 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Domain Generalization on Ultrasound-based Multi-Class Segmentation of Arteries, Veins, Ligaments, and Nerves Using Transfer Learning
Nov 13, 2020
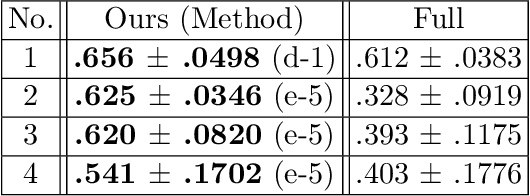
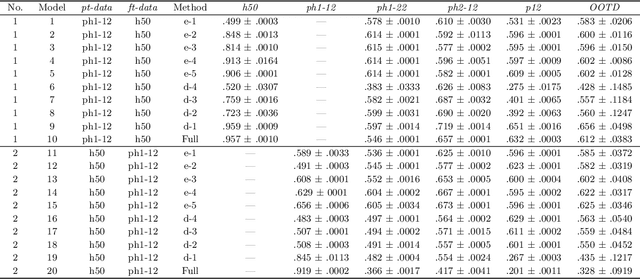
Identifying landmarks in the femoral area is crucial for ultrasound (US) -based robot-guided catheter insertion, and their presentation varies when imaged with different scanners. As such, the performance of past deep learning-based approaches is also narrowly limited to the training data distribution; this can be circumvented by fine-tuning all or part of the model, yet the effects of fine-tuning are seldom discussed. In this work, we study the US-based segmentation of multiple classes through transfer learning by fine-tuning different contiguous blocks within the model, and evaluating on a gamut of US data from different scanners and settings. We propose a simple method for predicting generalization on unseen datasets and observe statistically significant differences between the fine-tuning methods while working towards domain generalization.
Correspondence Matrices are Underrated
Oct 30, 2020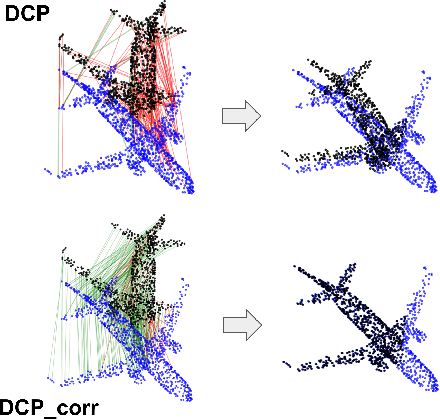



Point-cloud registration (PCR) is an important task in various applications such as robotic manipulation, augmented and virtual reality, SLAM, etc. PCR is an optimization problem involving minimization over two different types of interdependent variables: transformation parameters and point-to-point correspondences. Recent developments in deep-learning have produced computationally fast approaches for PCR. The loss functions that are optimized in these networks are based on the error in the transformation parameters. We hypothesize that these methods would perform significantly better if they calculated their loss function using correspondence error instead of only using error in transformation parameters. We define correspondence error as a metric based on incorrectly matched point pairs. We provide a fundamental explanation for why this is the case and test our hypothesis by modifying existing methods to use correspondence-based loss instead of transformation-based loss. These experiments show that the modified networks converge faster and register more accurately even at larger misalignment when compared to the original networks.
MaskNet: A Fully-Convolutional Network to Estimate Inlier Points
Oct 19, 2020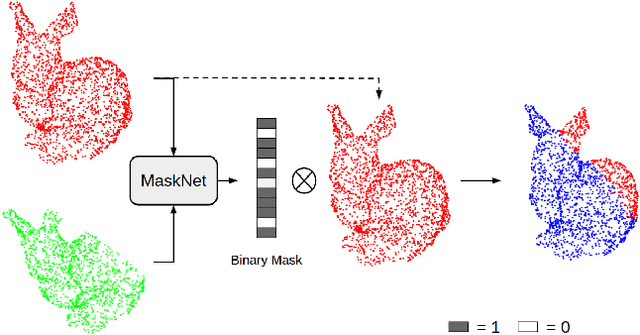
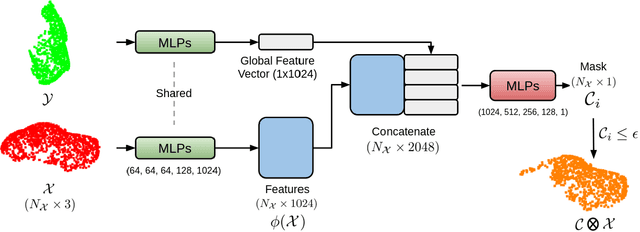
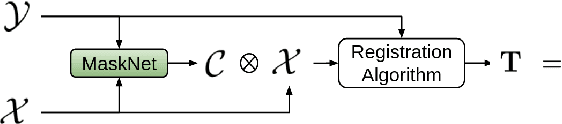

Point clouds have grown in importance in the way computers perceive the world. From LIDAR sensors in autonomous cars and drones to the time of flight and stereo vision systems in our phones, point clouds are everywhere. Despite their ubiquity, point clouds in the real world are often missing points because of sensor limitations or occlusions, or contain extraneous points from sensor noise or artifacts. These problems challenge algorithms that require computing correspondences between a pair of point clouds. Therefore, this paper presents a fully-convolutional neural network that identifies which points in one point cloud are most similar (inliers) to the points in another. We show improvements in learning-based and classical point cloud registration approaches when retrofitted with our network. We demonstrate these improvements on synthetic and real-world datasets. Finally, our network produces impressive results on test datasets that were unseen during training, thus exhibiting generalizability. Code and videos are available at https://github.com/vinits5/masknet
One Framework to Register Them All: PointNet Encoding for Point Cloud Alignment
Dec 12, 2019
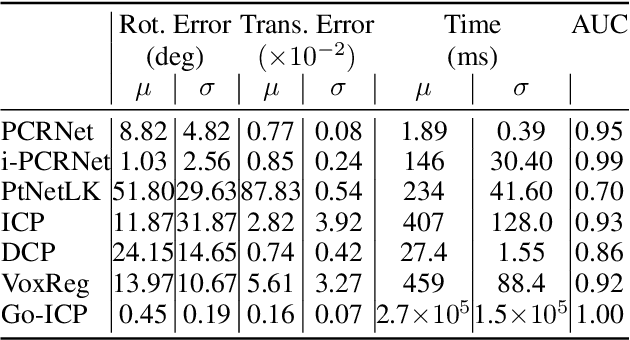
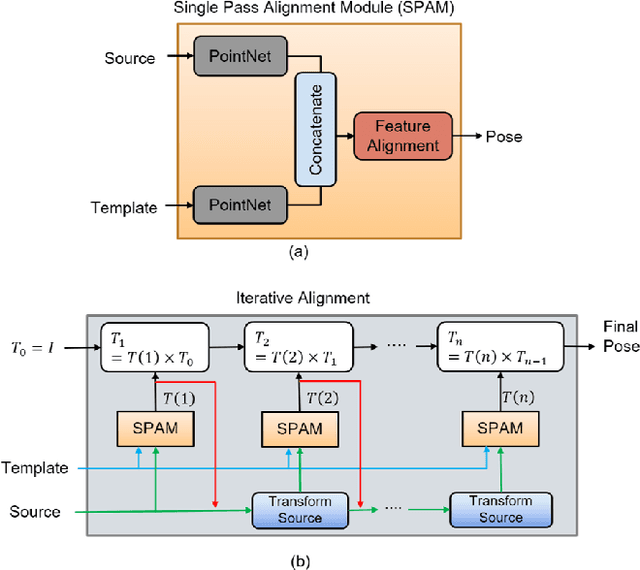
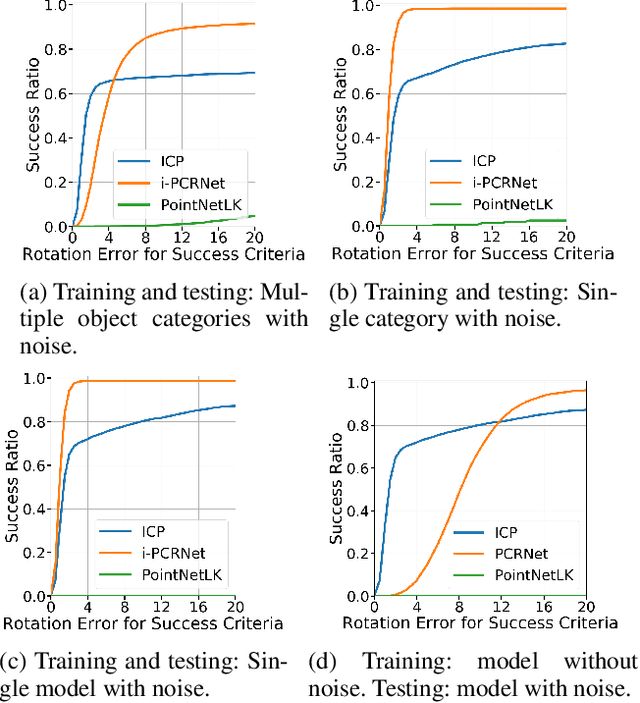
PointNet has recently emerged as a popular representation for unstructured point cloud data, allowing application of deep learning to tasks such as object detection, segmentation and shape completion. However, recent works in literature have shown the sensitivity of the PointNet representation to pose misalignment. This paper presents a novel framework that uses PointNet encoding to align point clouds and perform registration for applications such as 3D reconstruction, tracking and pose estimation. We develop a framework that compares PointNet features of template and source point clouds to find the transformation that aligns them accurately. In doing so, we avoid computationally expensive correspondence finding steps, that are central to popular registration methods such as ICP and its variants. Depending on the prior information about the shape of the object formed by the point clouds, our framework can produce approaches that are shape specific or general to unseen shapes. Our framework produces approaches that are robust to noise and initial misalignment in data and work robustly with sparse as well as partial point clouds. We perform extensive simulation and real-world experiments to validate the efficacy of our approach and compare the performance with state-of-art approaches. Code is available at https://github.com/vinits5/pointnet-registrationframework.
PCRNet: Point Cloud Registration Network using PointNet Encoding
Aug 21, 2019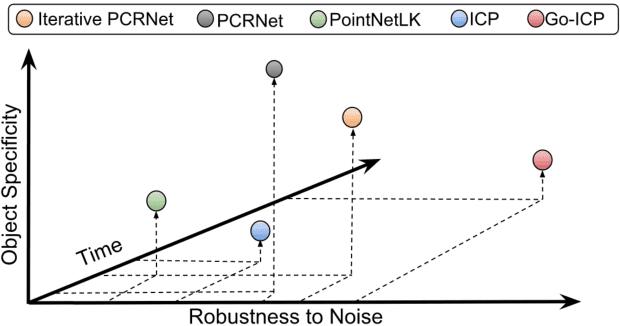

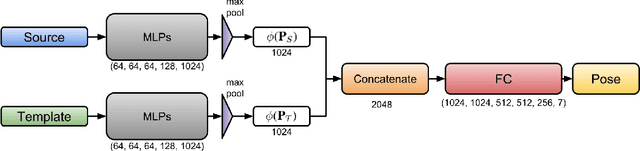
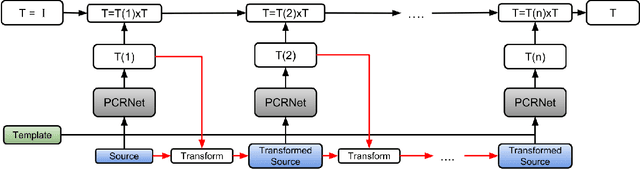
PointNet has recently emerged as a popular representation for unstructured point cloud data, allowing application of deep learning to tasks such as object detection, segmentation and shape completion. However, recent works in literature have shown the sensitivity of the PointNet representation to pose misalignment. This paper presents a novel framework that uses the PointNet representation to align point clouds and perform registration for applications such as tracking, 3D reconstruction and pose estimation. We develop a framework that compares PointNet features of template and source point clouds to find the transformation that aligns them accurately. Depending on the prior information about the shape of the object formed by the point clouds, our framework can produce approaches that are shape specific or general to unseen shapes. The shape specific approach uses a Siamese architecture with fully connected (FC) layers and is robust to noise and initial misalignment in data. We perform extensive simulation and real-world experiments to validate the efficacy of our approach and compare the performance with state-of-art approaches.