 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamerAD: Efficient Reinforcement Learning via Latent World Model for Autonomous Driving
Mar 25, 2026We introduce DreamerAD, the first latent world model framework that enables efficient reinforcement learning for autonomous driving by compressing diffusion sampling from 100 steps to 1 - achieving 80x speedup while maintaining visual interpretability. Training RL policies on real-world driving data incurs prohibitive costs and safety risks. While existing pixel-level diffusion world models enable safe imagination-based training, they suffer from multi-step diffusion inference latency (2s/frame) that prevents high-frequency RL interaction. Our approach leverages denoised latent features from video generation models through three key mechanisms: (1) shortcut forcing that reduces sampling complexity via recursive multi-resolution step compression, (2) an autoregressive dense reward model operating directly on latent representations for fine-grained credit assignment, and (3) Gaussian vocabulary sampling for GRPO that constrains exploration to physically plausible trajectories. DreamerAD achieves 87.7 EPDMS on NavSim v2, establishing state-of-the-art performance and demonstrating that latent-space RL is effective for autonomous driving.
Edge AI Inference in ISCC Networks: Sensing Accuracy Analysis and Precoding Design
Jan 01, 2026This work explores the relationship between sensing accuracy and precoding coefficients for edge artificial intelligence (AI) inference in integrated sensing, communication and computation (ISCC) networks. We start by constructing a system model of an over-the-air-empowered ISCC network for edge AI inference, involving distributed edge sensors for feature extraction and an edge server for classification. Based on this model, we introduce a discriminant gain (DG) to characterize sensing accuracy and novelly derive an explicit function of the DG about precoding coefficients, giving valuable insights into precoding design. Guided by this, we propose an effective precoding algorithm to solve a non-convex DG-maximization problem. Simulation results verify the effectiveness and feasibility of the proposed design for edge inference in ISCC networks.
CrayonRobo: Object-Centric Prompt-Driven Vision-Language-Action Model for Robotic Manipulation
May 04, 2025In robotic, task goals can be conveyed through various modalities, such as language, goal images, and goal videos. However, natural language can be ambiguous, while images or videos may offer overly detailed specifications. To tackle these challenges, we introduce CrayonRobo that leverages comprehensive multi-modal prompts that explicitly convey both low-level actions and high-level planning in a simple manner. Specifically, for each key-frame in the task sequence, our method allows for manual or automatic generation of simple and expressive 2D visual prompts overlaid on RGB images. These prompts represent the required task goals, such as the end-effector pose and the desired movement direction after contact. We develop a training strategy that enables the model to interpret these visual-language prompts and predict the corresponding contact poses and movement directions in SE(3) space. Furthermore, by sequentially executing all key-frame steps, the model can complete long-horizon tasks. This approach not only helps the model explicitly understand the task objectives but also enhances its robustness on unseen tasks by providing easily interpretable prompts. We evaluate our method in both simulated and real-world environments, demonstrating its robust manipulation capabilities.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025


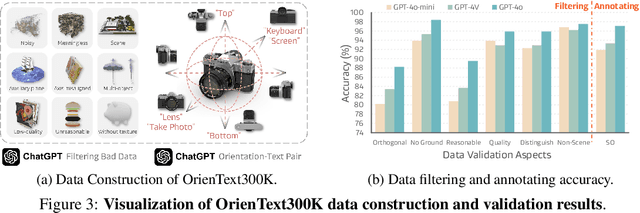
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
Synergizing Covert Transmission and mmWave ISAC for Secure IoT Systems
Feb 17, 2025



This work focuses on the synergy of physical layer covert transmission and millimeter wave (mmWave) integrated sensing and communication (ISAC) to improve the performance, and enable secure internet of things (IoT) systems. Specifically, we employ a physical layer covert transmission as a prism, which can achieve simultaneously transmitting confidential signals to a covert communication user equipment (UE) in the presence of a warden and regular communication UEs. We design the transmit beamforming to guarantee information transmission security, communication quality-of-service (QoS) and sensing accuracy. By considering two different beamforming architectures, i.e., fully digital beamforming (FDBF) and hybrid beamforming (HBF), an optimal design method and a low-cost beamforming scheme are proposed to address the corresponding problems, respectively. Numerical simulations validate the effectiveness and superiority of the proposed FDBF/HBF algorithms compared with traditional algorithms in terms of information transmission security, communication QoS and target detection performance.
Exploiting Target Location Distribution in MIMO Radar: PCRB vs. PSBP for Waveform Design
Jul 27, 2024



This paper investigates the issue of how to exploit target location distribution for multiple input multiple output (MIMO) radar waveform design. We consider a MIMO radar aiming to estimate the unknown and random angular location parameters of a point target, whose distribution information can be exploited by the radar. First, we establish the models of the MIMO radar system and the target location distribution. Based on the considered models, we propose the first category of target location distribution exploitation methods by analyzing the radar direction-of-angle (DoA) estimation performance and deriving a general form of posterior Cramer-Rao bound (PCRB) as the lower bound of the mean square error of DoA estimation. Following this, to explore more insights, we proposed the second category of target location distribution exploitation methods by introducing a novel radar metric, probability scaled beampattern (PSBP), from the perspective of radar beampattern. To compare the two methods, we formulate the PCRB and PSBP oriented radar waveform design problems and propose corresponding low-complexity and convergence-guaranteed algorithms to tackle them. Finally, numerical simulations are conducted in different scenarios to provide a comprehensive evaluation and comparison of the radar performance.
General Place Recognition Survey: Towards Real-World Autonomy
May 08, 2024



In the realm of robotics, the quest for achieving real-world autonomy, capable of executing large-scale and long-term operations, has positioned place recognition (PR) as a cornerstone technology. Despite the PR community's remarkable strides over the past two decades, garnering attention from fields like computer vision and robotics, the development of PR methods that sufficiently support real-world robotic systems remains a challenge. This paper aims to bridge this gap by highlighting the crucial role of PR within the framework of Simultaneous Localization and Mapping (SLAM) 2.0. This new phase in robotic navigation calls for scalable, adaptable, and efficient PR solutions by integrating advanced artificial intelligence (AI) technologies. For this goal, we provide a comprehensive review of the current state-of-the-art (SOTA) advancements in PR, alongside the remaining challenges, and underscore its broad applications in robotics. This paper begins with an exploration of PR's formulation and key research challenges. We extensively review literature, focusing on related methods on place representation and solutions to various PR challenges. Applications showcasing PR's potential in robotics, key PR datasets, and open-source libraries are discussed. We also emphasizes our open-source package, aimed at new development and benchmark for general PR. We conclude with a discussion on PR's future directions, accompanied by a summary of the literature covered and access to our open-source library, available to the robotics community at: https://github.com/MetaSLAM/GPRS.
Task-Oriented Hybrid Beamforming for OFDM-DFRC Systems with Flexibly Controlled Space-Frequency Spectra
Mar 18, 2024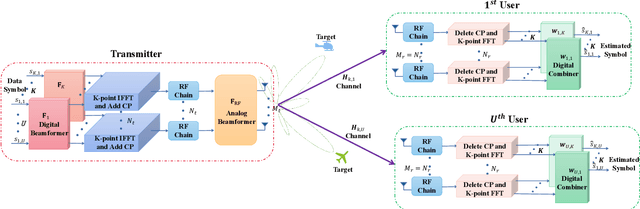

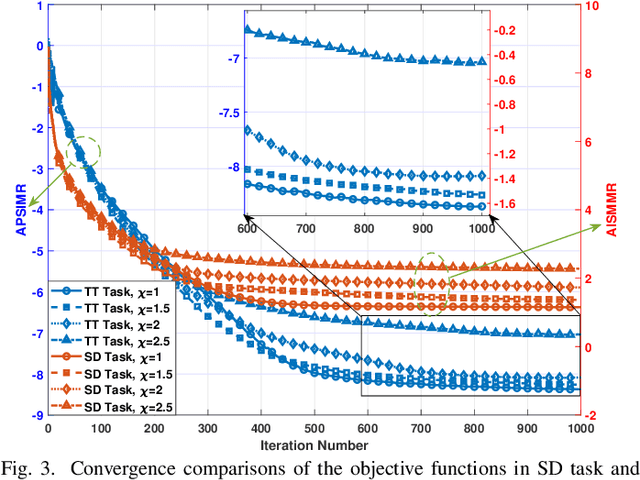
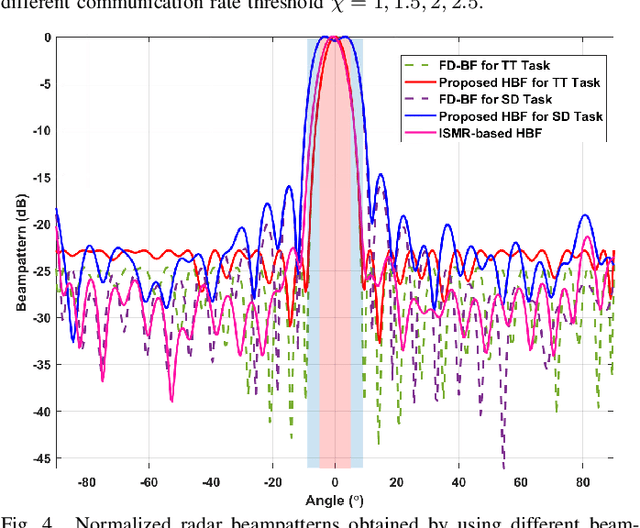
This paper investigates the issues of the hybrid beamforming design for the orthogonal frequency division multiplexing dual-function radar-communication (DFRC) system in multiple task scenarios involving the radar scanning and detection task and the target tracking task. To meet different task requirements of the DFRC system, we introduce two novel radar beampattern metrics, the average integrated sidelobe to minimum mainlobe ratio (AISMMR) and average peak sidelobe to integrated mainlobe ratio (APSIMR), to characterize the space-frequency spectra in different scenarios. Then, two HBF design problems are formulated for two task scenarios by minimizing the AISMMR and APSIMR respectively subject to the constraints of communication quality-of-service (QoS), power budget, and hardware. Due to the non-linearity and close coupling between the analog and digital beamformers in both the objective functions and QoS constraint, the resultant formulated problems are challenging to solve. Towards that end, a unified optimization algorithm based on a consensus alternating direction method of multipliers (CADMM) is proposed to solve these two problems. Moreover, under the unified CADMM framework, the closed-form solutions of primal variables in the original two problems are obtained with low complexity. Numerical simulations are provided to demonstrate the feasibility and effectiveness of the proposed algorithm.
Enhancing Physical Layer Security in Dual-Function Radar-Communication Systems with Hybrid Beamforming Architecture
Mar 12, 2024


In this letter, we investigate enhancing the physical layer security (PLS) for the dual-function radar-communication (DFRC) system with hybrid beamforming (HBF) architecture, where the base station (BS) achieves downlink communication and radar target detection simultaneously. We consider an eavesdropper intercepting the information transmitted from the BS to the downlink communication users with imperfectly known channel state information. Additionally, the location of the radar target is also imperfectly known by the BS. To enhance PLS in the considered DFRC system, we propose a novel HBF architecture, which introduces a new integrated sensing and security (I2S) symbol. The secure HBF design problem for DFRC is formulated by maximizing the minimum legitimate user communication rate subject to radar interference-plus-noise ratio, eavesdropping rate, hardware and power constraints. To solve this non-convex problem, we propose an alternating optimization based method to jointly optimize transmit and receive beamformers. Numerical simulation results validate the effectiveness of the proposed algorithm and show the superiority of the proposed I2S-aided HBF architecture for achieving DFRC and enhancing PLS.
Temporal Point Cloud Completion with Pose Disturbance
Feb 07, 2022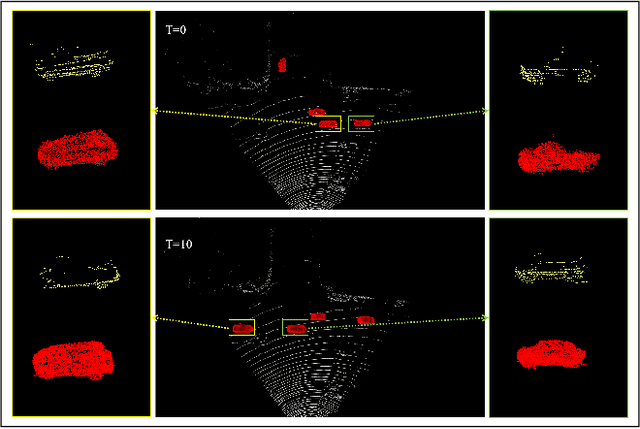
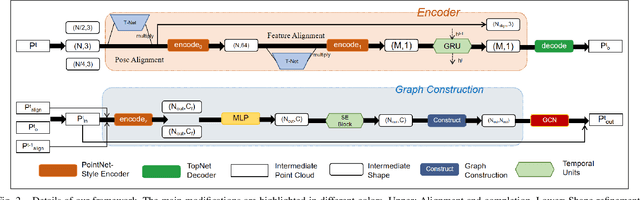
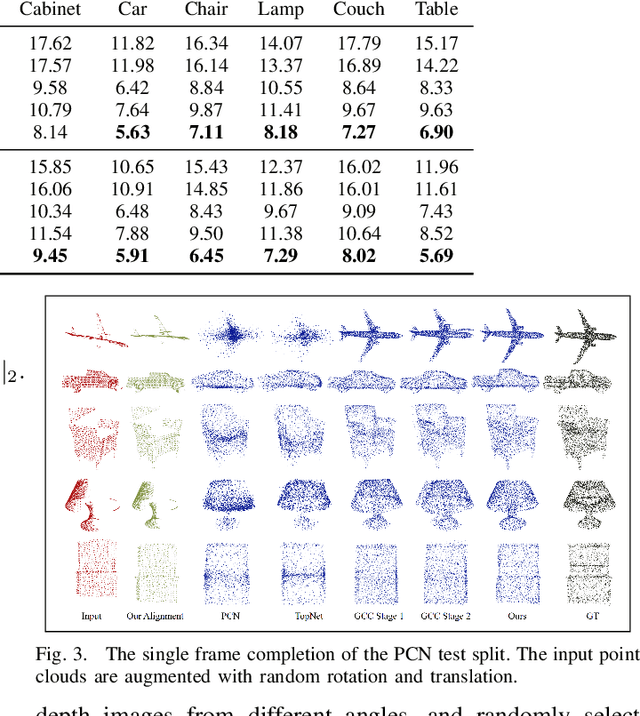
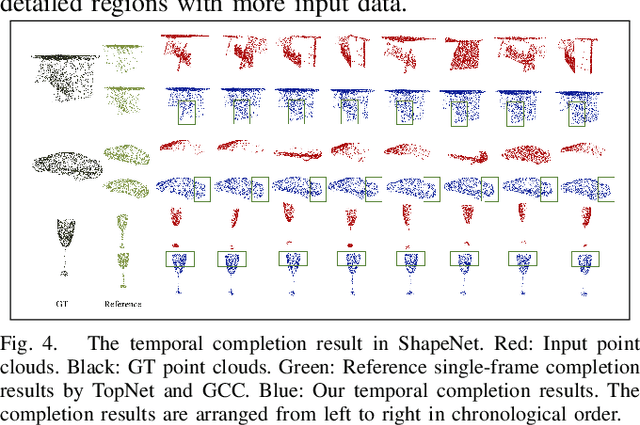
Point clouds collected by real-world sensors are always unaligned and sparse, which makes it hard to reconstruct the complete shape of object from a single frame of data. In this work, we manage to provide complete point clouds from sparse input with pose disturbance by limited translation and rotation. We also use temporal information to enhance the completion model, refining the output with a sequence of inputs. With the help of gated recovery units(GRU) and attention mechanisms as temporal units, we propose a point cloud completion framework that accepts a sequence of unaligned and sparse inputs, and outputs consistent and aligned point clouds. Our network performs in an online manner and presents a refined point cloud for each frame, which enables it to be integrated into any SLAM or reconstruction pipeline. As far as we know, our framework is the first to utilize temporal information and ensure temporal consistency with limited transformation. Through experiments in ShapeNet and KITTI, we prove that our framework is effective in both synthetic and real-world datasets.