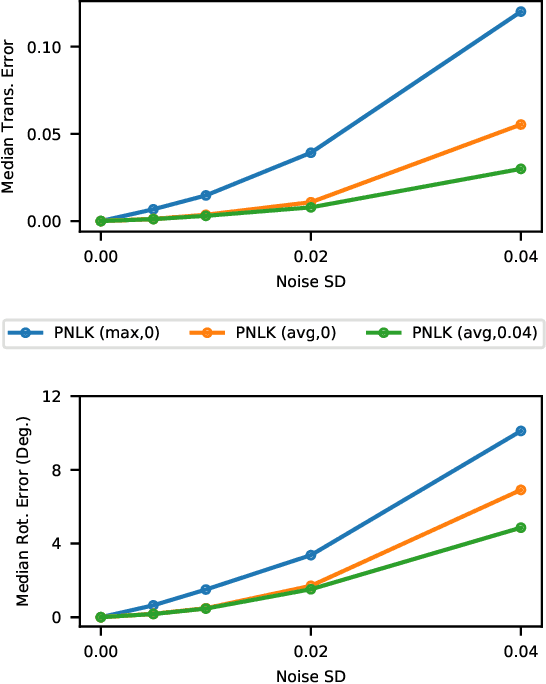
PointNet has revolutionized how we think about representing point clouds. For classification and segmentation tasks, the approach and its subsequent extensions are state-of-the-art. To date, the successful application of PointNet to point cloud registration has remained elusive. In this paper we argue that PointNet itself can be thought of as a learnable "imaging" function. As a consequence, classical vision algorithms for image alignment can be applied on the problem - namely the Lucas & Kanade (LK) algorithm. Our central innovations stem from: (i) how to modify the LK algorithm to accommodate the PointNet imaging function, and (ii) unrolling PointNet and the LK algorithm into a single trainable recurrent deep neural network. We describe the architecture, and compare its performance against state-of-the-art in common registration scenarios. The architecture offers some remarkable properties including: generalization across shape categories and computational efficiency - opening up new paths of exploration for the application of deep learning to point cloud registration. Code and videos are available at https://github.com/hmgoforth/PointNetLK.
MRS-VPR: a multi-resolution sampling based global visual place recognition method
Feb 26, 2019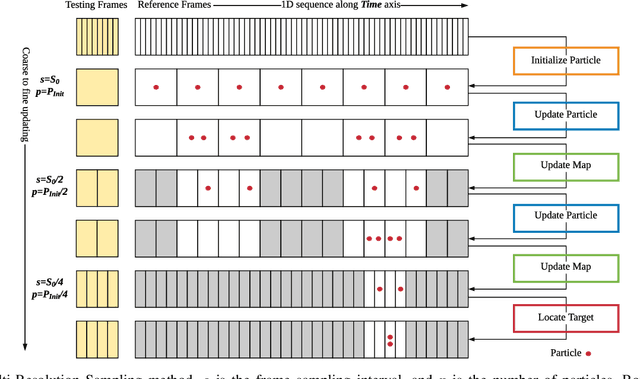
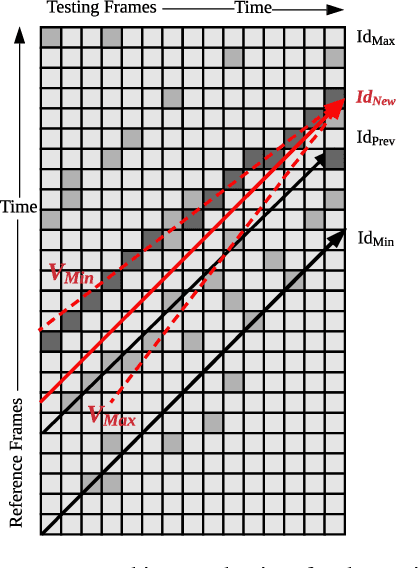
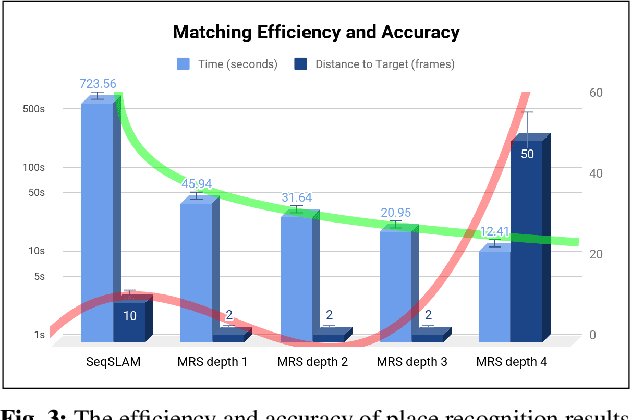
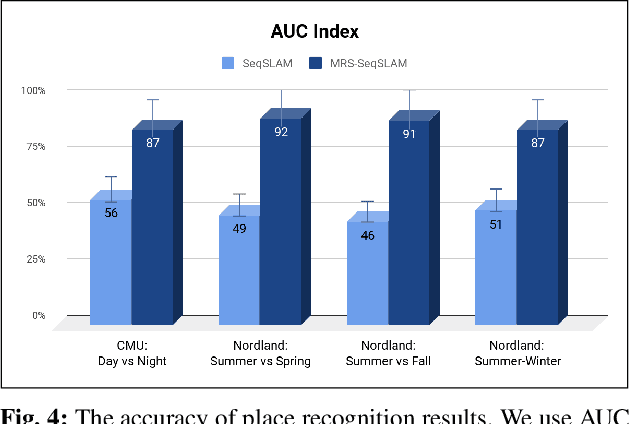
Place recognition and loop closure detection are challenging for long-term visual navigation tasks. SeqSLAM is considered to be one of the most successful approaches to achieving long-term localization under varying environmental conditions and changing viewpoints. It depends on a brute-force, time-consuming sequential matching method. We propose MRS-VPR, a multi-resolution, sampling-based place recognition method, which can significantly improve the matching efficiency and accuracy in sequential matching. The novelty of this method lies in the coarse-to-fine searching pipeline and a particle filter-based global sampling scheme, that can balance the matching efficiency and accuracy in the long-term navigation task. Moreover, our model works much better than SeqSLAM when the testing sequence has a much smaller scale than the reference sequence. Our experiments demonstrate that the proposed method is efficient in locating short temporary trajectories within long-term reference ones without losing accuracy compared to SeqSLAM.
A Multi-Domain Feature Learning Method for Visual Place Recognition
Feb 26, 2019
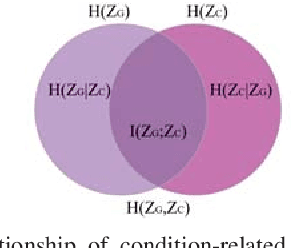


Visual Place Recognition (VPR) is an important component in both computer vision and robotics applications, thanks to its ability to determine whether a place has been visited and where specifically. A major challenge in VPR is to handle changes of environmental conditions including weather, season and illumination. Most VPR methods try to improve the place recognition performance by ignoring the environmental factors, leading to decreased accuracy decreases when environmental conditions change significantly, such as day versus night. To this end, we propose an end-to-end conditional visual place recognition method. Specifically, we introduce the multi-domain feature learning method (MDFL) to capture multiple attribute-descriptions for a given place, and then use a feature detaching module to separate the environmental condition-related features from those that are not. The only label required within this feature learning pipeline is the environmental condition. Evaluation of the proposed method is conducted on the multi-season \textit{NORDLAND} dataset, and the multi-weather \textit{GTAV} dataset. Experimental results show that our method improves the feature robustness against variant environmental conditions.
Trajectory-Optimized Sensing for Active Search of Tissue Abnormalities in Robotic Surgery
May 16, 2018
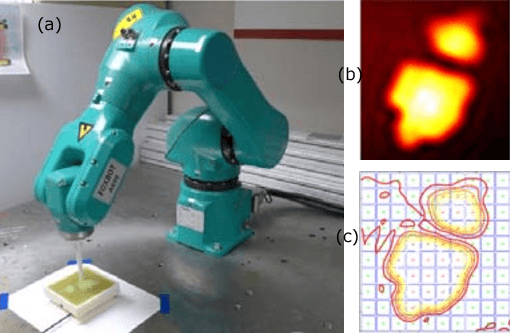
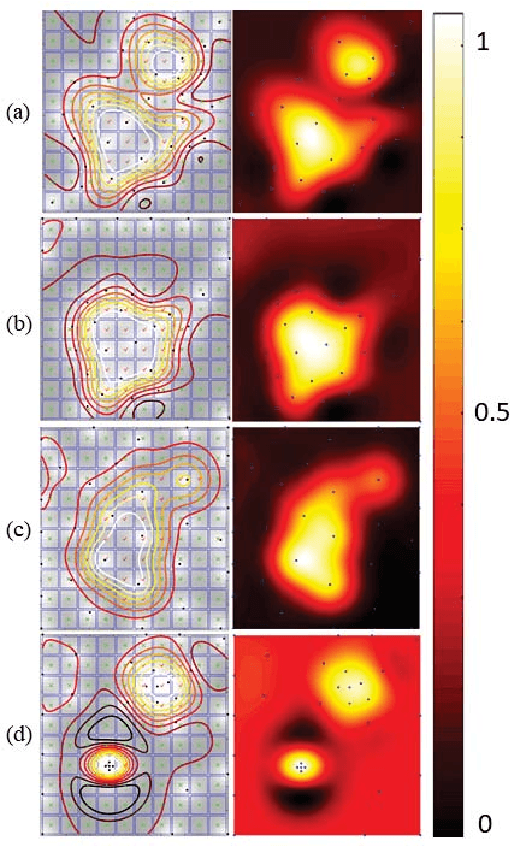
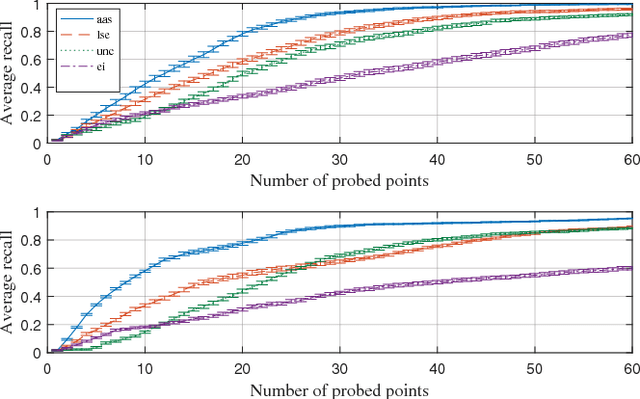
In this work, we develop an approach for guiding robots to automatically localize and find the shapes of tumors and other stiff inclusions present in the anatomy. Our approach uses Gaussian processes to model the stiffness distribution and active learning to direct the palpation path of the robot. The palpation paths are chosen such that they maximize an acquisition function provided by an active learning algorithm. Our approach provides the flexibility to avoid obstacles in the robot's path, incorporate uncertainties in robot position and sensor measurements, include prior information about location of stiff inclusions while respecting the robot-kinematics. To the best of our knowledge this is the first work in literature that considers all the above conditions while localizing tumors. The proposed framework is evaluated via simulation and experimentation on three different robot platforms: 6-DoF industrial arm, da Vinci Research Kit (dVRK), and the Insertable Robotic Effector Platform (IREP). Results show that our approach can accurately estimate the locations and boundaries of the stiff inclusions while reducing exploration time.
A surgical system for automatic registration, stiffness mapping and dynamic image overlay
Nov 23, 2017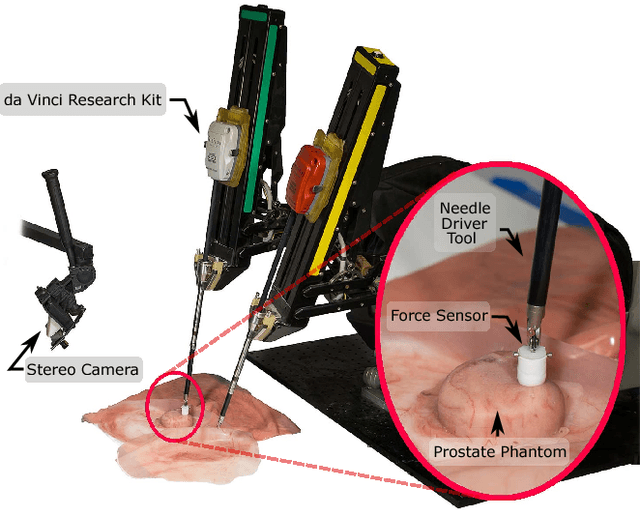
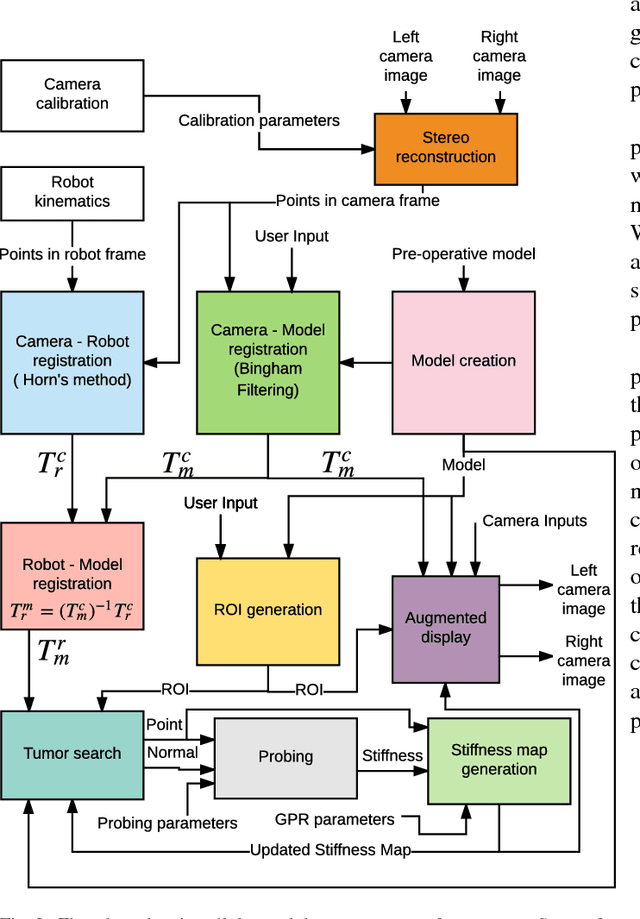
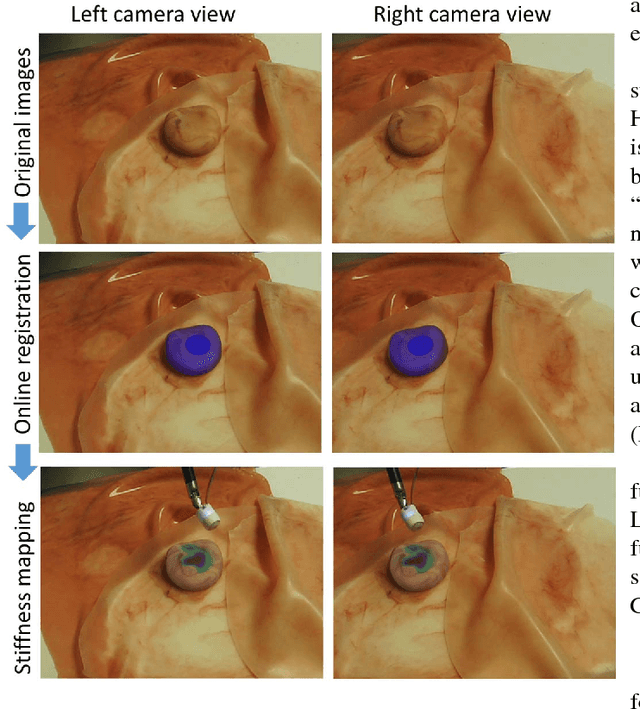
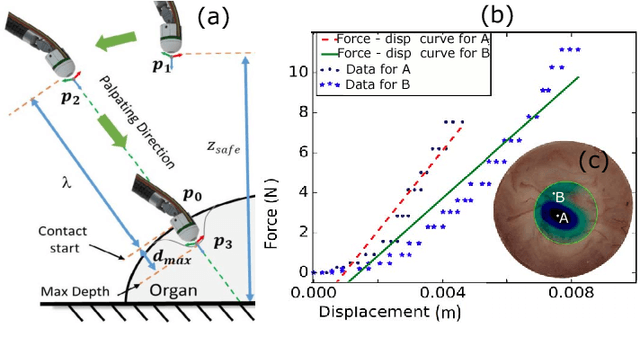
In this paper we develop a surgical system using the da Vinci research kit (dVRK) that is capable of autonomously searching for tumors and dynamically displaying the tumor location using augmented reality. Such a system has the potential to quickly reveal the location and shape of tumors and visually overlay that information to reduce the cognitive overload of the surgeon. We believe that our approach is one of the first to incorporate state-of-the-art methods in registration, force sensing and tumor localization into a unified surgical system. First, the preoperative model is registered to the intra-operative scene using a Bingham distribution-based filtering approach. An active level set estimation is then used to find the location and the shape of the tumors. We use a recently developed miniature force sensor to perform the palpation. The estimated stiffness map is then dynamically overlaid onto the registered preoperative model of the organ. We demonstrate the efficacy of our system by performing experiments on phantom prostate models with embedded stiff inclusions.