 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowRL: A Taxonomy and Modular Framework for Reinforcement Learning with Diffusion Policies
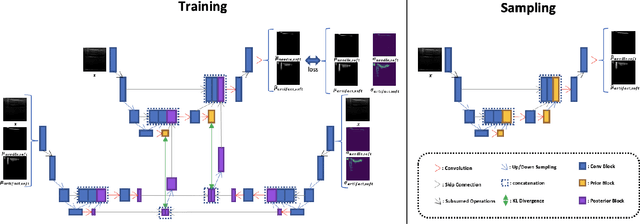
Mar 29, 2026Thanks to their remarkable flexibility, diffusion models and flow models have emerged as promising candidates for policy representation. However, efficient reinforcement learning (RL) upon these policies remains a challenge due to the lack of explicit log-probabilities for vanilla policy gradient estimators. While numerous attempts have been proposed to address this, the field lacks a unified perspective to reconcile these seemingly disparate methods, thus hampering ongoing development. In this paper, we bridge this gap by introducing a comprehensive taxonomy for RL algorithms with diffusion/flow policies. To support reproducibility and agile prototyping, we introduce a modular, JAX-based open-source codebase that leverages JIT-compilation for high-throughput training. Finally, we provide systematic and standardized benchmarks across Gym-Locomotion, DeepMind Control Suite, and IsaacLab, offering a rigorous side-by-side comparison of diffusion-based methods and guidance for practitioners to choose proper algorithms based on the application. Our work establishes a clear foundation for understanding and algorithm design, a high-efficiency toolkit for future research in the field, and an algorithmic guideline for practitioners in generative models and robotics. Our code is available at https://github.com/typoverflow/flow-rl.
Discovering Implicit Large Language Model Alignment Objectives
Feb 17, 2026Large language model (LLM) alignment relies on complex reward signals that often obscure the specific behaviors being incentivized, creating critical risks of misalignment and reward hacking. Existing interpretation methods typically rely on pre-defined rubrics, risking the omission of "unknown unknowns", or fail to identify objectives that comprehensively cover and are causal to the model behavior. To address these limitations, we introduce Obj-Disco, a framework that automatically decomposes an alignment reward signal into a sparse, weighted combination of human-interpretable natural language objectives. Our approach utilizes an iterative greedy algorithm to analyze behavioral changes across training checkpoints, identifying and validating candidate objectives that best explain the residual reward signal. Extensive evaluations across diverse tasks, model sizes, and alignment algorithms demonstrate the framework's robustness. Experiments with popular open-source reward models show that the framework consistently captures > 90% of reward behavior, a finding further corroborated by human evaluation. Additionally, a case study on alignment with an open-source reward model reveals that Obj-Disco can successfully identify latent misaligned incentives that emerge alongside intended behaviors. Our work provides a crucial tool for uncovering the implicit objectives in LLM alignment, paving the way for more transparent and safer AI development.
ALMo: Interactive Aim-Limit-Defined, Multi-Objective System for Personalized High-Dose-Rate Brachytherapy Treatment Planning and Visualization for Cervical Cancer
Feb 14, 2026In complex clinical decision-making, clinicians must often track a variety of competing metrics defined by aim (ideal) and limit (strict) thresholds. Sifting through these high-dimensional tradeoffs to infer the optimal patient-specific strategy is cognitively demanding and historically prone to variability. In this paper, we address this challenge within the context of High-Dose-Rate (HDR) brachytherapy for cervical cancer, where planning requires strictly managing radiation hot spots while balancing tumor coverage against organ sparing. We present ALMo (Aim-Limit-defined Multi-Objective system), an interactive decision support system designed to infer and operationalize clinician intent. ALMo employs a novel optimization framework that minimizes manual input through automated parameter setup and enables flexible control over toxicity risks. Crucially, the system allows clinicians to navigate the Pareto surface of dosimetric tradeoffs by directly manipulating intuitive aim and limit values. In a retrospective evaluation of 25 clinical cases, ALMo generated treatment plans that consistently met or exceeded manual planning quality, with 65% of cases demonstrating dosimetric improvements. Furthermore, the system significantly enhanced efficiency, reducing average planning time to approximately 17 minutes, compared to the conventional 30-60 minutes. While validated in brachytherapy, ALMo demonstrates a generalized framework for streamlining interaction in multi-criteria clinical decision-making.
MoSH: Modeling Multi-Objective Tradeoffs with Soft and Hard Bounds
Dec 09, 2024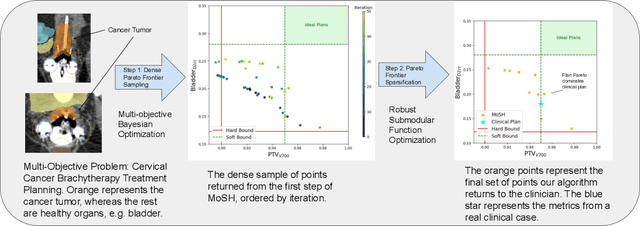
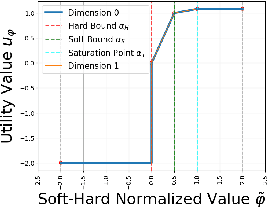
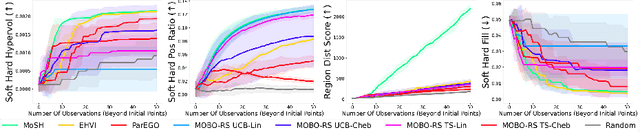
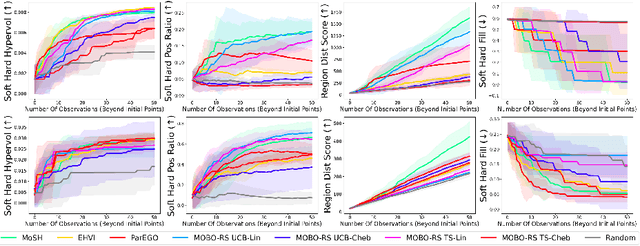
Countless science and engineering applications in multi-objective optimization (MOO) necessitate that decision-makers (DMs) select a Pareto-optimal solution which aligns with their preferences. Evaluating individual solutions is often expensive, necessitating cost-sensitive optimization techniques. Due to competing objectives, the space of trade-offs is also expansive -- thus, examining the full Pareto frontier may prove overwhelming to a DM. Such real-world settings generally have loosely-defined and context-specific desirable regions for each objective function that can aid in constraining the search over the Pareto frontier. We introduce a novel conceptual framework that operationalizes these priors using soft-hard functions, SHFs, which allow for the DM to intuitively impose soft and hard bounds on each objective -- which has been lacking in previous MOO frameworks. Leveraging a novel minimax formulation for Pareto frontier sampling, we propose a two-step process for obtaining a compact set of Pareto-optimal points which respect the user-defined soft and hard bounds: (1) densely sample the Pareto frontier using Bayesian optimization, and (2) sparsify the selected set to surface to the user, using robust submodular function optimization. We prove that (2) obtains the optimal compact Pareto-optimal set of points from (1). We further show that many practical problems fit within the SHF framework and provide extensive empirical validation on diverse domains, including brachytherapy, engineering design, and large language model personalization. Specifically, for brachytherapy, our approach returns a compact set of points with over 3% greater SHF-defined utility than the next best approach. Among the other diverse experiments, our approach consistently leads in utility, allowing the DM to reach >99% of their maximum possible desired utility within validation of 5 points.
Dynamic Model Agnostic Reliability Evaluation of Machine-Learning Methods Integrated in Instrumentation & Control Systems
Aug 08, 2023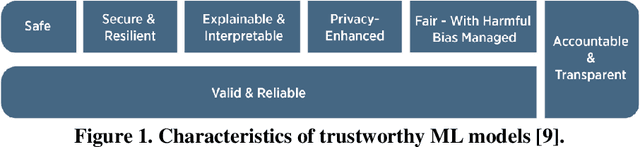



In recent years, the field of data-driven neural network-based machine learning (ML) algorithms has grown significantly and spurred research in its applicability to instrumentation and control systems. While they are promising in operational contexts, the trustworthiness of such algorithms is not adequately assessed. Failures of ML-integrated systems are poorly understood; the lack of comprehensive risk modeling can degrade the trustworthiness of these systems. In recent reports by the National Institute for Standards and Technology, trustworthiness in ML is a critical barrier to adoption and will play a vital role in intelligent systems' safe and accountable operation. Thus, in this work, we demonstrate a real-time model-agnostic method to evaluate the relative reliability of ML predictions by incorporating out-of-distribution detection on the training dataset. It is well documented that ML algorithms excel at interpolation (or near-interpolation) tasks but significantly degrade at extrapolation. This occurs when new samples are "far" from training samples. The method, referred to as the Laplacian distributed decay for reliability (LADDR), determines the difference between the operational and training datasets, which is used to calculate a prediction's relative reliability. LADDR is demonstrated on a feedforward neural network-based model used to predict safety significant factors during different loss-of-flow transients. LADDR is intended as a "data supervisor" and determines the appropriateness of well-trained ML models in the context of operational conditions. Ultimately, LADDR illustrates how training data can be used as evidence to support the trustworthiness of ML predictions when utilized for conventional interpolation tasks.
Advanced Transient Diagnostic with Ensemble Digital Twin Modeling
May 23, 2022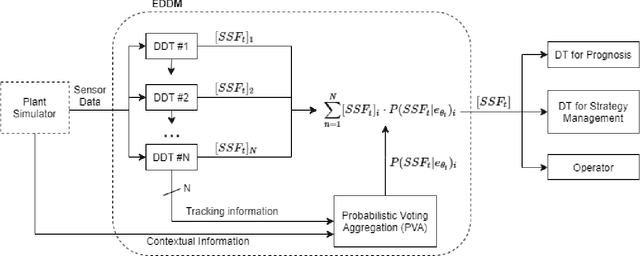


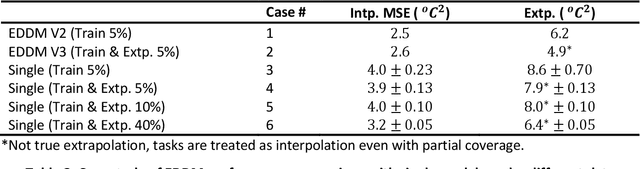
The use of machine learning (ML) model as digital-twins for reduced-order-modeling (ROM) in lieu of system codes has grown traction over the past few years. However, due to the complex and non-linear nature of nuclear reactor transients as well as the large range of tasks required, it is infeasible for a single ML model to generalize across all tasks. In this paper, we incorporate issue specific digital-twin ML models with ensembles to enhance the prediction outcome. The ensemble also utilizes an indirect probabilistic tracking method of surrogate state variables to produce accurate predictions of unobservable safety goals. The unique method named Ensemble Diagnostic Digital-twin Modeling (EDDM) can select not only the most appropriate predictions from the incorporated diagnostic digital-twin models but can also reduce generalization error associated with training as opposed to single models.
The Role of Pleura and Adipose in Lung Ultrasound AI
Jan 19, 2022In this paper, we study the significance of the pleura and adipose tissue in lung ultrasound AI analysis. We highlight their more prominent appearance when using high-frequency linear (HFL) instead of curvilinear ultrasound probes, showing HFL reveals better pleura detail. We compare the diagnostic utility of the pleura and adipose tissue using an HFL ultrasound probe. Masking the adipose tissue during training and inference (while retaining the pleural line and Merlin's space artifacts such as A-lines and B-lines) improved the AI model's diagnostic accuracy.
* Published in MICCAI 2021 workshop on Lessons Learned from the development and application of medical imaging-based AI technologies for combating COVID-19 (LL-COVID19). The first two authors contributed equally to this work
Weakly- and Semi-Supervised Probabilistic Segmentation and Quantification of Ultrasound Needle-Reverberation Artifacts to Allow Better AI Understanding of Tissue Beneath Needles
Nov 24, 2020
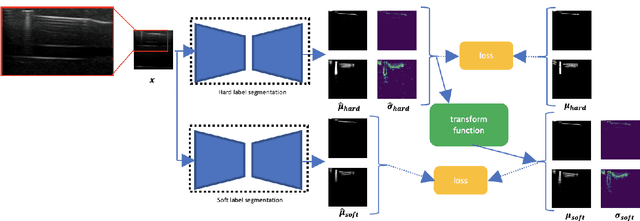

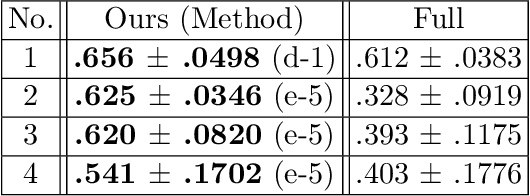
Ultrasound image quality has been continually improving. However, when needles or other metallic objects are operating inside the tissue, the resulting reverberation artifacts can severely corrupt the surrounding image quality. Such effects are challenging for existing computer vision algorithms for medical image analysis. Needle reverberation artifacts can be hard to identify at times and affect various pixel values to different degrees. The boundaries of such artifacts are ambiguous, leading to disagreement among human experts labeling the artifacts. We purpose a weakly- and semi-supervised, probabilistic needle-and-needle-artifact segmentation algorithm to separate the desired tissue-based pixel values from the superimposed artifacts. Our method models the intensity decay of artifact intensities and is designed to minimize the human labeling error. We demonstrate the applicability of the approach, comparing it against other segmentation algorithms. Our method is capable of differentiating the reverberations from artifact-free patches between reverberations, as well as modeling the intensity fall-off in the artifacts. Our method matches state-of-the-art artifact segmentation performance, and sets a new standard in estimating the per-pixel contributions of artifact vs underlying anatomy, especially in the immediately adjacent regions between reverberation lines.
A Study of Domain Generalization on Ultrasound-based Multi-Class Segmentation of Arteries, Veins, Ligaments, and Nerves Using Transfer Learning
Nov 13, 2020
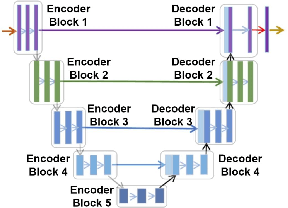
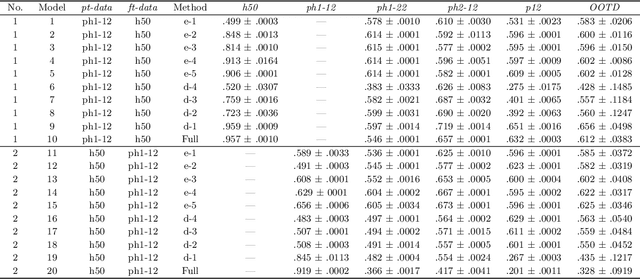
Identifying landmarks in the femoral area is crucial for ultrasound (US) -based robot-guided catheter insertion, and their presentation varies when imaged with different scanners. As such, the performance of past deep learning-based approaches is also narrowly limited to the training data distribution; this can be circumvented by fine-tuning all or part of the model, yet the effects of fine-tuning are seldom discussed. In this work, we study the US-based segmentation of multiple classes through transfer learning by fine-tuning different contiguous blocks within the model, and evaluating on a gamut of US data from different scanners and settings. We propose a simple method for predicting generalization on unseen datasets and observe statistically significant differences between the fine-tuning methods while working towards domain generalization.
YouTube-8M Video Understanding Challenge Approach and Applications
Jun 26, 2017This paper introduces the YouTube-8M Video Understanding Challenge hosted as a Kaggle competition and also describes my approach to experimenting with various models. For each of my experiments, I provide the score result as well as possible improvements to be made. Towards the end of the paper, I discuss the various ensemble learning techniques that I applied on the dataset which significantly boosted my overall competition score. At last, I discuss the exciting future of video understanding research and also the many applications that such research could significantly improve.