 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Framework to Register Them All: PointNet Encoding for Point Cloud Alignment
Dec 12, 2019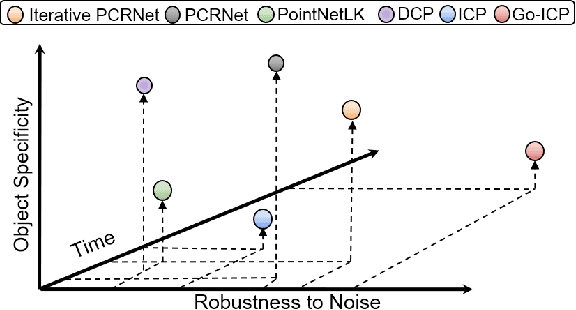
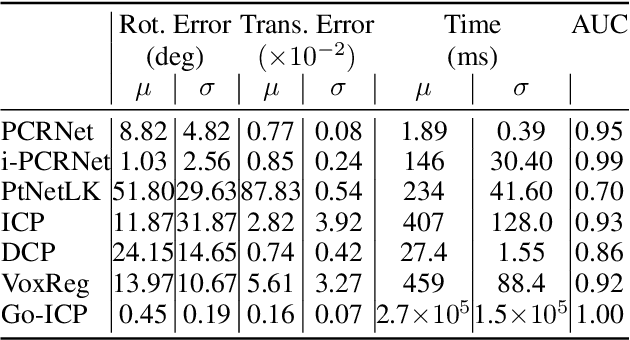
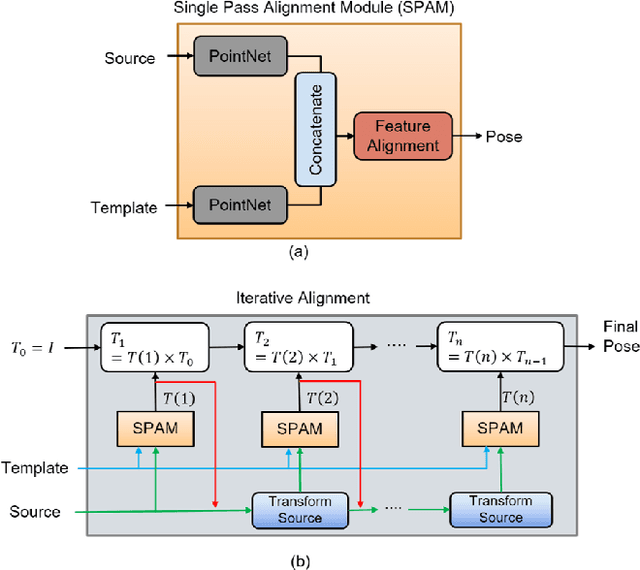
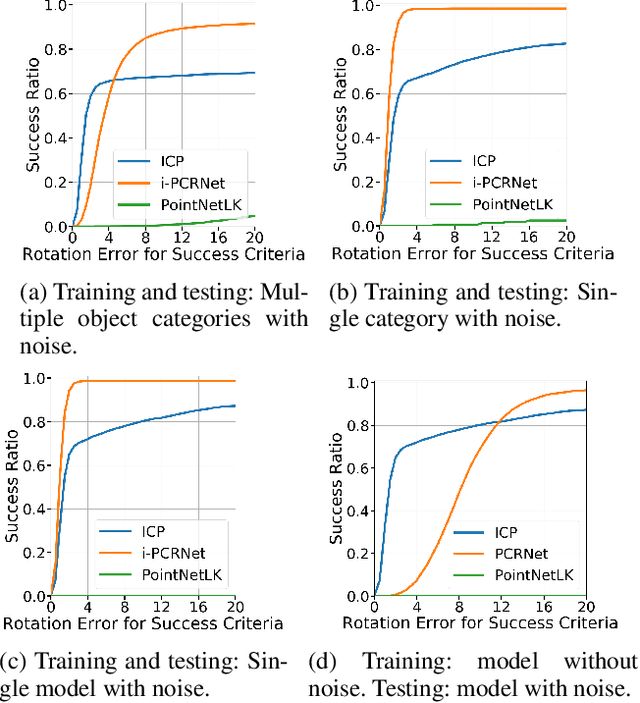
PointNet has recently emerged as a popular representation for unstructured point cloud data, allowing application of deep learning to tasks such as object detection, segmentation and shape completion. However, recent works in literature have shown the sensitivity of the PointNet representation to pose misalignment. This paper presents a novel framework that uses PointNet encoding to align point clouds and perform registration for applications such as 3D reconstruction, tracking and pose estimation. We develop a framework that compares PointNet features of template and source point clouds to find the transformation that aligns them accurately. In doing so, we avoid computationally expensive correspondence finding steps, that are central to popular registration methods such as ICP and its variants. Depending on the prior information about the shape of the object formed by the point clouds, our framework can produce approaches that are shape specific or general to unseen shapes. Our framework produces approaches that are robust to noise and initial misalignment in data and work robustly with sparse as well as partial point clouds. We perform extensive simulation and real-world experiments to validate the efficacy of our approach and compare the performance with state-of-art approaches. Code is available at https://github.com/vinits5/pointnet-registrationframework.
PCRNet: Point Cloud Registration Network using PointNet Encoding
Aug 21, 2019

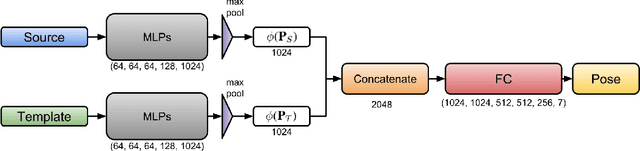
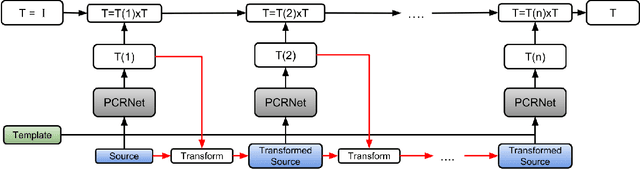
PointNet has recently emerged as a popular representation for unstructured point cloud data, allowing application of deep learning to tasks such as object detection, segmentation and shape completion. However, recent works in literature have shown the sensitivity of the PointNet representation to pose misalignment. This paper presents a novel framework that uses the PointNet representation to align point clouds and perform registration for applications such as tracking, 3D reconstruction and pose estimation. We develop a framework that compares PointNet features of template and source point clouds to find the transformation that aligns them accurately. Depending on the prior information about the shape of the object formed by the point clouds, our framework can produce approaches that are shape specific or general to unseen shapes. The shape specific approach uses a Siamese architecture with fully connected (FC) layers and is robust to noise and initial misalignment in data. We perform extensive simulation and real-world experiments to validate the efficacy of our approach and compare the performance with state-of-art approaches.
PointNetLK: Robust & Efficient Point Cloud Registration using PointNet
Apr 04, 2019
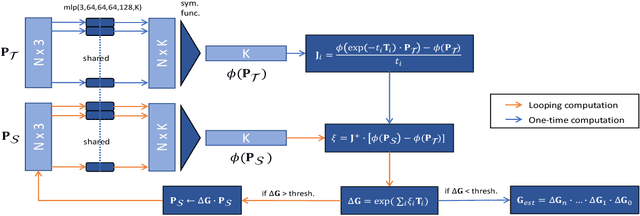
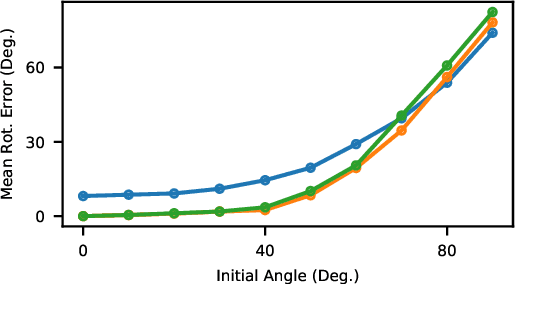
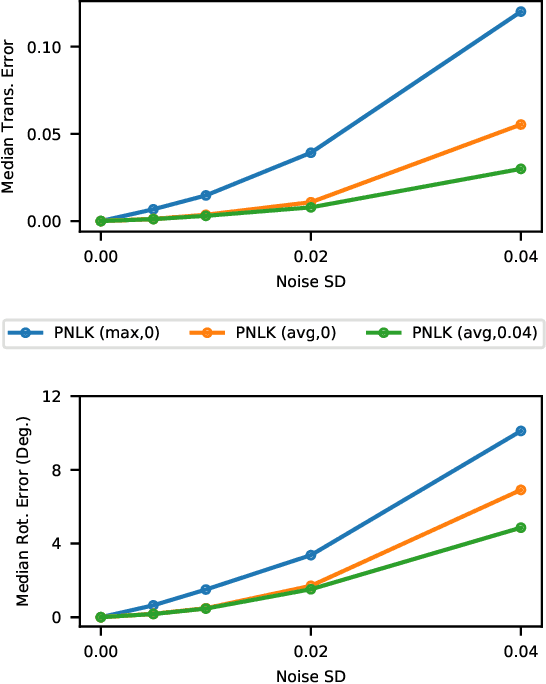
PointNet has revolutionized how we think about representing point clouds. For classification and segmentation tasks, the approach and its subsequent extensions are state-of-the-art. To date, the successful application of PointNet to point cloud registration has remained elusive. In this paper we argue that PointNet itself can be thought of as a learnable "imaging" function. As a consequence, classical vision algorithms for image alignment can be applied on the problem - namely the Lucas & Kanade (LK) algorithm. Our central innovations stem from: (i) how to modify the LK algorithm to accommodate the PointNet imaging function, and (ii) unrolling PointNet and the LK algorithm into a single trainable recurrent deep neural network. We describe the architecture, and compare its performance against state-of-the-art in common registration scenarios. The architecture offers some remarkable properties including: generalization across shape categories and computational efficiency - opening up new paths of exploration for the application of deep learning to point cloud registration. Code and videos are available at https://github.com/hmgoforth/PointNetLK.